Redis Cluster集群搭建基于5.0.0
6.3 集群
Redis Cluster 作者建议的最大集群规模 1,000 节点,目前查找的资料当中大部分都使用第三方工具,优酷使用Redis Cluster:蓝鲸项目中管理了超过 700 台节点
6.3.1 安装
最小集群3节点master,3节点slave:端口7000~7005
cp redis.conf 7000.conf…
mkdir 7000 7001 7002 7003 7004 7005
修改配置文件7000.conf:
#bind 127.0.0.1
protected-mode no // 设置no,否则代码连接报错。
port 7000
daemonize yes
pidfile /home/redis-5.0.0/7000/redis_7000.pid
logfile "/home/redis-5.0.0/7000/redis_7000.log"
dir "/home/redis-5.0.0/7000"
appendonly yes
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
对应修改其他5个配置文件!!!
分别对应启动:
src/redis-server 7000/7000.conf
src/redis-server 7001/7001.conf
src/redis-server 7002/7002.conf
src/redis-server 7003/7003.conf
src/redis-server 7004/7004.conf
src/redis-server 7005/7005.conf
日志信息:

验证:任意连接一台输入info cluster
[root@dc5 redis-5.0.0]# src/redis-cli -p 7000
![]()
对于Redis版本3或4:
使用redis-trib.rb脚本,进行集群安装配置初始化,先安装ruby。
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
对于redis5:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
注:
报错:Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.ConnectException: Connection refused: connect原因:使用127.0.0.1创建集群,连接的时候,也只能用127.0.0.1,所以创建时候使用ip地址!
同时因为测试
其中–replicas 1标识每个主数据库拥有1个从数据库,整体3master-3slave结构。
![]()
连接任意一台输入,查看节点情况:
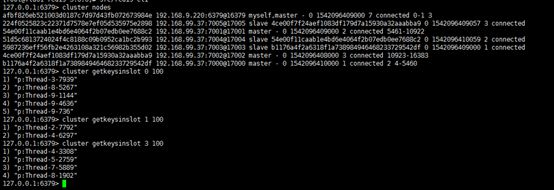
127.0.0.1:6379> cluster nodes

查看slots分配情况:cluster slots
6.3.2 Master节点增加
集群使用Gossip协议将新节点通知给集群中每一个节点。
设置cluster-enable yes
启动:src/redis-server redis.conf
添加:redis-cli:cluster meet 192.168.99.37 7000 (ip和port任意一台均可)
添加后角色为master:

6.3.3 Slave节点增加
在192.168.9.220三个端口启动三个节点,6379添加为master,800*作为它的slave,一master两slave结构:

将8000端口节点添加:
[root@flu01 redis-5.0.0]# src/redis-cli --cluster add-node 192.168.9.220:8000 192.168.9.220:6379 --cluster-slave
日志:
>>> Configure node as replica of 192.168.9.220:6379.
[OK] New node added correctly.
查询下:

将8001端口节点添加:
[root@flu01 redis-5.0.0]# src/redis-cli --cluster add-node 192.168.9.220:8001 192.168.9.220:6379 --cluster-slave

6.3.4 删除节点
需要先清空slot
如当前192.168.9.220:6379master有三个slot:0 、1、3,同时有2个slave

先清空slot,将slot移动到192.168.99.37:7003节点上:
[root@dc5 redis-5.0.0]# src/redis-cli --cluster reshard 192.168.99.37:7003
移动3个slot,总共也就3个slot
![]()
Done之后开始移动:
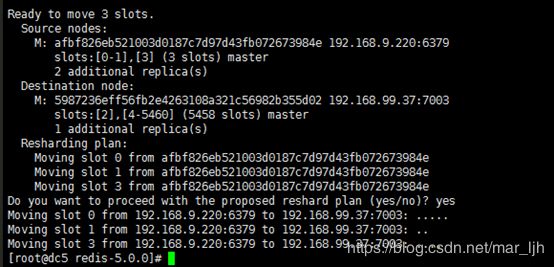
移动之后节点slave情况:来源节点的slave全部都被转移挂载到接收节点上了!
然后执行删除:
命令格式:redis-cli –cluster del-node host:port nodeID
[root@dc5 redis-5.0.0]# src/redis-cli --cluster del-node 192.168.9.220:6379 afbf826eb521003d0187c7d97d43fb072673984e
删除成功信息:

6.3.5 Slot分配
有效键名的有效部分使用CRC16算法计算出散列值,然后取16384余数。
有效键名:
- key中有{},则有效键名为{}中间部分;
- 不满足1,则整个键名
利用这一特性,可以将key分配到统一slot中,以支持类型Mget命令(该命令涉及多个键,只有键位于同一节点,才能正常支持)
具体分配:
指定slot分配到新节点,前提是slot未分配:
在新节点上执行redis-cli> cluster addslots 100 101 分配100,101slot到当前新节点,如果已经分配过,则报错:
(error) ERR Slot 100 is already busy
换下面的方式:
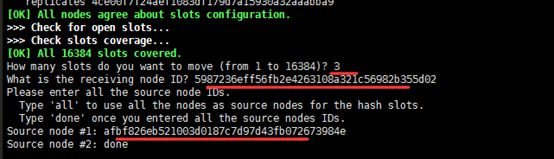
集群中任一节点:src/redis-cli --cluster reshard host:ip(新节点的ip)
具体如下:
src/redis-cli --cluster reshard 192.168.9.220:6379
How many slots do you want to move (from 1 to 16384)? 1 #需要分配多个slot到220主机,这里输入1表示分配1个。
What is the receiving node ID? afbf826eb521003d0187c7d97d43fb072673984e
#slot分配给节点对应的id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
# 这里输入all,slot的来源主机,all表示从所以机器里面提供slot,或者直接输入对应的提供主机的id,然后输入done结束。
最后输入yes,然后提示:
Moving slot 5461 from 192.168.99.37:7001 to 192.168.9.220:6379
如果要把slot还回去,执行:
Redis-cli:
cluster setslot 5461 node 54e00f11caab1e4bd6e4064f2b07edb0ee7688c2
之后再次分配可能提供16384slot没有完全覆盖,而报错:
src/redis-cli --cluster check 192.168.9.220 6379 #检查报错
src/redis-cli --cluster fix 192.168.9.220:6379 #修复报错
重新再次分配:
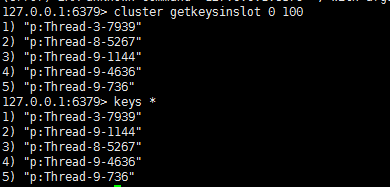
先看下slot 0,有多少数据:
127.0.0.1:7000> cluster getkeysinslot 0 100
1) "p:Thread-3-7939"
2) "p:Thread-8-5267"
3) "p:Thread-9-1144"
4) "p:Thread-9-4636"
5) "p:Thread-9-736"
这里总共5条记录。
分配slot 0到220主机:
src/redis-cli --cluster reshard 192.168.9.220 6379
返回结果:
查看下slot对应下键值,是否也一并过来:
5.0版本实际测试,当移动slot,slot对应的记录也一并被移动走了。老版本的话,可以需要手动移动值:
先查看slot有多少记录
Redis-cli:Cluster getkeysinslot 插槽号 要返回的键数量
之后对每个键使用migrate命令迁移到目标节点:
Redis-cli:Migrate 目标节点地址 目标端口 键名 数据库号码 超时时间 [COPY][REPLACE]
copy表示不删除当前移除的键,而是复制一份到目标;
Replace表示如果目标节点下有对应键,则覆盖。
数据库号码,默认是0.
6.3.6 迁移指定slot
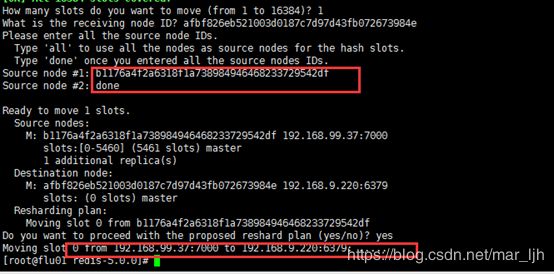
需求:将slot 3从old:7000主机,迁移到new:6379主机,迁移的同时集群不下线。
当前slot分配情况:cluster nodes(cluster slots)

在old上查看slot拥有的key数量:
127.0.0.1:7000> cluster getkeysinslot 3 100
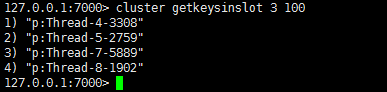
在new上执行:
1)cluster setslot 3 importing b1176a4f2a6318f1a738984946468233729542df
![]()
查看slot变化:slot 3在new上有了,同时old节点也依然存在
![]()
在old上执行:
2)cluster setslot 3 migrating afbf826eb521003d0187c7d97d43fb072673984e

3)查看old节点上slot 3拥有的key:
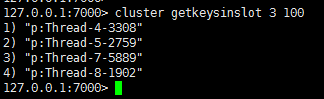
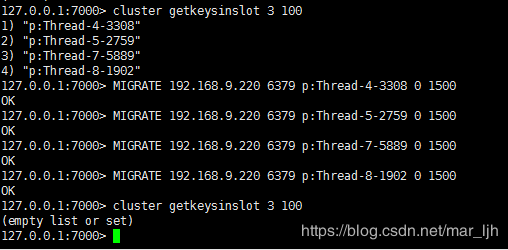
4)Old上开始迁移key:
MIGRATE 192.168.9.220 6379 p:Thread-4-3308 0 1500
![]()
New节点上查看到数据:
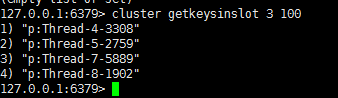
5)最后执行完成迁移:
cluster setslot 3 node afbf826eb521003d0187c7d97d43fb072673984e

6)…弄到这里心态有点崩了,看到上面slot带箭头类似快捷方式的那种……
这里直接使用:
src/redis-cli --cluster fix 127.0.0.1 6379
好了,数据也过来了~
6.3.7 获取与slot对应节点
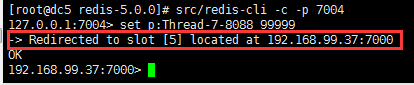
127.0.0.1:7001> set p:Thread-7-8088 99
![]()
会返回一个move重定向请求,值在这个时候并没有插入进去!
开启自动重定向:-c 开启
src/redis-cli -c -p 7004
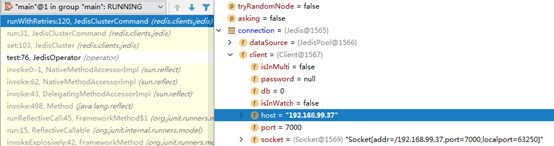
jedisCluster内部做封装,会根据key先判断slot,源码:
redis.clients.jedis.JedisClusterCommand
private T runWithRetries(byte[] key, int attempts, boolean tryRandomNode, boolean asking) {
if (attempts <= 0) {
throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?");
}
Jedis connection = null;
try {
if (asking) {
// TODO: Pipeline asking with the original command to make it
// faster....
connection = askConnection.get();
connection.asking();
// if asking success, reset asking flag
asking = false;
} else {
if (tryRandomNode) {
connection = connectionHandler.getConnection();
} else {
// 关键代码
connection = connectionHandler.getConnectionFromSlot(JedisClusterCRC16.getSlot(key));
}
}
return execute(connection);
计算key slot算法:
redis.clients.util.JedisClusterCRC16
public static int getSlot(byte[] key) {
int s = -1;
int e = -1;
boolean sFound = false;
for (int i = 0; i < key.length; i++) {
if (key[i] == '{' && !sFound) { // 如有有成对{},则有效key为{}内部
s = i;
sFound = true;
}
if (key[i] == '}' && sFound) {
e = i;
break;
}
}
if (s > -1 && e > -1 && e != s + 1) {
return getCRC16(key, s + 1, e) & (16384 - 1);
}
return getCRC16(key) & (16384 - 1);
}
调式信息:
6.3.8 故障恢复
算法同哨兵,基于raft算法。

7000 shutdown后,7003被选举成master

slave冗余下的故障恢复:
当一主一从节点都宕机,只要不是同时,那么其他master有多个slave的节点,会自动顶替过来。
如当前集群:
master7001->slave7004,
master7002->slave7005,
master7003->slave {7000, 8000, 8001}
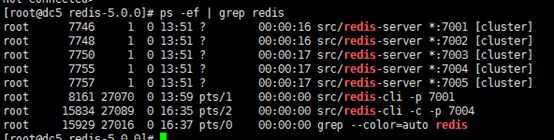
Kill 7004节点:kill掉7001的slave:8000节点顶替过去了……

Kill 7001:kill掉master:8000节点由slave变master,同时7000变slave

此时整体集群结构:
Master8000->slave7000,
master7002->slave7005,
master7003->slave 8001
再kill 8000:kill掉新晋级的master:那么7000晋级master

现在结构已经不满足一主一从:
此时整体集群结构:
Master7000,
master7002->slave7005,
master7003->slave 8001
再kill 7000: 集群就丢slot了

在集群内删除节点:
127.0.0.1:7002> cluster forget e85be869a9375687627d47907928b8c46a005c72
NOTE:因博客写的比较早,后期贴到CSDN,部分图片可能会乱,如有问题,欢迎提出~