深度学习总结(lecture 6)VGG13、16、19
lecture 6:VGG13、16、19
目录
- lecture 6:VGG13、16、19
- 目录
- 1、VGG结构
- 2、VGG结构解释
- 3、3*3卷积核的优点
- 4、VGG的 Multi-Scale方法
- 5、VGG应用
1、VGG结构


LeNet5用大的卷积核来获取图像的相似特征
AlexNet用9*9、11*11的滤波器
VGG 巨大的进展是通过依次采用多个 3×3 卷积,模仿出更大的感受野(receptive field)效果,例如 5×5 与 7×7。
这些思想也被用在更多的网络架构中,如 Inception 与 ResNet。
VGG16的效果最好


- VGG16 的第 3、4、5 块(block):256、512、512个 3×3 滤波器依次用来提取复杂的特征。
- 其效果就等于是一个带有 3 个卷积层的大型的 512×512 大分类器。
2、VGG结构解释
(1)VGG全部使用3*3卷积核、2*2池化核,不断加深网络结构来提升性能。
(2)A到E网络变深,参数量没有增长很多,参数量主要在3个全连接层。
(3)训练比较耗时的依然是卷积层,因计算量比较大。
(4)VGG有5段卷积,每段有2~3个卷积层,每段尾部用池化来缩小图片尺寸。
(5)每段内卷积核数一样,越靠后的段卷积核数越多:64–128–256–512–512。
3、3*3卷积核的优点
(1)多个一样的3*3的卷积层堆叠非常有用
(2)两个3*3的卷积层串联相当于1个5*5的卷积层,即一个像素会跟周围5*5的像素产生关联,感受野大小为5*5。
(3)三个3*3的卷积层串联相当于1个7*7的卷积层,但3个串联的3*3的卷积层有更少的参数量,有更多的非线性变换(3次ReLU激活函数),使得CNN对特征的学习能力更强。

两个3*3的卷积层串联相当于1个5*5的卷积层
4、VGG的 Multi-Scale方法

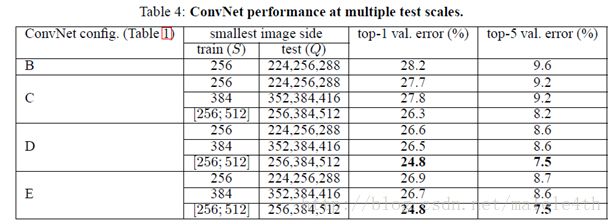
- LRN层作用不大。
越深的网络效果越好。
1*1的卷积也是很有效的,但是没有3*3的卷积好
大的卷积核可以学习更大的空间特征
5、VGG应用
VGG9、VGG11、VGG13、VGG16、VGG19
出现了梯度消失的问题
只在第一个卷积(name=’block1_conv1’)后面加了BatchNormalization就解决了
def VGG16(input_shape=(64,64,3), classes=6):
X_input = Input(input_shape)
"block 1"
X = Conv2D(filters=4, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block1_conv1')(X_input)
X = BatchNormalization(axis=3)(X)
X = Conv2D(filters=4, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block1_conv2')(X)
X = MaxPooling2D((2,2), strides=(2,2), name='block1_pool')(X)
"block 2"
X = Conv2D(filters=8, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block2_conv1')(X)
X = BatchNormalization(axis=3)(X)
X = Conv2D(filters=8, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block2_conv2')(X)
X = MaxPooling2D((2,2), strides=(2,2), name='block2_pool')(X)
"block 3"
X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv1')(X)
X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv2')(X)
X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv3')(X)
X = MaxPooling2D((2,2), strides=(2,2), name='block3_pool')(X)
"block 4"
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv1')(X)
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv2')(X)
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv3')(X)
X = MaxPooling2D((2,2), strides=(2,2), name='block4_pool')(X)
"block 5"
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv1')(X)
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv2')(X)
X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv3')(X)
X = MaxPooling2D((2,2), strides=(2,2), name='block5_pool')(X)
"flatten, fc1, fc2, fc3"
X = Flatten(name='flatten')(X)
X = Dense(256, activation='relu', name='fc1')(X)
X = Dense(256, activation='relu', name='fc2')(X)
X = Dense(classes, activation='softmax', name='fc3')(X)
model = Model(inputs=X_input, outputs=X, name='VGG16')
return model