启用Docker虚拟机GPU,加速深度学习
关于环境配置的文章可以算得上是月经贴了,随便上网一搜,就有大把的文章。但我觉得还是有必要记录一下我最近一次的深度学习环境配置,主要原因在于各种软件在快速更新,对应的安装配置方法也会有一些变化。
这篇深度学习环境配置有两个关键词,一个是Docker虚拟机,另一个是GPU加速。
开始之前
Docker虚拟机
首先说一下Docker虚拟机。为什么需要虚拟机?不知道你是否有过这样的经历,在github上看到一个有趣的开源项目,把代码下载下来,按照项目上的说明编译运行,结果发现怎么也不能成功。
或者反过来,你开发了一个不错的项目,丢到github,并把编译步骤尽可能详细的写了出来,然而还是有一堆开发者发布issue,说代码编译运行存在问题。你也很无辜啊,明明在我这儿好好的,怎么到了别人那里就状况百出呢?
为什么会出现这个状况?主要是软件行业讲究快速迭代,快步向前,软件会不停更新。就拿TensorFlow来说,从发布到现在,不知道更新了多个版本。虽然作为软件开发者会尽力保证向前兼容,但实际上很难做到完美兼容。为了解决这一兼容问题,就有必要使用到虚拟机,现在很多开源项目都会提供一个虚拟机文件,里面包含了所有项目所需的软件包和环境。
GPU加速
接下来说一下GPU加速。使用Docker虚拟机解决了开发环境问题,但同时又引入了另一个问题:虚拟机通常无法启用GPU。我们知道,深度学习属于计算密集型应用,特别是在训练模型阶段,往往需要花上几个小时甚至几十天的时间来训练一个模型,开启与不开启GPU往往有几十倍的性能差距。作为一名严肃的深度学习开发者,非常有必要使用一台带GPU的高性能计算机,并开启GPU支持。
那么问题来了,如何既享受Docker虚拟机带来的环境隔离的便捷,又能体验到GPU加速带来的性能提升?
有问题,自然会有人站出来提供解决方案。Nvidia公司就为自家的N卡提供了解决方案:nvidia-docker。下面就说说Nvidia的配置方案是怎样的。
声明
在开始之前作如下声明:
- 本文针对的是Nvidia显卡的配置说明,如果你用的是ATI显卡或其它品牌显卡,请出门右转找Google
- 本文针对的是Ubuntu系统的配置说明,这不表示其它操作系统就无法配置,如果你使用的是其它操作系统,请自行百度。
- 本文的实践环境是Ubuntu 16.04 64位操作系统和GTX 960显卡,其他版本的Ubuntu或者其他型号的Nvidia显卡,理论上也是适用的,但无法百分之百保证,可能有些步骤需要稍作修改。
在宿主(Host)主机上安装CUDA
CUDA(Compute Unified Device Architecture)是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
你的显卡支持CUDA吗?
首先确认一下显卡型号,在Linux系统上可以使用lspci命令:
lspci | grep VGA
01:00.0 VGA compatible controller: NVIDIA Corporation GM206 [GeForce GTX 960] (rev a1)可以看出,我的显卡型号是GeForce GTX 960,前往Nvidia的CUDA GPUs页面,可以查到,基本上所有的N卡都支持CUDA,自然我的GeForce GTX 960也支持。
安装最新的CUDA
CUDA的版本一直在更新,截至我写这篇文章的时候,最新版本是9.2。当然安装老版本也是可以的,不过我一直秉承着装新不装旧的原则,通常都会选择最新版本。
按照Nvidia的安装指导,进行如下操作:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.2.88-1_amd64.deb
sudo dpkg --install cuda-repo-ubuntu1604_9.2.88-1_amd64.deb
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub然而,在安装时提示以下错误:
gpgkeys: protocol `https' not supported解决方法也很简单,将所需的包装上:
sudo apt install gnupg-curl接下来,就可以像安装普通的ubuntu软件包那样安装cuda:
sudo apt-get update
sudo apt install cuda你可以倒杯咖啡,慢慢品尝,这个步骤可能会花一点时间,毕竟有差不多3GB的软件包需要下载。
更新环境变量
为了避免每次都设置环境变量,建议将如下环境变量设置加入到\~/.bashrc(或\~/.profile)文件中:
# for nvidia CUDA
export PATH="/usr/local/cuda-9.2/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-9.2/lib64:$LD_LIBRARY_PATH"
要让环境变量立即生效,可以先注销,然后再登录进来。或者执行如下命令:
source ~/.bashrcNVIDIA持久守护进程
这一步骤做的事情我并不是十分理解,作用大体上是即使没有客户端连接到GPU,持久守护程序也会保持GPU初始化,并保持CUDA任务的状态。文档要求这样做,我们还是照做好了。
首先新建/usr/lib/systemd/system目录:
sudo mkdir /usr/lib/systemd/system然后新增/usr/lib/systemd/system/nvidia-persistenced.service文件,其内容:
[Unit]
Description=NVIDIA Persistence Daemon
Wants=syslog.target
[Service]
Type=forking
PIDFile=/var/run/nvidia-persistenced/nvidia-persistenced.pid
Restart=always
ExecStart=/usr/bin/nvidia-persistenced --verbose
ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced
[Install]
WantedBy=multi-user.target最后启用该服务:
sudo systemctl enable nvidia-persistenced禁用某些UDEV规则
某个udev规则(物理设备和系统之间的接口)会阻止NVIDIA驱动程序正常工作。为此,编辑/lib/udev/rules.d/40-vm-hotadd.rules,注释掉memory子系统规则:
# SUBSYSTEM=="memory", ACTION=="add", DEVPATH=="/devices/system/memory/memory[0-9]*", TEST=="state", ATTR{state}="online"验证CUDA是否工作
重启机器,尝试编译CUDA示例来验证CUDA是否正常安装。可以使用如下命令安装CUDA示例代码:
cuda-install-samples-9.1.sh ~其中 ~ 代表将代码安装到HOME目录下,当然你也可以安装到别的位置。
接下来就是编译示例代码:
cd ~/NVIDIA_CUDA-9.2_Samples/
make你又可以来杯咖啡了,取决于你电脑的CPU,这一步骤可能需要几十分钟的时间。
编译完成后,运行其中的一个示例程序:
./bin/x86_64/linux/release/deviceQuery | tail -n 1如果输出Result = PASS就表示CUDA是正常工作的。
安装NVIDIA Docker
首先加入nvidia-docker包列表:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update接下来,确保你的机器上安装的是最新的docker-ce,这意味着如果你之前安装了docker-engine, docker.io,需要先卸载。别担心,这些都是docker家族的成员,只不过在不同时候取了不同的名称,最新的docker-ce是这些版本的升级版:
# remove all previous Docker versions
sudo apt-get remove docker docker-engine docker.io
# add Docker official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# Add Docker repository (for Ubuntu Xenial)
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable"
sudo apt-get update
sudo apt install docker-ce有了最新的docker,最后来安装nvidia-docker:
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd验证nvidia-docker
进行到这一步,nvidia-docker安装完毕,那如何检验nvidia-docker正确安装了呢?
我们可以启动nvidia提供的docker镜像,里面有一个实用程序nvidia-smi,它用来监视(并管理)GPU:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi如果得到形如如下的输出,就说明docker容器GPU已经启用。
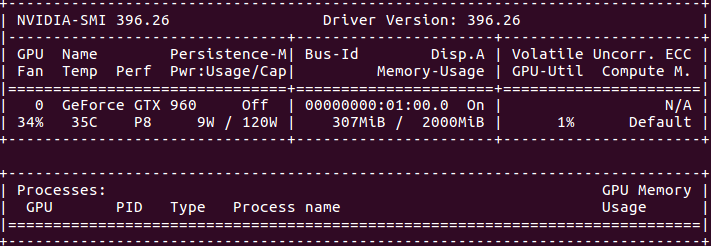
你还可以做一个测试,看看CPU与GPU之间到底有多大的差距。下面是一段来自learningtensorflow.com的基准测试脚本:
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
# It can be hard to see the results on the terminal with lots of output -- add some newlines to improve readability.
print("\n" * 5)
print("Shape:", shape, "Device:", device_name)
print("Time taken:", str(datetime.now() - startTime))在当前目录下创建内容如上的python文件:benchmark.py,然后启动支持GPU的tensorflow docker镜像,运行该tensorflow程序:
docker run \
--runtime=nvidia \
--rm \
-ti \
-v "${PWD}:/app" \
tensorflow/tensorflow:latest-gpu \
python /app/benchmark.py cpu 10000上面的命令是CPU版本的,运行完之后,将命令中的cpu参数修改为gpu,再运行一次。
在我的机器上,结果分别为:
CPU: ('Time taken:', '0:00:15.342611')
GPU: ('Time taken:', '0:00:02.957479')也许你会觉得就十几秒的差距,也没啥?要知道,这可是差不多7倍的差距。加入你的深度学习项目采用GPU需要24个小时,那么不启用GPU则需要一周的时间,这个还是有着巨大的差距的。
参考
- Using NVIDIA GPU within Docker Containers
- CUDA Quick Start Guide
- NVIDIA Container Runtime for Docker
- Docker for Ubuntu
