大数据之路之如何构建数据仓库(上云-建模-应用)
场景:xx公司刚成立,要做某一业务的大数据分析项目,原业务有y个系统需要整合上云并构建数据仓库,如果是你来主导,你将怎么做?
1、如何数据集成,有哪些注意事项,工具选型。
2、数据仓库的主体域如何构建,有什么痛难点。
3、随时间的变化,数据仓库越来越大,历史数据如何处理?
4、针对维度表,时间维度表如何进行构建。
5、如何构建信息相对稳定的数据仓库,数据模型?
6、如何构建一个可以商用的数据仓库。
数据仓库的构建是从ETL到数据仓库到主题应用,分层次而成,因此这里也分成三部分来述说,此外前面数据集成已经说过(传送门),故下面所有的篇章均基于云上,也就是平台之上,即构建大数据平台数据仓库
目录
1 数据集成(ETL)
1.1 源端数据
1.1.1 数据属性
1.1.2 数据采集
1.1.3 运维保障
1.2 全量标准数据
1.2.1 数据属性
1.2.2 数据设计
1.3 基础主题数据
1.3.1 数据属性
1.3.2 数据设计
1.4 应用数据
1.4.1 数据属性
1.4.2 数据设计
2 数仓建模
2.1 柔性建模
2.2 三范式建模
2.3 多维模型建模
3 应用
3.1 数据加工
3.2 数据传输
3.3 运维保障
3.3.1 数据运维
3.3.2 平台运维
1 数据集成(ETL)
1.1 源端数据
1.1.1 数据属性
数据类型:结构化数据,半结构化数据,非结构化数据
源数据库类型:Oracle,PostgreSQL,MySQL,SQL Server等
数据来源:业务数据,互联网数据,其他第三方数据
数据特性:实时数据,离线数据,准实时数据
1.1.2 数据采集
数据采集依据数据属性的不同采取不同的采集方式
离线数据:通过全量+增量的方式从源端数据库采集上云到平台,依据数据的冷热程度来按时,日,月,年来进行分区,采集工具可使用DataX/Kettle+OGG来实现,就是第一次用DataX/Kettle扫描全库全量上云,后续的增量用OGG等增量捕获工具捕获并通过DataX/Kettle按照平台任务调度上云。
实时数据:可通过流计算采集上云,比如阿里云的Flink + OGG + DataHub,流计算平台的数据可与离线计算平台的数据配合使用,达到冷热数据的合理配用,节约存储空间和提升运算性能
准实时数据:可看作频率较高的离线数据,数据上云采集可参照离线数据,只不过运算频率需提升,也可每一个频率都全量上云
1.1.3 运维保障
数据采集在项目实施时会发布成任务jobs,按照任务调度来达到实际项目需求,但在生产过程中,会存在上云数据验证,源端感知,源端表结构变化等等需求
数据验证:每一次的上云,包括流计算在内,都需要一个应用:数据验证来验证上云数据的完整性,准确性并生成验证日志报告供后续需求调研以及数据查找验证。原理是读取上云日志并用源端数据与云上数据进行结构,数据的对比
源端感知:通过自动定时调度或者手动触发调度源端数据感知比对任务的方式,将大数据平台的数据表结构与源端数据表结构进行差异化比对,从而感知出源端结构是否发生变化(如增列、减列、改列名等),将捕获的差异化信息,提交至在线层,通过前端应用展示出变化的内容及影响分析。源端感知及自动化测试验证,可及时发现业务系统每次商机的造成的数据变动,并确
认数据平台每次升级不影响以往历史数据调用。结合应用版本管控计划、源端池化资源变化比较、以及加工链路影响分析,进行变化感知以及加工任务异常预警。架构图如下,(以阿里云ODPS为例)
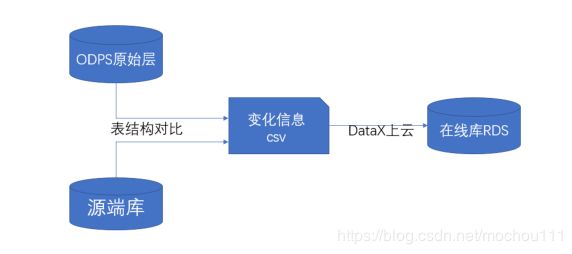
结构变化处理:源端表结构发生变化,云上平台通过源端感知获取到之后要及时做出改变。表结构变化分七种情况:新增表,删除表,新增表字段,删除表字段,变更字段类型,变更字段名称,变更字段长度,变更字段顺序。简单总结就是表变化和表结构变化。对应处理方式是:
- 表变化
当作新增表上云,采用全量+增量的上云方式处理;初始化全量,后续每天增量加载数据。
- 表结构变化
1、查找结构变更表;
2、旧表备份;
3、重新初始化;
4、添加任务调度;
5、其他相关应用配置更改
1.2 全量标准数据
1.2.1 数据属性
数据类型:结构化数据
源数据库类型:大数据平台
数据来源:源端数据层
数据特性:实时数据,离线数据,准实时数据
1.2.2 数据设计
从源端数据加工而成的全量数据,并进行去重,降噪等一系列清洗标准操作,目的是为了得到一份与源端数据库一样的全量标准数据供后续主题建模直接使用
INSERT OVERWRITE TABLE xxx.xxxx PARTITION(rfq='20190719')
SELECT uuid
,uuid2
,czid
FROM (
SELECT uuid
,uuid2
,czid
,ROW_NUMBER() OVER (PARTITION BY CONCAT(uuid) ORDER BY CAST(czid AS decimal) DESC) AS rn
FROM (
SELECT uuid
,uuid2
,czid
FROM xxx.xxxx
WHERE rfq = '20190718'
AND czid != 'D'
UNION ALL
SELECT uuid
,uuid2
,czid
FROM xxx.xxxx
WHERE RFQ = '20190719'
) T
) t
WHERE t.rn = 1
AND t.czid != 'D'
;1.3 基础主题数据
1.3.1 数据属性
数据类型:结构化数据
源数据库类型:大数据平台
数据来源:全量标准层,基础主题层
数据特性:实时数据,离线数据,准实时数据
1.3.2 数据设计
这是数据仓库建设的核心所在,主题表建设来源数据为上游的全量标准数据以及自身依赖的主题数据,是后续应用表及算法表等所需的基础主题数据,加工过程与上类似,可设计为非分区表,供应用层直接调用
1.4 应用数据
1.4.1 数据属性
数据类型:结构化数据
源数据库类型:大数据平台
数据来源:基础主题层
数据特性:实时数据,离线数据,准实时数据
1.4.2 数据设计
面向前端应用展示的数据层,这里可加工应用数据,调度参考上游,也可依据实际业务进行相应的流程更改,这一层的加工需要对业务较为熟悉的人来设计开发
2 数仓建模
2.1 柔性建模
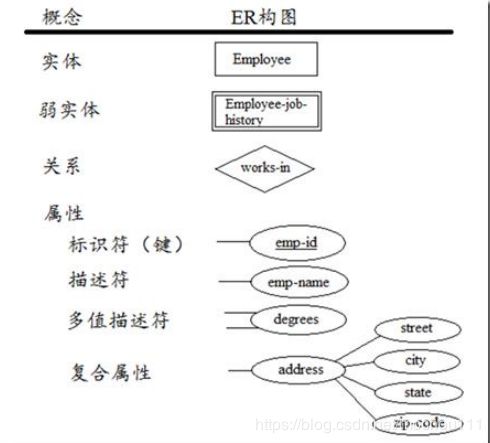
互联网数据模型设计的精髓,就是用柔性迭代方式实体关系建模,来满足用户驱动下快速响应和应用迭代升级。数据主题层的建设主要的目的是将采集和整理后得基础数据,以实体关系建模的方法重新组织数据。设计扩展性强的数据模型,随着原始业务数据的逐步丰富,不停丰富实体、属性、关系类的数据。介绍一下实体关系建模的方法。实体关系(ER)模型的目标是捕获现实世界的数据需求,并以简单、易理解的方式表现出来。
ER模型中的基本元素:基本的ER模型包含三类元素:实体、关系、属性
2.2 三范式建模
三范式建模法,主要是对数据实体以及之间的关系的建模,实体(如人、地点、概念、事件等)用矩形方框表示;实体之间的关系(联系),用方框之间的连线表示;实体的属性,用方框内的属性名称来表示。能建立完整的概念模型并支持直接将模型转换为物理数据库的结构。实体之间的关系可以分为确定关系和不确定关系。确定关系又分为连接关系和分类关系。连接关系也称
“父子关系”,它是两个实体之间的联系或连接,一个实体(子实体)依赖于另一个实体(父实体)。分类关系表示实体间的一种分层结构,一个实体(类属实体)表示这些事物的全集,其它(分类实体)则为其子集。不确定关系又称“多对多关系”,两个实体间相互存在着一对多的联系。连接关系又分为标识关系和非标识关系。判别一个关系是标识关系还是非标识关系只要区分子实体的主键,看是否需要父实体的外键来共同作为主键,需要则为标识关系;如果子实体自己的主键就可唯一标识则它为非标识关系。在标识关系中的子实体称为依赖实体,用圆角矩形表示;其它用方角矩形表示的就是独立实体。分类关系根据表示分类的实体集是不完全分类还是完全分类的又可以分为不完全分类关系和完全分类关系。三范式建模法的步骤如下所述:
- 初始化工程
- 定义实体
- 定义联系
- 定义码
- 定义属性
- 定义其他对象和规则
2.3 多维模型建模
多维模型建模是指通过分析数据仓库范围内的主要对象,确定系统的主要主题域以及主要主题域之间的关系。分析阶段将详细检查定义阶段所提出的要求,并且研究任何可能提供解决方案的环境。数据仓库的设计者通过对用户的访问,得到用户对数据仓库结构以及数据仓库存在环境的要求,并将分析结果转变成概念模型,提交给被访问者进行确认,以保证设计者对当前环境的正确理解。
多维建模主要分为以下几步来进行:
- 分析指标的选择
- 聚合粒度定义
- 维度表详细设计
- 事实表详细设计
- 模型实现
3 应用
3.1 数据加工
应用层数据从基础主题层和公共计算层等提取数据并依据实际业务进行加工,具体加工流程,频率,设计方案等见上
3.2 数据传输
可通过云平台自带的数据集成功能,如阿里云的CDP来把加工好的应用数据按照设计发送到目标展示数据库,也可通过数据同步工具如DataX来实现
3.3 运维保障
3.3.1 数据运维
数据是一个平台数据仓库的核心,所以从源数据库--源数据层--全量标准层--基础主题层--应用层,每一层的数据都要保障完整性,一致性,保障方案见1.1.3
对于历史数据,可依据实际业务进行周,月,年的生命周期,定时清理以保障平台的存储空间,增进应用有效性
3.3.2 平台运维
无论是大数据平台还是流计算平台,平台的稳定与可靠保障了运算效率和准确,对于这些平台和服务器的监控可统一设计出一个监控大屏展示区,进行统一管理运维,做到及时发现,及时解决