迁移学习系列 - 有->有监督迁移
一.Model fine-tuning方式
1.Model fine-tuning模型是应对于源数据和目标数据都是有标签、且有大量源数据、少量目标数据的情况。
最典型的例子是之前做狗种类识别竞赛时,用到的迁移方法,针对于训练集中每个狗只有100张左右训练图像的问题,我们使用的方法是:
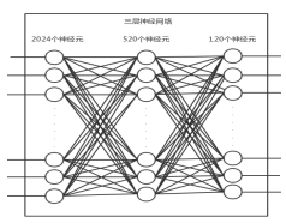
[1]使用别人训练好的用于1024个物种分类(相似域、不同任务)的Resnet网络,用于对目标数据进行特征提取。
[2]使用提取到的1024个高级特征,利用训练数据集去训练一个三层的神经网络,最后输出120个种类,从而做到物种分类的效果。
2.上面举的例子应该算是一种比较改进的Model fine-tuning方法,我们先从最基本形式开始介绍。
*最基本的方法是直接将源场景训练好的模型直接拿过来使用,将模型参数都拿过来使用新数据集进行训练,如直接使用ImageNet进行resnet网络的训练,之后在自己的狗种类识别图片上进行狗种类的预测,这种迁移方式会修改resnet网络的参数。
*但是这种方式有个问题是源场景训练出来的模型有很强的泛化能力,现在拿这个泛化能力很强的模型针对于当前的目标模型进行训练(小量调优)很容易过拟合,这是因为在训练中会修改模型中的大量参数值,这样原模型的泛化能力会受到很大的影响。
*为了改进上面的问题,我们会对训练过程中参数的修改进行限制,限制方式包括对网络参数的限制、对输出结果的限制,限制改变量,令两模型的参数进行接近。
*限制实现的思路是对loss函数进行改造,如对参数进行限制时,可以使用下面的式子来对loss函数进行改造:
![]()
这样就可以类似于正则化的方法,对损失函数后面添加二范式式子来对优化目标进行限制,使得最后实现训练效果的同时,也能保障参数的接近性。
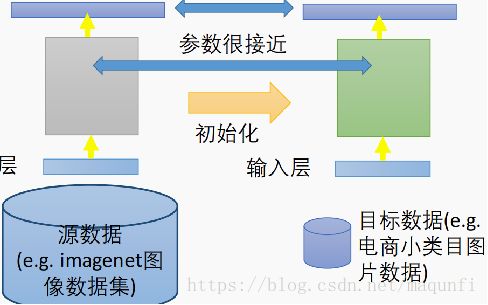
3.再往下改进是层迁移方式。
*层迁移是指将源场景训练好的模型,拿过来部分层参数拷贝到当前的网络中,让这部分层的参数的参数在新的网络中固定住,不进行改变,通过这种方式限制住参数里的变化量,防止目标场景训练时的过拟合。
*如下图的方式,我们将第1层到第2层、第3层到第4层、第4层到第5层之间的参数复制过来之后、限制住,只训练修改剩下网络的参数,不过如果目标场景有一定的数据量,有信心能克制过拟合的话,也可以将这些复制过来的进行微量的改变,如设置学习率为0.001。
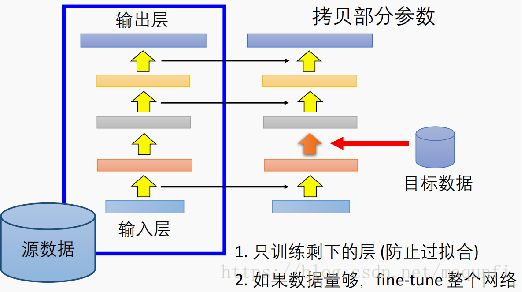
*实际中进行层迁移时,应该对那些层进行拷贝那? 对于不同的任务场景我们有不同的选择:
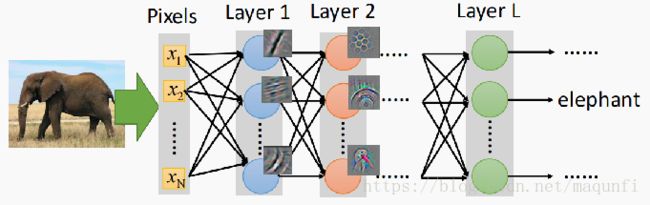
[1]对于图像识别任务,我们往往会迁移最开始的一些层,因为刚开始的层能够获取图像之间底层的公共特征(特征抽取器),之后可以在后面层进行再学习。
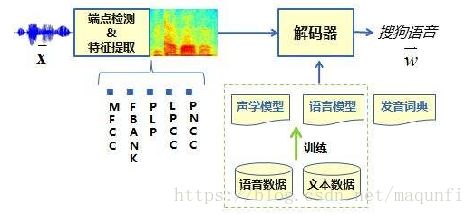
[2]对于语音识别任务,我们则会迁移最后面的一些层,因为语音中前面网络部分是将不同人说话方式抽象成音速、语音基本单元,而后面的网络是将音速组成要说的话,而后面部分将语速转成话的部分是语音识别中通用的。
二.Multitask learning方式
1.Multitask learning是一种将源场景和目标场景使用网络同时进行训练的形式,尽量使得公共网络部分能在任务A和任务B上都有不错的效果,这样会使得公共网络部分有泛化性(参数有共性,不会在任意任务形式中过拟合。
2.其有两种表示形式
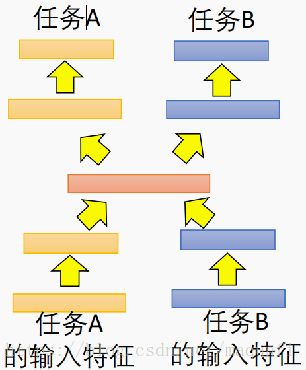
*一种常用的应用方式如下图,我们令两个任务的网络公用下面的三层,下面三层要使得在两个任务上都有比较好的效果,前面的三部分相当于抽取特征,后面两部分是针对特征进行分类,这样就能训练出具有提取公共特征的网络层结构,进行训练时我们会交替进行训练,在任务A网络上训练部分数据,之后也在任务B上训练一部分,由自己确定网络的定义形式参数共享或者使用参数拷贝方式)。

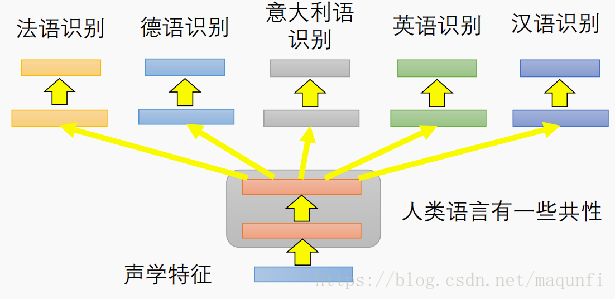
这种形式网络的一个典型应用是多语种语音识别,在语言模型中通过共享语言的前面的几层,来将人类语言的共性特征学习出来,之后再针对英语或者汉语进行针对性的识别训练,通过这种参数共享的模型形式,来提升目标场景语言的识别效果。
*下图的网络是另一种形式,可应对于两个场景的域差别的比较大(照相机找出的图和卡通画),我们在中间层进行表达的共享(相通的图像抽象),而在开头和尾部都依据自己的特点,执行各自的特征抽取(获取线条等)和分类,因为这是有差距的数据形态,所以不应该共享太多的层结构。
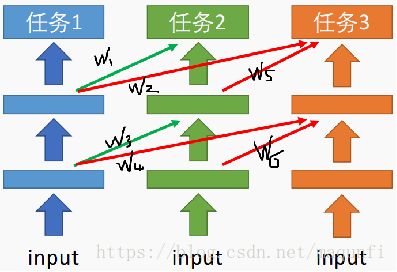
三.渐进式神经网络
渐进式神经网络是进行网络参数迁移的另一种形式,网络使用了类似于Resnet的思想,对要迁移过来的任务的网络参数进行选择,选择对源任务网络参数要或者不要。
1.首先我们先训练好第一个任务网络NN1,我们在对第二个任务训练时会借助NN1的参数来做补充,将NN1各层输出的信息融合到自己的网络训练中,在融合时利用参数w1、w3(0-1的数)来控制融合的比例,这种参数w1、w3是可以可选的,并可在任务2的训练中加以改变,能学习到之前任务的信息有没有用。

2.任务3进行训练时,会使用NN1、NN2的网络参数做补充,类似之前的原理,我们会通过对w2、w5、w4、w6的训练来设置补充的信息比例,通过对网络参数的学习控制可以更好的补充信息来提升模型效果。

3.中间通过学习融合了其他网络的层输出信息,可以看到准确率得分有明显的提升。