基于深度学习的验证码自动识别(caffe)
最近在学习使用caffe,然后就想试着玩玩验证码识别,结果非常非常棒,深度学习确实是非常强大的。废话少说,跟我走进验证码自动识别。
caffe安装
此处省略一万字,网上教程千千万,你一定可以找到,接着往下看。
剧情描述
之前对京东的某些数据进行采集,但是总会有验证码挡着,先看个例子:
http://mall.jd.com/showLicence-56803.html
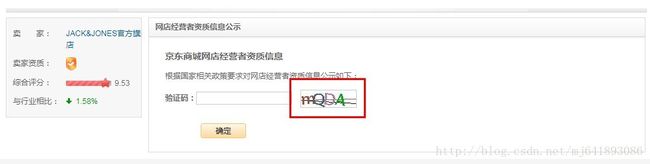
如果我们能够自动识别这样的验证码,那么我们就可以进入到验证码后面的页面了,所以我们就开始搞定它。
数据集准备
下面是后面所述使用的数据地址:
http://download.csdn.net/detail/mj641893086/9895307
http://download.csdn.net/detail/mj641893086/9895307
http://download.csdn.net/detail/mj641893086/9895307
重要的事情说三遍!!!
我们人工标注了1100个验证码图片,其中1000个用作训练,100个用作测试。
未切分数据
下图是未切分的图片(编号-标注),train_notsplit和test_notsplit都是这样的格式:

切分数据
由于图片中包含四个字符,所以我们是肯定需要切分开一个个训练的(当然也可以有非常非常大的训练集整体训练),图片大小是85*26的,切分也比较容易,注意的是左右两边都多扩展一点点像素,可以让完整的字符包含进来,其实不会影响最终的训练效果。可以通过下面的程序进行切分:
#split_verify_code.py
#!/home/cloud/anaconda2/bin/python
#-*-coding:utf-8-*-
import sys
import time
import math
import json
import random
from PIL import Image
reload(sys)
sys.setdefaultencoding('utf8')
# split verify_code image
save_dir = "./"
for line in sys.stdin:
image_file = line.rstrip('\n')
img = Image.open(image_file)
s = image_file
if image_file.rfind('/')!=-1:
s = image_file[image_file.rfind('/')+1:]
part = s.split('-')
id = part[0]
#img.size (85,26)
region = [(0,0,20,26),(16,0,38,26),(34,0,56,26),(52,0,74,26)]
for i in range(0,len(region)):
cropImg = img.crop(region[i])
path = save_dir+'/'+id+'-'+str(i)+'-'+part[1][i:i+1]+'.jpg'
print path
cropImg.save(path)下图是切分的数据图片(编号-第几个字符-标注),train和test都是这样的格式:
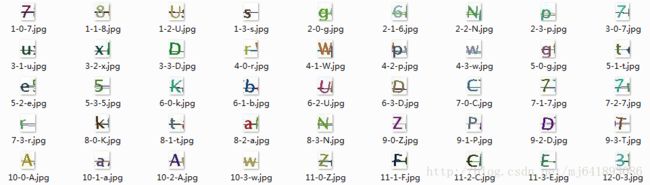
四个图片大小:20*26, 22*26, 22*26, 22*26。
容易想到的模型就是lenet的手写体数字识别模型,所以模型自己看,很简单,只讲实现的步骤。
实验流程
标签文件生成
也就是train.txt和test.txt生成,第一列是文件名,第二列是对应的标签编号,可以自己设置对应关系,在此给出参考生成方法。
find ./train/ -type f | awk '{print substr($0,length($0)-4,1)}' | sort | uniq > label.uniq
#总共56个label,没有0,o,O,1,l,L(本来是64个的,这几个不方便区分)
find ./train/ -type f | awk '{print $0" "substr($0,length($0)-4,1)}' | cut -f3 -d'/' > train_tmp.txt
awk -F' ' 'BEGIN{id=0}NR==FNR{a[$1]=id;id+=1}NR>FNR{print $1,a[$2]}' label.uniq train_tmp.txt > train.txt
find ./test/ -type f | awk '{print $0" "substr($0,length($0)-4,1)}' | cut -f3 -d'/' > test_tmp.txt
awk -F' ' 'BEGIN{id=0}NR==FNR{a[$1]=id;id+=1}NR>FNR{print $1,a[$2]}' label.uniq test_tmp.txt > test.txtlmdb格式转换
由于lmdb是caffe爱用的一种数据格式,所以我们需要对原始的数据进行格式转换,使用caffe自带的工具。
build/tools/convert_imageset --shuffle --resize_height=26 --resize_width=22 ./train ./train.txt ./train_lmdb
build/tools/convert_imageset --shuffle --resize_height=26 --resize_width=22 ./test ./test.txt ./test_lmdb至此,数据已经转换到train_lmdb和test_lmdb目录下了,注意图片大小,全部变成了22*26,主要是针对每个验证码的第一个字符(这个和切割有关)。
均值计算
mean.binaryproto是均值文件,为加快计算的效率和训练的模型准确率而设计的,也通过caffe自带的工具compute_image_mean 来实现,数据集就采用train_lmdb就可以。
build/tools/compute_image_mean ./train_lmdb ./mean.binaryproto模型训练
该准备的数据都准备好,接下来我们就开始训练,别急,先看下模型定义文件,看看哪里有没有什么需要改动的地方(其实得做一点小修改,否则不能训练哦)。
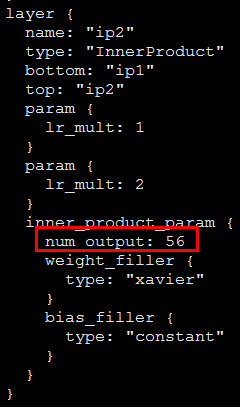
打开:lenet_train_test.prototxt,注意最后ip2层的num_output,应该和我们最后的标签个数56一致哦,标签数在上面说过。
开始训练,同样使用caffe核心模块caffe:
build/tools/caffe train -solver lenet_solver.prototxt模型测试
大概半个小时左右,模型已经训练好了,就是verify_code_iter_10000.caffemodel,而且已经对测试数据进行了预测,准确率杠杠的99%,可能每次会有少许差别。
![]()
我们现在可以在单个图片上测(嘚)试(瑟)下了,咳咳咳,同样使用caffe自带的工具:
先说下lenet_test.prototxt文件,是基于lenet_train_test.prototxt修改的,主要将输入层变成了Input,输出的Accuracy层去掉。
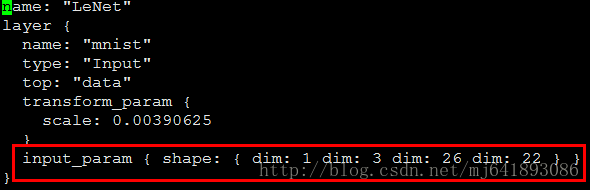
./build/examples/cpp_classification/classification lenet_test.prototxt verify_code_iter_10000.caffemodel mean.binaryproto label.txt test/1100-2-Y.jpg迫不及待看下结果:
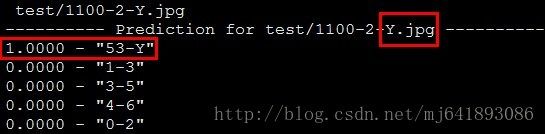
到此,基本大功告成,嗨僧吧!