Java线程--线程池原理
目录
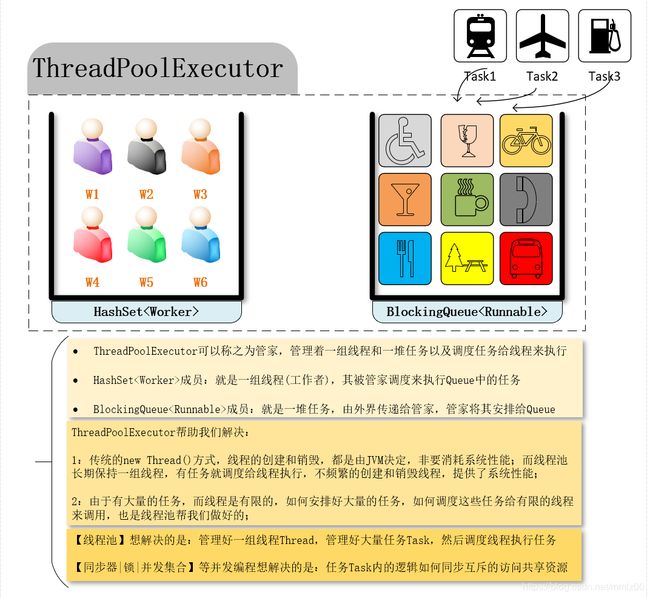
ThreadPoolExecutor
为什么用线程池
传统的方式编写多线程:
线程池的方式编写多线程:
线程池简介
线程池工作原理
线程池的构造函数:
线程池工作原理描述:
线程池工作原理图解:
线程池工作原理的流程图:
线程池的安全策略:
线程池的三种队列:
线程池的线程为什么不回收:
execute()方法:
addWorker()方法:
new Worker() 构造器:
runWorker(this)方法:
getTask()方法:
总结
线程池不回收我们怎么办?
allowCoreThreadTimeOut
shutdown()
shutdownNow()
线程池的运用
线程池的监控
ThreadPoolExecutor
为什么用线程池
/**
* 传统多线程代码编写方式
*/
class MyTask implements Runnable{
public void run(){}
}
public class Test{
public static void main(String[] args){
MyTask task = new MyTask();
Thread thread = new Thread(task);
thread.start();
}
}传统的方式编写多线程:
1:新建线程,用来执行任务,任务执行完毕后,线程被销毁。线程的频繁新建/销毁都是由JVM管理的,非常的消耗系统性能。
2:当任务比较小时,花在创建和销毁线程上的时间会比任务真正执行的时间还长。尤其是如果有大量的任务时,线程的大量创建和销毁,有内存溢出的风险。
线程池的方式编写多线程:
线程池的出现,不但解决了以上两个毛病,同时还带来其它方面的优化和提升:
A:线程池中的线程是可以重用的,不用频繁的创建和销毁,提高了系统的性能。
B:线程池中的队列可以管理大量的任务,任务的执行,调度,排队,丢弃等事宜都由线程池来管理,做到任务可控。
C:线程池对线程进行一些维护和管理,比如线程定时执行,线程生命周期管理,多少个线程并发,线程执行的监控等。
线程池简介

| 接口 | Executor | 其内仅有execute(Runnable task);方法 |
| ExecutorService | 继承Executor,对线程有更多的管理,常用的有:submit()方法、shutdown()方法等 | |
| ScheduledExecutorService | 继承ExecutorService,对线程又进一步的支持了定时执行的职能 | |
| 类 | AbstractExecutorService | 默认实现了ExecutorService接口中的部分方法 |
| ThreadPoolExecutor | 我们常用的类,里面的职能有:维护任务队列,维护线程组,管理线程调度,执行,监控,等 | |
| ScheduledThreadPoolExecutor | 里面的职能相对于父类ThreadPoolExecutor来说,多了对线程定时执行的职能 |
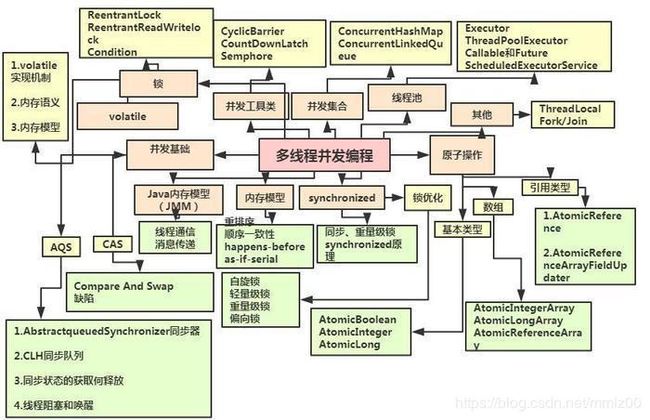
线程池只是并发编程中的一小部分,下图是史上最全面的Java的并发编程学习技术总汇
线程池工作原理
/**
* 线程池的构造函数
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) //后两个参数为可选参数 线程池的构造函数:
谈到线程池的工作原理,首先要从线程池的构造函数说起:
| 参数名 | 中文名称 | 业务说明(我以"快递员派送包裹"来易于大家理解) |
| corePoolSize | 核心线程数 | 有编制的正式快递员员工个数 |
| maximumPoolSize | 最大线程数 | 比如:双11了,包裹量急剧增多,正式员工忙不过来,只能新招临时工 =( 最大 - 核心 ) |
| keepAliveTime | 临时工呆多久 | 临时工就是临时工(包裹量不多的时候会被辞退的),能呆几天呢,就是这个keepAliveTime |
| unit | 临时工呆多久的计量单位 | 比如:临时工呆多少小时,那么unit就计量单位为小时;临时工能呆多少天,unit计量单位就是天;临时工能呆多少月,unit计量单位就是月....等等 |
| workQueue | 任务队列 | 需要派送的大量包裹存储的地方 |
| threadFactory | 线程工厂 | 使用ThreadFactory创建新线程,默认使用defaultThreadFactory创建线程 |
| handle | 异常处理 | 包裹实在太多,多到正式员工和临时工一起派送都忙不过来,另外存放包裹的地方都被撑爆了,实在没地方存这些包裹了。那么这时仍源源不断新来的包裹我们的处理方案就是handle |
线程池工作原理描述:
1:有新任务了,尽可能的让核心线程去执行;
2:核心线程都在忙了,在来的任务就放到队列中去排队等待被调度;
3:队列中都塞满了任务,还来新任务,就临时招募非核心线程来执行刚到的新任务;
4:队列满了,核心线程/非核心线程都在忙,还来新任务,那么只能启用安全策略;
5:安全策略来处理仍源源不断到来的新任务,安全策略决定是丢弃新来的任务,还是其它处理。
线程池工作原理图解:
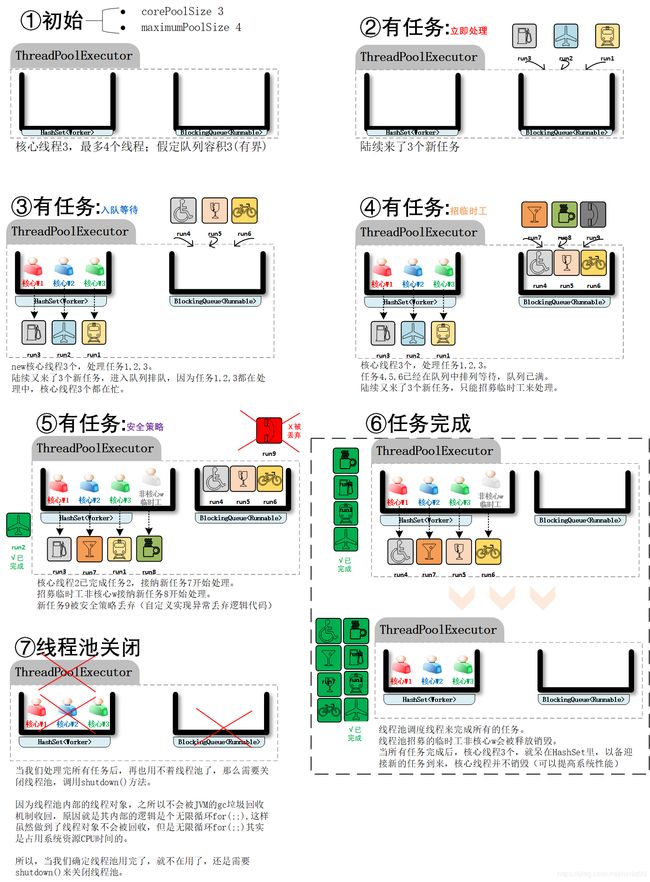
线程池工作原理的流程图:
上述图解动画,翻译成程序的流程图如下:
线程池的安全策略:
看到图示中,当新任务的到来,无法被线程池接纳时,安全策略(也叫饱和策略)来处理这种异常,策略有哪些呢?看下表
| 安全策略名称 | 业务含义 |
|---|---|
| AbortPolicy | 默认策略,不执行此任务,而且直接抛出RuntimeException 切记execute()需要try catch,否则程序会直接退出 |
| DiscardPolicy | 直接抛弃,任务不执行,空方法 |
| DiscardOldestPolicy | 从队列里面抛弃head的一个任务,并再次尝试调用execute(task); |
| CallerRunsPolicy | 当前线程调用的execute(task)方法,当前线程阻塞在这里,直至task执行完毕 |
| 自定义策略 | (常用)自定义类实现RejectedExecutionHandler。例:可以先把任务写入文件或者数据库,以防止任务丢弃 |
线程池的三种队列:
看到图示中,假定队列是有界的,是不是说还有无界的队列呢?还有更多种队列嘛?常用的三种队列,看下表
| 队列名称 | 边界 | 业务含义 |
|---|---|---|
| SynchronousQueue | 有界,值1 | 在某线程添加元素后必须等待其他线程取走后才能继续添加(可以观看我的博客:生产者消费者产1消1模式类似的业务场景) |
| LinkedBlockingQueue | 无界|有界 均可 | 链表存储结构,删除操作代价高。
若初始化的时候,给予了初始值就是有界的,反之是无界的。
FIFO原则,队头head处取出任务,队尾tail处插入任务。
高效的并发性能:一个原子AtomicInteger的队列元素个数count,一把消费者互斥锁,一把生成者互斥锁,FIFO原则,组合在一起构成了高并发性能。往队尾插入任务时的生产锁由多个生产者互斥访问;从队头取出任务时的消费锁由多个消费者互斥访问;插入也好,取出也罢,插入后/取出后,同步的更改队列内元素个数;(可以观看我的博客:停车场类似的业务场景)。 |
| ArrayListBlockingQueue | 有界 | 数组存储结构,遍历是速度快的,因为数组是连续存储的,但是它的操作比如:移出操作是较慢的,因为要重新排序受影响的元素。为了解决移出问题,可以将此数组想象成为一个循环数组,并且配备两个指针,两个指针顺时针方向走位。可参考 博客
初始化的时候,给予初始值,所以是有界的。
FIFO原则,队头takeIndex处取出任务,队尾putIndex处插入任务。
并发性:在生产者放入数据和消费者获取数据,共用同一个互斥锁对象ReentrantLock,由此也意味着两者无法真正并行运行,就是说,ArrayListBlockingQueue是被互斥访问的,只允许单一线程获得该锁后才能进行业务逻辑的执行,执行完后,释放锁。 |
线程池的线程为什么不回收:
我们平时编写的Java代码,当new出来一个对象后,这个对象被访问使用过后,我们是不用关心对象的回收的,是JVM虚拟机的gc垃圾回收机制,自动帮我们回收没用的对象。那么,就有疑问,为什么Executor线程池对象不被回收,线程池中的线程也不会gc回收呢?这要从源码处着眼分析:
我们平时在使用线程池的时候,都是直接 线程池.execute(Runnable);看看ThreadPoolExecutor类的源码execute(Runnable)方法的内部逻辑:
execute()方法:
/**
* ThreadPoolExecutor类的部分源码(我裁剪掉了一部分)
*/
/**
* 配合我的线程池工作原理图解来看源代码,容易理解些
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*(图解1)
* 当前几个员工在忙
*/
int c = ctl.get();
/*(图解2)
* 线程池先尽可能的让所有正式员工都上班
*/
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) //员工上班,且立马执行新任务
return;
c = ctl.get();
}
/*(图解3)
* 所有核心线程都在忙,任务入队列
*/
if (isRunning(c) && workQueue.offer(command)) {//线程池没关闭并且新任务入队列成功
int recheck = ctl.get();//再次检查当前几个员工在忙(因为CPU是指令执行级别的,上面两检查完毕后,还不知道各个线程都忙成什么样了呢)
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*(图解4)
* 所有核心线程都在忙,任务入队列失败(队列已满),尝试招募临时工
*/
else if (!addWorker(command, false))
/**(图解5)
* 预算有限,临时工都招满了,当前的新任务只能被安全策略异常处理
*/
reject(command);
}
通过以上源码会发现,主要的是addWorker()方法,这里面伴随着员工上班,并且立马干活去执行任务,让我们继续分析:
addWorker()方法:
/**
* 部分源码,我已裁剪掉一部分
*/
private boolean addWorker(Runnable firstTask, boolean core) {
/**
* 新建一个Worker,并立马让worker工作,t.start();
*/
w = new Worker(firstTask);
final Thread t = w.thread;
t.start();
}通过以上源码会发现,主要的是new Worker()方法,这里Worker是个包装器,让我们继续分析:
new Worker() 构造器:
/**
* Worker类的部分源码
*
* Worker类实现了Runnable接口
*
* Worker类包装了firstTask
*
* 调用worker.thread.start()方法,执行run()方法,run()方法内部调用runWorker(this);
*/
class Worker extends AbstractQueuedSynchronizer implements Runnable
{
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask; //Worker类包装了firstTask
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
}
/**
* Worker类实现了Runnable接口
* Worker类包装了firstTask
* 调用worker.thread.start()方法,执行run()方法,run()方法内部调用runWorker(this);
*/
通过以上源码会发现,主要的是Worker类的runWorker(this);方法让我们继续分析:
runWorker(this)方法:
/**
* 部分源码,已被我裁剪一部分
*/
final void runWorker(Worker w) {
Runnable task = w.firstTask;
/**
* 这就是worker不会被回收,不知疲倦的始终执行任务的根本所在
*
* 执行当前任务,执行完毕后,当前任务为null; 进而 从Queue中不停的取出任务去执行
*
* 这个埋个伏笔,从Queue队列中再也拿不到任务了,是不是说当前worker就要消亡?那就要分析getTask()
*/
while (task != null || (task = getTask()) != null) {
task.run();
}
}/**
* 这就是worker不会被回收,不知疲倦的始终执行任务的根本所在
*
* 执行当前任务,执行完毕后,当前任务为null; 进而 从Queue中不停的取出任务去执行
*
* 这个埋个伏笔,从Queue队列中再也拿不到任务了,是不是说当前worker就要消亡?那就要接着分析getTask()方法
*/
通过以上源码会发现,线程worker被新建之后,就执行firstTask,firstTask执行完毕之后(firstTask=null),并不被JVM的gc垃圾回收机制回收,因为它还在死循环,不停的从队列中取出任务来执行。那如何保证getTask();方法就一定能取到任务呢?让我们继续分析getTask()方法:
getTask()方法:
/**
* 部分源码,已被我裁剪一部分
*/
/**
* If false (default), core threads stay alive even when idle.
* If true, core threads use keepAliveTime to time out waiting
* for work.
*/
//默认值false 意思是不回收核心线程,怎么做到不回收呢?看代码workQueue.take();有阻塞功效,当前线程拿不到任务时,就阻塞在这里,直到拿到新任务
private volatile boolean allowCoreThreadTimeOut;
/**
* Core pool size is the minimum number of workers to keep alive
* (and not allow to time out etc) unless allowCoreThreadTimeOut
* is set, in which case the minimum is zero.
*/
private volatile int corePoolSize;
private Runnable getTask() {
/**
* 死循环:直到互斥的访问队列时,能从队列中取出一个任务
*/
for (;;) {
/**
* allowCoreThreadTimeOut 若为真,允许核心线程经过keepAliveTime时间后回收销毁
* allowCoreThreadTimeOut 为假时(默认值false)
* wc > corePoolSize 为真,说明有临时工在忙
* wc > corePoolSize 为假,说明没临时工
*/
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;//回收线程 因为返回null后,调用该getTask()方法的上层入口方法runWorker()就退出了死循环,进而导致线程被gc回收销毁
continue;
}
/**
* timed 为真, 当前线程poll()取任务,如果没有任务就进入下一次循环
* timed 为假,当前线程一定是核心线程,就take()取任务,如果没有任务就阻塞在这里,核心线程不被gc回收的真谛
*/
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();//线程永不回收的秘密(取不到任务,我就阻塞在这里,所以我不会被gc回收)
if (r != null)
return r;
}
}通过以上源码分析,从队列当中获取任务时,也是个死循环,不停的尝试取得任务。这里有:回收线程的代码 return null;这里也有:核心线程永不回收的真谛 workQueue.take();[当然核心线程也是可以有回收的机会的,当allowCoreThreadTimeOut为真时,在当前队列任务中所有的任务都执行完毕并且再也没新任务到来时,核心线程就会在经过keepAliveTime时长后被gc回收]。那说到这,又引申出一个新的话题:所有的任务何时被执行完呢,编写程序时,有办法知道嘛?
总结
线程池的线程不会被gc回收,就是因为线程池用一堆包装的Wroker类的集合,在里面有条件的进行着死循环,从而可以不断接受任务来进行。
线程池不回收我们怎么办?
上一小节,我们探讨了线程池为什么高效,就是因为它内部管理的一组线程不gc回收,所以不会发生频繁的创建和销毁线程,用有限的线程反复的重用去执行队列中的大量任务,提高了系统的性能。
那这一小节我们探讨的是,不回收线程也不是绝对的一件好事,我所有的任务都执行完了,再也没有新任务来了,你还不回收线程,阻塞在这里,这也是浪费系统资源的。进而,我们不仅要问,程序上有没有办法知道所有的任务是何时被执行完的呢?如果都执行完了,我怎么回收这些阻塞着的线程呢?有三种办法,详解如下:
allowCoreThreadTimeOut
allowCoreThreadTimeOut默认是false的,当其设置为true时,是有机会释放核心线程的,示例代码如下:
/**
* 演示回收核心线程:allowCoreThreadTimeOut
*/
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
import java.util.concurrent.atomic.*;
public class ExecutorTest{
public static void main(String[] args){
BlockingQueue queue = new LinkedBlockingQueue();
ThreadPoolExecutor e = new ThreadPoolExecutor(3, 6, 1, TimeUnit.SECONDS,queue);
/**
* 一般不建议这样使用,我们更多的是使用shutDown()方法
*
* 这一句如果注释掉,所有线程都执行完任务后,线程池里还有3个核心线程是阻塞在这里的
*/
e.allowCoreThreadTimeOut(true);
for(int i=0;i<10;i++){
e.execute(new Runnable(){
public void run(){
try{
Thread.sleep((long)(Math.random()*100));
System.out.println(Thread.currentThread().getName()+"子线程执行完");
}catch(Exception e){}
}
});
}
}
}shutdown()
建议使用shutdown()方法,来使得所有线程池内的任务都顺利执行完毕后才回收线程。之所以能回收,是线程池内部调用了interrupt()方法,来使得所有getTask(){queue.take();}时被阻塞的线程被中断。
/**
* shutdown方法的部分代码:
*/
public void shutdown() {
interruptIdleWorkers(); //将工作者worker进行阻断(即:线程.interrupt();)
tryTerminate(); //线程池终结
}
/**
* 核心线程处理完任务队列中的任务后,都在那里痴痴的等待新任务而被阻塞,这也是线程池不回收核心线程的根本所在workQueue.take();
* 为此,不能让线程池总是傻傻的在那等待新任务,线程池想要关闭了,于是有了本处的t.interrupt();调用
*/
private void interruptIdleWorkers(boolean onlyOne) {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock())
t.interrupt(); //核心线程之所以能回收:因为核心线程是阻塞状态的
}
}这里一定要注意:
执行该方法时,线程池的状态则立刻变成SHUTDOWN状态。此时,则不能再往线程池中添加任何任务,否则将会抛出RejectedExecutionException异常(也就是说:代码中调用executor.shutdown()方法之后,后续的代码部分不能在出现executor.execute()或者executor.submit()的调用)。
但是,此时线程池不会立刻退出,直到添加到线程池中的任务都已经处理完成,才会退出。
/**
* 演示回收核心线程:shutdown()方法
*/
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
import java.util.concurrent.atomic.*;
public class ExecutorTest{
public static void main(String[] args){
BlockingQueue queue = new LinkedBlockingQueue();
ThreadPoolExecutor e = new ThreadPoolExecutor(3, 6, 1, TimeUnit.SECONDS,queue);
for(int i=0;i<10;i++){
e.execute(new Runnable(){
public void run(){
try{
Thread.sleep((long)(Math.random()*100));
System.out.println(Thread.currentThread().getName()+"子线程执行完");
}catch(Exception e){}
}
});
}
/**
* 建议使用shutDown()方法,来使得所有线程池内的任务都顺利执行完毕后,回收线程,之所以能回收,是线程池内部调用了interrupt()方法,来使得所有getTask(){queue.take();}时被阻塞的线程被中断
*
* 这一句如果注释掉,所有线程都执行完任务后,线程池里还有3个核心线程是阻塞在这里的
*/
e.shutdown();
while (true) {
if (e.isTerminated()) {
System.out.println("所有子线程都彻底结束了!");
break;
}
try{
Thread.sleep(200);
}catch(Exception e1){}
}
/**
* e.isTerminated();
* 当shutdown()或shutdownNow()执行了之后才会执行,并返回true。
* 不调用shutdown()或shutdownNow()而直接调用isTerminated()永远返回false。
*
* 通过while(true){Thread.sleep(200);}来死循环对cpu的占用,资源的浪费。让它睡一会,可以释放cpu
*/
}
}shutdownNow()
一般不建议使用shutdownNow()方法,原因是:它不再处理已经加入到队列中的排队等待的任务。
执行该方法,线程池的状态立刻变成STOP状态,并试图停止所有正在执行的线程,不再处理还在池队列中等待的任务,当然,它会返回那些未执行的任务。它试图终止线程的方法是通过调用Thread.interrupt()方法来实现的,但是大家知道,这种方法的作用有限, 如果线程中没有sleep 、wait、Condition、定时锁等应用, interrupt()方法是无法中断当前的线程的。所以,ShutdownNow()并不代表线程池就一定立即就能退出,它可能必须要等待所有正在执行的任务都执行完成了才能退出。
isShutDown()当调用shutdown()或shutdownNow()方法后,不论线程池中的任务是否完成,立马返回为true。
isTerminated()当调用shutdown()方法后,并且等到所有线程池中的任务都完成后,才返回为true。
线程池的运用
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
2、任务的优先级:高、中和低。
3、任务的执行时间:长、中和短。
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行
如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点儿,比如几千。有时候我们系统里后台任务线程池的队列和线程池全满了,不断抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞,任务积压在线程池里。如果当时我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。当然,我们的系统所有的任务是用单独的服务器部署的,我们使用不同规模的线程池完成不同类型的任务,但是出现这样问题时也会影响到其他任务。
线程池的监控
如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。