使用requests和scrapy模拟知乎登录
##获取登录传递的参数
在正式开始之前,首先需要做的就是获取登录知乎时候传递的参数
https://www.zhihu.com/

可以看到,这里当登录的时候,是传递红色部分标注出来的四个参数的,并且访问的是https://www.zhihu.com/login/phone_num地址,但是这里验证码需要用户点击倒立的字,目前我还没有办法,但是可以使用手机端登录看看,其实是让用户输入登录验证码的,因此,可以使用手机端的user-agent
##使用requests模拟登录
手机端登录时候需要传递下面四个参数
data = {
'_xsrf': _xsrf,
'password': password,
'phone_num': phonenumber,
'captcha': captcha
}
其中password和phone_num是密码和用户名,_xsrf和captcha_type是浏览器自己带的hidden值
![]()
###获取xsrf参数
由于用户名和密码已经知道,下面就定义两个方法,分别用来获取_xsrf和captcha_type参数,从上面的分析可知,只需要获取网页内容,然后通过正则表达式解析对应的内容即可获得
####获取网页内容
import requests
def get_xsrf():
response = requests.get('https://www.zhihu.com')
print(response.text)

这是因为没有配置请求头,添加请求头即可
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com/',
}
def get_xsrf():
response = requests.get('https://www.zhihu.com', headers=header)
print(response.text)
此时就可以正常访问了
###获取xsrf参数
text = ''
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(crsf)
上面可以正确获取到xsrf参数,所以只需要将text替换为网页内容即可
def get_xsrf():
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(soup.select('input[name="_xsrf"]')[0]['value'])
return crsf
###获取验证码
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('请输入验证码: ')
return captcha
这里获取验证码,然后人工识别,手动输入赋值给captcha
###使用requests登录
import requests
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except:
print ("cookie未能加载")
def zhihu_login(username, passwd):
login_url = 'https://www.zhihu.com/login/phone_num'
login_data = {
'_xsrf': get_xsrf(),
'phone_num': username,
'password': passwd,
'captcha': get_captcha()
}
response = session.post(login_url, data=login_data, headers=header)
print(response.text)
session.cookies.save() # 保存cookie
zhihu_login('手机号','密码')
此时运行结果如下:


已经登录成功
###判断是否登录成功
另外,当用户登录成功以后,可以访问私信界面
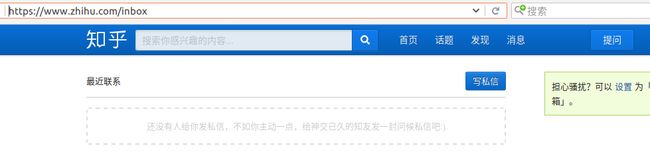
如果退出登录,或者没有登录成功,则会跳转到登录界面,并且返回302的状态码,后面会自动跳转到https://www.zhihu.com/?next=%2Finbox,返回200状态码

##使用requests登录完整代码
# -*- coding: utf-8 -*-
import requests
from http import cookiejar
from bs4 import BeautifulSoup
import time
# 获取session
session = requests.session()
# 获取cookies
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
# 获取cookie,如果之前登录成功,并且已经cookie,则可以获取到
try:
session.cookies.load(ignore_discard=True)
except:
print ("cookie未能加载")
# 设置请求头
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
"Referer": "https://www.zhihu.com/",
}
# 获取xsrf
def get_xsrf():
response = session.get('https://www.zhihu.com', headers=header)
soup = BeautifulSoup(response.text)
crsf = soup.select('input[name="_xsrf"]')[0]['value']
print(soup.select('input[name="_xsrf"]')[0]['value'])
return crsf
# 获取验证码
def get_captcha():
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
print(captcha_url)
response = session.get(captcha_url, headers=header)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('请输入验证码: ')
return captcha
# 判断是否登录成功
def is_login():
inbox_url = 'https://www.zhihu.com/inbox'
response = session.get(inbox_url, headers=header, allow_redirects=False)
if response.status_code == 200:
print('登录成功')
else:
print('登录失败')
# 登录方法
def zhihu_login(username, passwd):
login_url = 'https://www.zhihu.com/login/phone_num'
login_data = {
'_xsrf': get_xsrf(),
'phone_num': username,
'password': passwd,
'captcha': get_captcha()
}
response = session.post(login_url, data=login_data, headers=header)
print(response.text)
session.cookies.save() # 保存cookie
# get_captcha()
# get_xsrf()
# zhihu_login('18710840098','这里输入密码')
is_login()
##使用scrapy模拟登录
在正式开始前,先创建工程和spider
scrapy startproject zhihu
cd zhihu
scrapy genspider zhihu www.zhihu.com
完整代码如下:
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
import json
class ZhihuspiderSpider(scrapy.Spider):
name = 'zhihuspider'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/']
# 定义请求头
header = {
# 使用手机的User-Agent
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36',
'Host': 'www.zhihu.com',
"Referer": "https://www.zhihu.com/",
}
def parse(self, response):
print(response.text)
pass
# spider入口方法
def start_requests(self):
# 访问https://www.zhihu.com/login/phone_num登录页面,在do_login回调中处理
return [scrapy.Request('https://www.zhihu.com/login/phone_num', headers=self.header, callback=self.do_login)]
def do_login(self, response):
response_text = response.text
soup = BeautifulSoup(response.text)
# 解析获取xsrf
xsrf = soup.select('input[name="_xsrf"]')[0]['value']
if xsrf:
login_data = {
'_xsrf': xsrf,
'phone_num': '手机号',
'password': '密码',
'captcha': ''
}
# 由于登录需要验证码,因此需要先获取验证码,在do_login_after_captcha回调获取验证码,封装传递的login_data参数
import time
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
yield scrapy.Request(captcha_url, headers=self.header, meta={'login_data': login_data},
callback=self.do_login_after_captcha)
def do_login_after_captcha(self, response):
# 获取验证码操作
with open('captcha.gif', 'wb') as f:
f.write(response.body)
f.close()
from PIL import Image
try:
im = Image.open('captcha.gif')
im.show()
im.close()
except:
pass
captcha = input('请输入验证码: ')
# 登录
login_data = response.meta.get("login_data", {})
login_data['captcha'] = captcha
login_url = 'https://www.zhihu.com/login/phone_num'
# FormRequest可以完成表单提交,在check_login回调中验证登录是否成功
return [scrapy.FormRequest(
url=login_url,
formdata=login_data,
headers=self.header,
callback=self.check_login
)]
def check_login(self, response):
#验证登录是否成功
text_json = json.loads(response.text)
if "msg" in text_json and text_json["msg"] == "登录成功":
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True, headers=self.header)
此时结果response.text中的内容保存到本地网页,效果如下:

代码下载
专注技术分享,包括Java,python,AI人工智能,Android分享,不定期更新学习视频,欢迎关注