Bottom-Up Abstractive Summarization
【文章来源】
Gehrmann S, Deng Y, Rush A M. Bottom-Up Abstractive Summarization[J]. 2018.
【原文链接】
自底向上的摘要式的总结:https://arxiv.org/pdf/1808.10792v1.pdf
基于神经网络的抽象摘要方法产生的输出比其他技术更流畅,但在内容选择上表现不佳。这项工作本文提出了一种解决此问题的简单技术:使用数据有效的内容选择器来过度确定源文档中应成为摘要一部分的短语。我们使用此选择器作为自下而上的注意步骤,将模型约束为可能的短语。我们表明,这种方法提高了压缩文本的能力,同时仍能生成流畅的摘要。这个两步流程比其他端到端内容选择模型更简单,性能更高,从而在CNN-DM和NYT语料库中显着改善了ROUGE 。此外,内容选择器可以只用1,000个句子进行训练,从而可以轻松地将训练有素的摘要器转移到新的领域。
1 介绍
文本摘要系统旨在生成以较长文本压缩信息的自然语言摘要。使用神经网络的方法已经在这个任务上展示了有希的结果,通过端到端模型对源文档进行编码,然后将其解码为抽象的摘要。 当前最先进的神经抽象摘要模型通过使用可以从源文档复制单词的指针生成器样式模型来组合提取和抽象技术(Gu等人,2016; See等人,2017)。这些端到端模型产生了流畅的抽象摘要,但与完全提取模型相比,它们在内容选择(即决定总结内容)方面取得了好坏参半的成功。
从建模角度来看,端到端模型具有吸引力; 然而,有证据表明,在总结时,人们遵循两步方法,首先选择重要的短语,然后解释它们(Anderson和Hidi,1988; Jing和McKeown,1999)。对图像字幕进行了类似的论证。对于图像字幕也有类似的争论。Anderson等人(2017)开发了一种最先进的模型,采用两步法,首先预计算分段对象的边界盒,然后将注意力放在这些区域。这种所谓的自下而上的注意力是受神经科学研究的启发,该研究描述了基于刺激固有属性的注意力(Buschman和Miller, 2007)。
基于这种方法,我们考虑将自下而上的注意力作为神经抽象摘要。我们的方法首先为源文档选择一个选择掩码,然后通过该掩码约束标准神经模型。这种方法可以更好地决定模型应该在摘要中包含哪些短语,而不会牺牲神经抽象摘要器的流畅性优势。此外,它需要更少的数据来训练,因而也更适应新的领域。
我们的完整模型包含一个独立的内容选择系统,以决定源文档的相关方面。我们将这个选择任务框定为序列标记问题,目标是从文档中识别作为其摘要一部分的标记。我们展示了基于上下文词嵌入的内容选择模型(Peters等, 2018)可以识别正确的令牌,召回率超过60%,精度超过50%。为了将自下而上的注意力结合到抽象概括模型中,我们采用掩蔽法来将单词复制到文本的选定部分,从而产生语法输出。我们还尝试了多种方法,通过多任务学习或直接结合完全可区分的掩模,将类似的约束结合到更复杂的端到端抽象概括模型的训练过程中。
 图1 两个句子摘要的示例,有和没有自下而上的注意。 该模型不允许复制[灰色]中的单词,尽管它可以生成单词。 随着自下而上的注意,我们看到更明确的句子压缩,而没有它的话整个句子将被逐字复制。
图1 两个句子摘要的示例,有和没有自下而上的注意。 该模型不允许复制[灰色]中的单词,尽管它可以生成单词。 随着自下而上的注意,我们看到更明确的句子压缩,而没有它的话整个句子将被逐字复制。
我们的实验将自下而上的注意力与其他一些最先进的抽象系统进行了比较。与See等人(2017)的基线模型相比,自下而上的关注使得CNN-Daily Mail(CNN-DM)语料库的ROUGE-L得分从36.4提高到38.3,同时训练更简单。我们也看到了与我们的MLE训练系统相比,最近使用的基于强化学习的方法相近或更好的结果。此外,我们发现内容选择模型具有非常高的数据效率,并且可以使用少于原始训练数据的1%进行训练。这为域转移和低资源汇总提供了机会。我们证明了在CNN-DM上训练和在NYT语料库上评估的摘要模型在ROUGE-L上可以提高5分以上,其中内容选择器仅在1,000个域内句子中进行训练。
2 相关工作
在文档摘要中,在靠近源文档和允许压缩或抽象修改之间存在一种矛盾。许多非神经系统采用选择和压缩方法。例如,Dorr等人(2003)提出了一种系统,它首先从新闻文章的第一句话中提取名词和动词短语,然后使用迭代缩短算法对其进行压缩。最近的系统,如Durrett等人(2016)也学习了一个模型来选择句子,然后压缩它们。
相比之下,最近基于神经网络的数据驱动提取摘要的工作主要集中在提取和排序完整句子上(Cheng和Lapata,2016; Dlikman和Last,2016)。 Nallapati等(2016b)使用分类器来确定是否包括对正分类的那些进行排名的句子和选择器。这些方法经常过度提取,但在单词级别提取需要保持语法正确的输出(Cheng和Lapata,2016),这很困难。有趣的是,关键短语提取虽然不符合语法规则,但在内容上经常与人工生成的摘要紧密匹配(Bui et al,2016)。
第三种方法是具有序列到序列模型的神经抽象概括(Sutskever等,2014; Bahdanau等,2014)。这些方法已应用于诸如标题生成(Rush等,2015)和文章摘要(Nallapati等,2016a)等任务。Chopra等(2016)表明,更具体的摘要注意方法可以进一步提高模型的性能。Gu et al.(2016)首次证明了Vinyals et al.(2015)引入的复制机制可以通过从源中复制单词,结合提取和抽象摘要的优点。See等 (2017)改进这种指针生成器方法并使用额外的覆盖机制(Tu et al。,2016),使模型知道其注意历史以防止重复注意。
最近,强化学习(RL)方法优化了除最大似然之外的总结目标,已经证明可以进一步提高这些任务的性能(Paulus等,2017; Li等,2018b; Celikyilmaz等,2018) 。Paulus等人(2017)通过内部注意机制来处理覆盖问题,其中解码器关注先前生成的单词。然而,基于RL的训练可能难以调整并且难以训练。我们的方法不使用RL训练,尽管在理论上这种方法可以适用于RL方法。
一些论文还探讨了多遍提取—抽象概括。 Nallapati等(2017)创建一个新的源文档,由源文件中的重要句子组成,然后训练一个抽象系统。Liu et al.(2018)描述了提取完整段落的阶段和决定其顺序的抽象阶段。最后,Zeng等人(2016)介绍了一种机制,在两次传递中读取源文档,使用第一次传递的信息对第二次传递的信息进行偏置。我们的方法的不同之处在于我们使用完全抽象的模型,偏向于强大的内容选择器。
最近的其他工作探讨了内容选择的替代方法。例如,Cohan等人(2018)使用分层注意来检测文档中的相关部分,Li等人(2018a)生成用于指导摘要过程的一组关键字,并且Pasunuru和Bansal(2018)基于显着关键字是否包括在摘要中来开发损失函数。其他方法调查句子级别的内容选择。 Tan等人(2017)描述了一个基于图表的注意力,一次只关注一个句子,Chen和Bansal(2018)首先从文档中提取完整的句子然后压缩它们,而Hsu等人(2018)基于句子包括在摘要中的可能性来调节注意力。
3 背景:神经总结
在本文中,我们考虑一组文本对![]() ,其中
,其中![]() 对应于源令牌
对应于源令牌![]() ,
,![]() 对应到摘要
对应到摘要![]() ,其中
,其中![]() 。 抽象摘要一次生成一个单词。 在每个时间步,模型都知道先前生成的单词。 问题是学习由θ参数化的函数
。 抽象摘要一次生成一个单词。 在每个时间步,模型都知道先前生成的单词。 问题是学习由θ参数化的函数![]() ,其最大化生成正确序列的概率。在之前的工作之后,我们使用注意力序列到序列模型对抽象概括进行建模。在神经网络内计算的用于解码步骤j的关注分布
,其最大化生成正确序列的概率。在之前的工作之后,我们使用注意力序列到序列模型对抽象概括进行建模。在神经网络内计算的用于解码步骤j的关注分布![]() 表示在所有源令牌上的嵌入式软分布,并且可以被解释为模型的当前焦点。
表示在所有源令牌上的嵌入式软分布,并且可以被解释为模型的当前焦点。
该模型还具有复制机制(Vinyals等,2015),以复制来自源的单词。 复制模型通过预测确定模型是复制还是生成的二进制软开关zj来扩展解码器。 复制分布是源文本上的概率分布,联合分布被计算为模型的两个部分的凸组合,
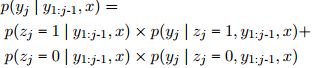
其中,两部分分别表示复制和生成分发。遵循See等人的指针生成器模型,我们再次使用了注意力分布作为复制分布,即通过复制注意力在源w中的令牌的复制概率被计算为对所有w的出现的注意力的总和。在训练期间,我们使用潜在开关变量最大化边际可能性。
4 从底向上注意
 图2 第4节中描述的选择和生成过程概述
图2 第4节中描述的选择和生成过程概述
接下来我们将考虑将内容选择合并到抽象摘要中的技术,如图2所示。
4.1内容选择
我们将内容选择问题定义为词汇级提取摘要任务。虽然在自定义提取摘要方面做了大量工作(参见相关工作),但我们做了一个简化的假设并将其视为序列标记问题。设![]() 表示每个源令牌的二进制标签,即如果在目标序列中复制一个字则为1,否则为0。
表示每个源令牌的二进制标签,即如果在目标序列中复制一个字则为1,否则为0。
虽然此任务没有监督数据,但我们可以通过将摘要与文档对齐来生成训练数据。我们将一个单词xi定义为复制,如果(1)它是标记的最长可能子序列的一部分![]() ,对于整数
,对于整数![]() ,如果
,如果![]() ;(2)若不存在先前的序列u,其中s = u。
;(2)若不存在先前的序列u,其中s = u。
我们使用标准Bi-LSTM模型训练最大似然序列标记问题。最近的结果表明,更好的单词表示可以显着改善序列标记任务的性能(Peters等,2017)。因此,我们首先将每个标记wi映射到两个嵌入通道![]() 和
和![]() 中。
中。![]() 表示预训练的字嵌入的静态信道,例如, GLoVE(Pennington等,2014)。
表示预训练的字嵌入的静态信道,例如, GLoVE(Pennington等,2014)。![]() 是来自预训练语言模型的上下文嵌入,例如, ELMo(Peters等人,2018),它使用一个字符感知令牌嵌入(Kim et al., 2016),后面是两个双向LSTM层
是来自预训练语言模型的上下文嵌入,例如, ELMo(Peters等人,2018),它使用一个字符感知令牌嵌入(Kim et al., 2016),后面是两个双向LSTM层![]() 和
和![]() 。上下文嵌入被微调以学习特定于任务的嵌入
。上下文嵌入被微调以学习特定于任务的嵌入![]() 作为每个LSTM层的状态和令牌嵌入的线性组合,
作为每个LSTM层的状态和令牌嵌入的线性组合,

用γ和作为可训练参数。由于这些嵌入仅向标记器添加了四个附加参数,因此尽管具有高维嵌入空间,但它仍然具有非常高的数据效率。 两个嵌入都连接成单个向量,该向量用作Bi-LSTM的输入,Bi-LSTM计算单词wi的表示hi。 然后我们可以用训练参数Ws和bs计算选择该词作为的概率qi。
4.2自下而上复制注意
受到图像自下而上关注工作的启发(Anderson等,2017),它限制了对图像中预定边界框的注意,我们使用这些注意掩模来限制指针生成器模型的可用选择。
如图1所示,神经复制模型的一个常见错误是复制很长的序列甚至整个句子。在基线模型中,超过50%的复制令牌是超过10个令牌的复制序列的一部分,而参考摘要的此数字仅为10%。虽然自下而上的注意力也可用于修改源编码器表示,但我们发现全文上的标准编码器在聚合时是有效的,因此限制了自下而上的步骤以注意屏蔽。
具体地说,我们首先在完整数据集以及上面定义的内容选择器上训练指针生成器模型。在推理时,为了生成掩码,内容选择器为源文档中的每个标记计算选择概率q1:n。选择概率用于修改复制关注分布以仅包括由选择器标识的标记。令aij表示解码步骤j对编码器字i的注意。给定阈值α,选择被应用为硬掩模,使得
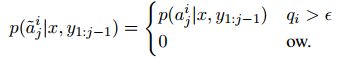
为了确保方程式1仍然产生正确的概率分布,我们首先将乘以归一化参数λ,然后重新归一化分布。得到的归一化分布可用于直接替换a作为新的复制概率。
4.3端到端替代方案
两步自底向上注意力具有培训简单性的优点。但理论上,标准的复制注意应该能够学习如何作为端到端培训的一部分执行内容选择。我们考虑了其他一些端到端方法,将内容选择合并到神经训练中。
方法1(仅限MASK):我们首先考虑自下而上方法中使用的对齐是否有助于标准摘要系统。受Nallapati等人(2017)的启发,我们研究在培训过程中调整摘要和来源,固定黄金副本注意选择“正确”的来源词是否有益。我我们可以将这种方法看作是将一组可能的副本限制为一个固定的源单词。在这里训练被改变,但是在测试的时候没有使用任何掩码。
方法2(MULTI-TASK):接下来,我们研究内容选择器是否可以与抽象系统一起训练。我们首先通过将摘要作为一个多任务问题进行测试并使用相同的特征训练标记器和摘要模型来测试该假设。对于此设置,我们使用共享编码器进行抽象摘要和内容选择。在测试时,我们应该使用相同的掩蔽方法作为自下而上的注意力。
方法3(DIFFMASK):最后我们考虑在训练期间使用面罩端对端地训练整个系统。在这里,我们联合优化两个目标,但使用预测的选择概率轻柔地掩盖复制注意力,这导致一个完全可微的模型。该模型在测试时使用相同的软掩模。
5 推论
一些作者已经注意到,较长形式的神经生成仍然存在长度不正确和重复单词的重要问题,而不是像翻译这样的短期问题。提出的解决方案包括修改具有扩展的模型,例如覆盖机制(Tu等,2016; See等,2017)或句内注意(Cheng等,2016; Paulus等,2017)。我们坚持修改推理的主题,并修改评分函数以包括长度惩罚lp和覆盖惩罚cp,并定义为![]() 。
。
长度:为了鼓励生成更长的序列,我们在波束搜索期间应用长度归一化。我们使用Wu等人(2016)的长度惩罚。其公式为:
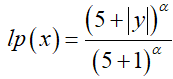
使用可调参数α,其中增加α会导致更长的摘要。我们还根据训练数据设置了最小长度。
重复:复制模型经常重复使用相同的源令牌,多次生成相同的短语。我们引入一个新的总结特定覆盖惩罚,
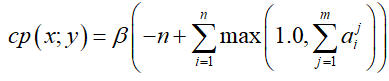
直观地,只要解码器将序列内的总注意力超过1.0指向单个编码令牌,该惩罚就会增加。通过选择足够高的β,这种惩罚会阻止摘要,只要它们会导致重复。此外,我们遵循(Paulus等,2017),并将光束搜索限制在不再重复三元组。
6 数据和实验
我们在CNN-DM语料库中评估我们的方法(Hermann et al., 2015;Nallapati等人,2016a)和纽约时报语料库NYT(Sandhaus, 2008),都是新闻摘要的标准语料库。CNN-DM语料库的摘要是各自网站上显示的文章的要点,而NYT语料库包含图书馆科学家编写的摘要。 CNN-DM摘要是完整的句子,平均66个令牌(σ = 26)和4.9个要点。 NYT摘要并不总是完整的句子而且更短,平均有40个令牌(σ = 27)和1.9个要点。在培训和验证集中,我们使用CNN-DM语料库的非匿名版本,将源文档截断为400个令牌,目标摘要为100个令牌。对于使用NYT语料库的实验,我们使用Paulus等人(2017)描述的预处理,另外删除作者信息,将源文档截断为400个令牌,而不是800个。这些更改导致每篇文章平均使用326个标记,比使用800个标记截断的文章的549个标记有所减少。目标(非复制)词汇表限制为所有模型的50,000个令牌。
内容选择模型使用大小为100的预训练GloVe嵌入和大小为1024的ELMo,Bi-LSTM有两层,隐藏大小为256,Dropout设置为0.5,模型用Adagrad训练,初始化学习率为0.15,初始累加器值为0.1。我们将两个语料库的训练示例数量限制在10万个,这对性能的影响很小。对于联合训练的内容选择模型,我们使用与抽象模型相同的配置。
对于基本模型,我们重新实现了如See等人(2017年)所述的Pointer-Generator模型。为了获得与以前工作相当数量的参数,我们在一层LSTM中使用了一个包含256个隐藏状态的编码器,而在一层解码器中使用了512个隐藏状态。嵌入大小设置为128。使用与内容选择器相同的Adagrad配置训练模型。此外,一旦验证困惑在一个时期之后没有减少,学习速率在每个时期之后都减半。我们不使用压差并使用最大范数为2的梯度削波。我们发现增加模型尺寸或使用变压器(Vaswani等,2017)可以导致性能略有提高,但代价是增加了培训时间和参数。我们报告具有复制注意的变压器的数量,我们称其为CopyTransformer。在这个模型中,我们随机选择一个注意头作为复制分布,或者按照Vaswani等人(2017)的大变压器参数。
所有推理参数都在验证集的200个示例子集上进行调整。长度惩罚参数α和复制掩码ε的各种型号不同,α范围从0.6-1.4,ε范围从0.1-0.2。 CNN-DM的生成摘要的最小长度设置为35,NYT的最小长度设置为6。虽然指针生成器使用5的光束尺寸并且没有用更大的光束改善,但我们发现自下而上的注意力需要更大的光束尺寸10。覆盖惩罚参数β被设置为10,并且复制注意力归一化两种方法的参数λ为2。我们使用AllenNLP(Gardner等,2018)作为内容选择器,使用OpenNMT-py作为抽象模型(Klein et al,2017)。
7 结果
表1显示了我们在CNNDM语料库中的主要结果,上面显示了抽象模型,下面显示了自底向上的注意方法。我们首先观察到,使用覆盖推断惩罚与完全覆盖机制得分相同,而不需要任何额外的模型参数或模型微调。使用CopyTransformer和覆盖率惩罚的结果表明所有三个分数都略有改善,但我们观察到Pointer-Generator和具有自底向上注意的CopyTransformer没有显著差异。
 表1 CNN-DM数据集上抽象摘要的结果。 第一部分显示了用交叉熵训练的编码器 - 解码器抽象基线。 第二部分描述了基于强化学习的方法。 第三部分介绍了我们的基线和本工作中描述的注意力掩蔽方法。
表1 CNN-DM数据集上抽象摘要的结果。 第一部分显示了用交叉熵训练的编码器 - 解码器抽象基线。 第二部分描述了基于强化学习的方法。 第三部分介绍了我们的基线和本工作中描述的注意力掩蔽方法。
我们发现,我们的端到端模型都没有导致改进,这表明在训练期间应用掩蔽很难不会损害训练过程。仅对Mask模型具有更强的复制机制监控功能,与MultiTask模型非常相似。另一方面,自下而上的注意力导致所有三个分数的重大改善。虽然我们希望更好的内容选择能主要提高ROUGE-1,但这三种内容的增加都暗示了流畅性并没有受到特别的影响。我们的交叉熵训练方法甚至优于ROUGE-1和2中所有基于强化学习的方法,而Chen和Bansal(2018)报告的最高ROUGE-L得分落在我们结果的95%置信区间内。
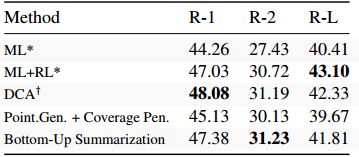 表2 NYT语料库的结果,我们将其与RL训练的模型进行比较。*标记Paulus等人(2017)的模型和结果,Celikyilmaz等人(2018)的y结果。
表2 NYT语料库的结果,我们将其与RL训练的模型进行比较。*标记Paulus等人(2017)的模型和结果,Celikyilmaz等人(2018)的y结果。
表2显示了在NYT语料库中使用相同系统的实验。我们看到,与基线PointerGenerator最大似然方法相比,2点改进延续到此数据集。在这里,该模型优于Paulus等人(2017)的基于RL的模型。在ROUGE-1和2中,但不是L,并且与ROUGE-L除外(Celikyilmaz等,2018)的结果相当。比较ML和我们的指针生成器时可以观察到相同的情况。我们怀疑由于我们的推理参数选择导致的摘要长度的差异导致了这种差异,但是无法访问他们的模型或摘要来调查此声明。这表明,自下而上的方法即使对于针对概要特定目标进行培训的模型也能获得有竞争力的结果。
自下而上摘要的主要好处似乎来自减少错误复制的单词。使用最佳的Pointer-Generator模型,复制单词的精度与参考精度的50.0%相比,这种精度提高到52.8%,这在很大程度上推动了R1的增长。独立样本t检验显示,这种改善在时具有统计学意义。我们还观察到,与指针生成器相比,添加内容选择时,摘要的平均句子长度从13个字减少到12个字,同时保持所有其他推理参数不变。
域名转移虽然端到端培训
已经变得普遍,两步法有好处。由于内容选择器只需要解决预训练向量的二进制标记问题,即使训练数据非常有限,它也能很好地运行。如图3所示,只有1000个句子,模型的AUC大于74。除此之外,模型的AUC随着训练数据的增加而略有增加。
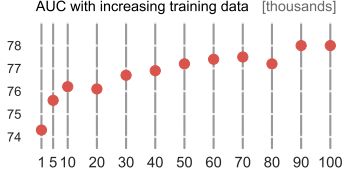 图3 内容选择器的AUC在CNN-DM上训练,不同的训练集大小从1000到100000个数据点。
图3 内容选择器的AUC在CNN-DM上训练,不同的训练集大小从1000到100000个数据点。
为了进一步评估内容选择,我们考虑应用于域名转移。在本实验中,我们将在CNN-DM上训练的指针生成器应用于NYT语料库。此外,我们在NYT集的1,10和10万个句子中训练三个内容选择器,并在自下而上的摘要中使用它们。表3中显示的结果表明,即使是在最小子集上训练的模型也可以比模型提高近5个点,而没有自下而上的关注。这种改进随着较大的子集而增加,最多可达7个点。
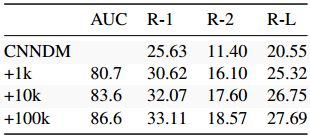 表3 域转移实验的结果。显示内容选择器的AUC号码。 ROUGE分数代表在CNN-DM上训练并在NYT上评估的抽象模型,其中附加的复制约束训练在NYT语料库的1/10 / 100k训练样本上。
表3 域转移实验的结果。显示内容选择器的AUC号码。 ROUGE分数代表在CNN-DM上训练并在NYT上评估的抽象模型,其中附加的复制约束训练在NYT语料库的1/10 / 100k训练样本上。
虽然这种方法没有达到与直接在NYT数据集上训练的模型相当的性能,但它仍然代表了未增加的CNN-DM模型的显着增加,并产生了相当可读的摘要。我们在附录A中展示了两个示例摘要。该技术可用于低资源域和有限数据可用性的问题。
8 分析和讨论
内容选择的摘录摘要?
鉴于内容选择器与抽象模型相结合是有效的,了解它自己是否学会了一种有效的提取摘要系统是很有趣的。表4显示了将内容选择与提取基线进行比较的实验。 LEAD-3基线是新闻摘要中常用的基线,它从文章中提取前三个句子。前3个显示了当我们从选择器中通过平均复制概率提取前三个句子时的性能。有趣的是,使用这种方法,前三个句子中只有7.1%不在前三个范围内,进一步增强了LEAD-3基线的强度。我们的天真句子提取器的表现略差于周等人(2018)所报道的最高报告的提取分数,该分数专门用于评分句子组合。最后一个条目显示了当所有超过阈值的单词被提取出来时的性能,这样得到的摘要大约是引用摘要的长度。
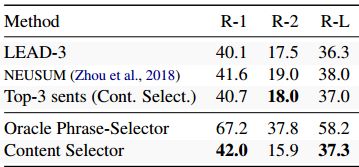 表4 CNN-DM数据集的提取方法结果。第一部分显示了句子提取分数。如果内容选择器根据我们的匹配启发式选择了所有正确的单词,那么第二部分首先显示oracle得分。最后,我们显示当内容选择器提取所有超过选择概率阈值的短语时的结果。
表4 CNN-DM数据集的提取方法结果。第一部分显示了句子提取分数。如果内容选择器根据我们的匹配启发式选择了所有正确的单词,那么第二部分首先显示oracle得分。最后,我们显示当内容选择器提取所有超过选择概率阈值的短语时的结果。
如果我们的模型具有完美的准确性,oracle得分代表结果,并且表明内容选择器在产生竞争结果的同时,在未来的工作中有进一步改进的空间。这个结果表明该模型在找到重要单词(ROUGE-1)方面非常有效,但在将它们链接在一起效果较差(ROUGE-2)。与Paulus等人(2017)类似,我们发现ROUGE-2的减少表明生成的摘要缺乏流畅性和语法性。典型示例如下所示:
a man food his first hamburger wrongfully for 36 years. michael hanline, 69, was convicted of murder for the shooting of truck driver jt mcgarry in 1980 on judge charges.
这个特殊的不合语法的例子的ROUGE-1为29.3。这进一步突出了组合方法的好处,其中自下而上预测通过抽象系统流畅地链接在一起。但是,我们还注意到抽象系统需要访问完整的源文档。我们尝试使用内容选择的输出作为抽象模型的训练输入的蒸馏实验表明模型性能急剧下降。
复制分析
虽然Pointer-Generator模型具有抽象摘要的能力,但复制机制的使用导致摘要主要是提取的。表5显示,通过复制,不在源文档中的生成单词的百分比从6.6%降低到2.2%,而参考摘要更加抽象,14.8%的新单词。自下而上的注意力进一步减少到只有百分之五。然而,由于生成的摘要通常不超过40-50个单词,因此有和没有自下而上注意的抽象系统之间的差异小于每个摘要的一个新单词。这表明抽象模型的好处在于它们产生更好的释义的能力较少,但更多的是能够从大多数提取过程中创建流畅的摘要。
 表5 %Novel显示摘要中不在源文档中的单词百分比。 最后三列显示了生成的摘要中的新词的词性标签分布。
表5 %Novel显示摘要中不在源文档中的单词百分比。 最后三列显示了生成的摘要中的新词的词性标签分布。
表5还显示了新生成词的词性标签,我们可以观察到有趣的效果。自下而上注意力的应用导致新形容词和名词的急剧减少,而动词新词的比例急剧增加。在查看正在生成的新动词时,我们注意到非常高的时态或数字变化百分比,由“说”这个词的变化表示,例如“说”或“说”,而新名词主要是形态变体源中的单词。
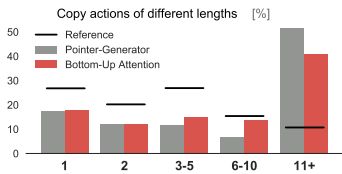 图4 对于所有复制的单词,我们显示了它们所属的复制短语长度的分布。 黑色线条表示参考摘要,条形图摘要有和没有自下而上的注意。
图4 对于所有复制的单词,我们显示了它们所属的复制短语长度的分布。 黑色线条表示参考摘要,条形图摘要有和没有自下而上的注意。
图4显示了正在复制的短语的长度。虽然参考摘要中的大多数复制短语都是1到5个单词的组,但是指针生成器复制了许多非常长的序列和超过11个单词的完整句子。由于内容选择掩码中断了大多数长拷贝序列,因此模型必须仅使用生成概率生成未选择的单词,或者使用不同的单词。虽然我们在生成的摘要中经常观察到这两种情况,但非常长的复制短语的比例会减少。然而,无论是否有自下而上的注意,复制短语的长度分布仍然与参考完全不同。
推理惩罚分析
我们接下来分析推理时间损失函数的影响。表6显示了在一次添加一个惩罚时简单指针生成器的边际改进。我们观察到,即使在其他两个分数之上添加,所有三个分数都会提高所有三个分数。这进一步表明未修改的指针生成器模型已经学习了抽象概括问题的适当表示,但受其无效内容选择和推理方法的限制。
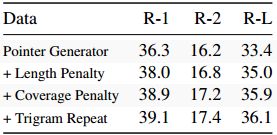 表6 CNN-DM在每次添加一个推理惩罚时的结果。
表6 CNN-DM在每次添加一个推理惩罚时的结果。
9 结论
这项工作提供了一个简单但准确的摘要内容选择模型,用于识别文档中可能包含在摘要中的短语。我们发现这个内容选择器可以用于自下而上的注意,限制抽象摘要器从源复制单词的能力。自下而上的综合摘要系统导致CNN-DM和NYT语料库的ROUGE得分均超过两分。与端到端训练方法的比较表明,这个特定问题不能用单个模型轻易解决,而是需要微调推理限制。最后,我们发现这种技术由于其数据效率,可用于调整具有少量数据点的训练模型,从而可以轻松地转移到新域。在需要内容选择的其他领域(如语法修正或数据到文本生成)中研究类似的自下而上方法的初步工作已显示出一些前景,并将在未来的工作中进行调查。