YOLOv2目标检测详解
前言:
原论文网址:《YOLO9000: Better, Faster, Stronger》 项目地址:http://pjreddie.com/darknet/yolo/
原论文中其实讲了两个部分:
一,YOLOv1如何优化成YOLOv2的,以及YOLOv2的一些详细介绍。
二,YOLO9000的介绍,这个是基于YOLOv2结构的9000多类目标的检测。
由于the large amount of classification 我们很少用到,所以本文就详细讲解第一部分。
关于网络:
YOLOv2用的是Darknet-19网络用于特征提取的。作者在论文中这样说到:其实很多检测框架都是依赖于VGG-16网络来提取特征的,VGG-16是一个强大的,准确率高的分类网络,但是它很复杂。看没看到,作者用了一个“但是”就把这个网络否定了,然后自己牛逼的提出了一个比它优秀的网络。作者继续补刀:仅一张分辨率为224*224的图片在单次传递的时候,VGG-16的卷积层就需要30.69 billion次浮点运算操作。看一张网络运算浮点操作的图就知道了,反正你知道VGG-16运算量很大就行了。
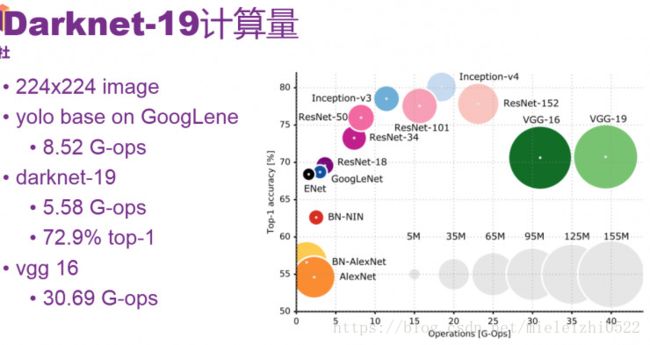
我解释一下,目标检测网络在训练之前都要用单独的网络来与提取特征,进行预训练,然后特征提取之后再在后面加上自己的创造的目标检测网络(一系列卷积层等),完成目标检测。之前的YOLOv1用的特征提取网络是GoogLeNed的改进版本,图上可以看到,计算量是8.52G-ops,top-5准确率是88.0%,VGG-16网络top-5准确率是90.0%(30.69G-ops),而,注意啦!Darknet-19网络计算量是5.58G-ops,top-5准确率高达91.2%。看一下Darknet-19的结构:

再详细看一下在Darknet-19的基础上的YOLOv2网络结构:

YOLO2网络中第23层上面是Darknet-19网络,后面是添加的检测网络。
YOLO 2采用神经网络结构,有32层。结构比较常规,包含一些卷积和最大池化,其中有一些1*1卷积,采用GoogLeNet一些微观的结构。其中要留意的是,第25层和28层有一个route。例如第28层的route是27和24,即把27层和24层合并到一起输出到下一层,route层的作用是进行层的合并。30层输出的大小是13*13,是指把图片通过卷积或池化,最后缩小到一个13*13大小的格。每一个格子的output参数是125。所以最后输出的参数一共是13*13*125
关于YOLOv2 边框预测计算:
上面说了最后输出参数是13*13*125, 是因为一共有13*13个格子,每个格子预测出5个bounding box,每个bounding box预测25个数,其中20个是class的probability,其余5个参数中有四个表示stx、sty、tw、th,这4个来识别边框的位置和大小,还有1个数是confidence,表示边框预测里有真正的对象的概率,所以一共是13*13*125个数。接下来看一下四个参数stx、sty、tw、th,是如何预测框的位置的。
这里先介绍一个anchor boxes 概念,这个悲伤的故事来源于Faster RCNN,因为faster RCNN为了不让算法漫无目的的去猜测那些目标的边框大小,于是就自己预先在每个位置上产生一定长宽比例的方框,以减少搜索量,这个方框就叫做anchor boxes,anchor的意思是“锚”,“固定”的意思,大多数人是把这个解释为“锚”,不过我觉得解释成“固定”比较好,其实也有锚的意思,因为这个是相对于中心点来说的,就是在中心点的周围产生几个固定比例的边框,所以这个“中心点”就把这几个框给锚住了,他们共用一个中心点,(当然在YOLOv2中这个中心点是一个格子的大小,所以会在格子里微小移动)。
faster rcnn在每个位置上产生了9个不同长宽比例的anchor boxes ,这几种比例以及比例的种数作者认为不合理,是手动选出来的,虽然网络最终可以学出来,但如果我们可以给出更好的anchor,那么网络肯定更加容易训练而且效果更好。
于是作者灵光一闪,通过K-Means聚类的方式在训练集中聚出了好的anchor模板。经过分析,确定了anchor boxes的个数以及比例。如下图

上图的左边可以看出,有5中类型的长宽比例。后面预测出stx、sty、tw、th,四个参数,再根据上图右边的计算就可以计算出预测出的box大小了,注意!上图右边里面的σ(tx)可以理解为stx,σ(ty)可以理解为sty。每一个输出的bbox是针对于一个特定的anchor,anchor其实是bbox的width及height的一个参考。pw和ph是某个anchor box的宽和高,一个格子的Cx和Cy单位都是1,σ(tx),σ(ty)是相对于某个格子左上角的偏移量。
这个地方不是很好理解,我举个例子,比如说我预测出了stx、sty、tw、th四个参数分别是0.2,0.1,0.2,0.32,row:1,col:1假如anchor比例取:w:3.19275,h:4.00944,这其中row和col就是锚点相对于整个网格的偏移的格子数,在这个偏移量的基础上计算格子中心位置,
计算出:
bx=0.2+1=1.2
by=0.1+1=1.1
bw=3.19275*exp(0.2)=3.89963
bh=4.00944*exp(0.32)=5.52151
然后分别将这些归一化(同除以13),得:bx=0.09,by=0.08,bw=0.30,bh=0.42.具体是否要输出当前的边框,它的概率,还有生成的物体的类别,这个取决于后面的probability和confidence。

Confidence表示有没有物体,假设有物体之后,probability表示物体的概率。
通过将confidence和最大可能输出的类的probability相乘之后,要是得出的结果大于门限0.24,就会输出当前计算出的bbox的大小和位置,同时会输出是哪一个类,probability大小是多少。一共会生成13*13*5个bbox,然后根据probability,通过filter,产生出最后预测的物体和其边框。


举一个例子,就是最前面那个有狗,有轿车,有自行车的图像,比较图中最后的三行就可以看出来,里面有轿车,狗和自行车,也能看到probability和bbox分别是什么,它们分别表示概率、大小和位置。具体来讲,从第一行,可以看出轿车的class_id为6,通过row和col可以看出大概的位置,还给出了anchor_id。第二行可以看到轿车的confidence和stx。你可以按照上面的计算公式计算一下是否正确(后面输出的时候会有一点点小的resize)。
其实这些通过stx、sty、tw、th计算box的位置是检测的时候才计算的,训练的时候是用stx、sty、tw、th进行损失计算的。
关于损失函数:

前面讲的是forward的过程,即给了一个图像和神经网络,怎么得到识别的物体概率和位置。那么具体的训练过程是如何的呢,怎么去进行训练?论文了中给了一个损失函数。要是给予一个合适的损失函数,给一定的数据去训练,那么神经网络就会得到好的表现。
进行训练的一共有四类loss,他们weight不同,分别是object、noobject、class、coord。总体loss是四个部分的平方和。
关于YOLOv2表现:

论文中列出了一些YOLO 2在标准目标检测集上的表现,由于YOLO 2网络只包含卷积层和池化层,因此可以接受任意尺寸的图像输入。从图中可以看到R-CNN和SSD的精度也是比较高的,但SSD是基于VCC-16来预训练,fps比较慢。YOLO 2的精度相对YOLO提高了很多,速度也有相应提升。对于YOLO 2,不同的图像大小也会产生不同的mAP
关于YOLOv2与YOLOv1比较与提升:
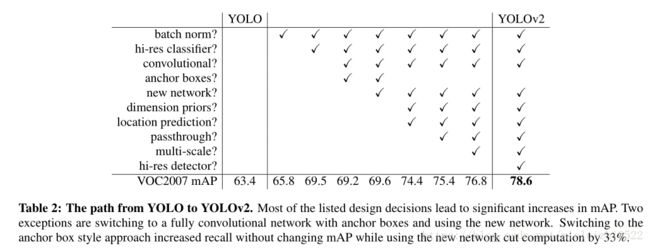
这个部分也是原论文中写的比较多的,也是很多博客里面写的最多的分析,关于下面表格中的一些添加项的影响,我就不一一细说了,这个很容易在网上找到。
谢谢大家,我的表演结束!
参考文献:
1.https://blog.csdn.net/shuzfan/article/details/54018736
2.https://www.leiphone.com/news/201708/7pRPkwvzEG1jgimW.html
3.https://zhuanlan.zhihu.com/p/32172286