9. 深度学习实践:卷积网络
卷积神经网络,Convolutional Neural Network,CNN
卷积网络:至少在网络的一层中使用了卷积运算来替代一般的矩阵乘法运算的NN。
1. 卷积运算
用计算机处理数据时,时间会被离散化,则为求和形式:
s(t)=(x∗w)(t)=∑∞a=−∞x(a)w(t−a)
x 通常是多维数组的输入。 w 是核函数(卷积核),通常由学习算法优化得到。输出也称特征映射(feature map)。
2维卷积的例子如图,滑动平移窗口,对应元素相乘总相加,可以看做是一种特殊的矩阵乘法:
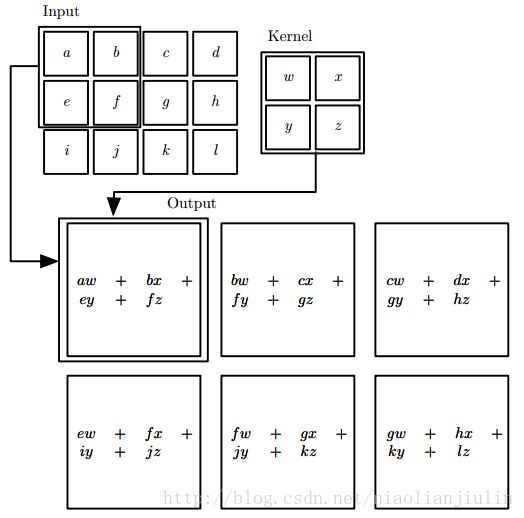
2. 动机
卷积运算的三个重要特点,帮助改进ML系统:
- 稀疏交互
- 参数共享
- 等变表示
2.1 稀疏表示
亦称稀疏连接,或稀疏权重。使核的大小远小于输入的大小来达到。
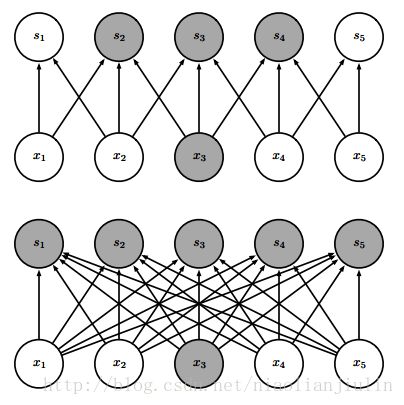
这个图从下往上看,下方是s由矩阵乘法产生,一个输入单元x3会供应所有输出,与所有都连接,所有输出都会受到x3的影响。上方是s由核宽度为3的卷积产生,只有3个输出与x3输入相连。强调输入单元。
假设m个输入,n个输出。矩阵乘法需要mn个参数。若限制每个输出的连接数为k(核宽度),则需要kn个参数。
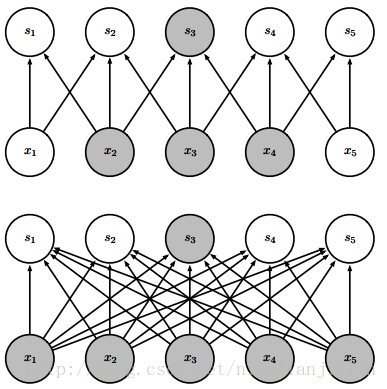
这个图从上往下看。上面s3输出来自于3个输入,这三个单元被称为s3的 感受野(receptive field)。下面s3输出来自于所有输入。强调输出单元。
深度卷积网路中,网络深层的单元可能与绝大多数输入是间接交互的,如图所示:
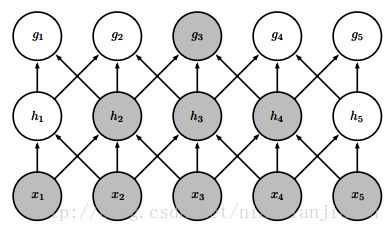
深层的g3的感受野,比h3等中层的感受野大。若包含步幅卷积或池化之类的结构,效应会更强。这意味着:尽管CNN中连接很稀疏,但deep层的单元可间接地连接到全部或大部分输入图像。
2.2 参数共享
一个模型中的多个函数中使用相同的参数。传统NN中,当计算一层的输出时,权重矩阵的每个权重元素仅用一次。CNN中,核的每一个元素都作用在输入的每一个位置上(核跳着给每个输入都上一遍)。参数共享没有改变前向传播的时间,但显著降低了模型存储和统计效率。如图示:
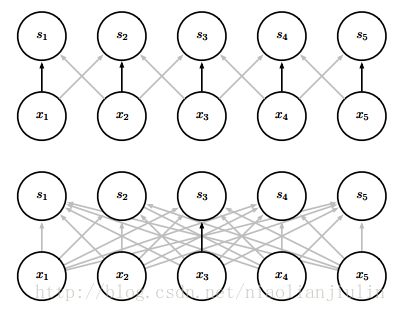
上面的总共3个参数,滑动着给每个输入都上一遍。下面的总共25个参数。下图说明了稀疏连接和参数共享是如何显著提高线性函数在一张图上进行边缘检测的效率的:

卷积核为 -11 。输入为320*280,输出为319*280。该卷积滑动一遍给出了输入图中所有垂直方向带上的边缘的强度。使用卷积:319*280*3=267960次浮点运算(2个乘法1个加法)。为了用矩阵描述相同的变换,需要(320*280)*(319*280)个元素的矩阵(大多数元素为0)。
将小的局部区域上的相同线性变换,应用到整个输入上,卷积是描述这种变换的极其有效的方法。
2.3 等变表示
如果一个函数满足:输入改变,输出也以同样的方式改变,这一性质,就说它是等变的(equivariant)。特别地,对于卷积函数 f(x) ,平移函数 g(x) ,有 f(g(x))=g(f(x)) 。先平移再卷积,先卷积再平移,效果是一样的。因为参数共享的特殊形式使然,迟早都要被卷积下。卷积对其他一些变换并不是天然等变的,例如图像缩放或旋转等。
3. 池化
池化函数使用某一位置的相邻输出的总体统计特征,来代替网络在该位置的输出。例如,最大池化函数,给出相邻矩阵区域的最大值。
当我们对输入进行少量平移时,经过池化函数后的大多数输出,并不会发生改变。图示:
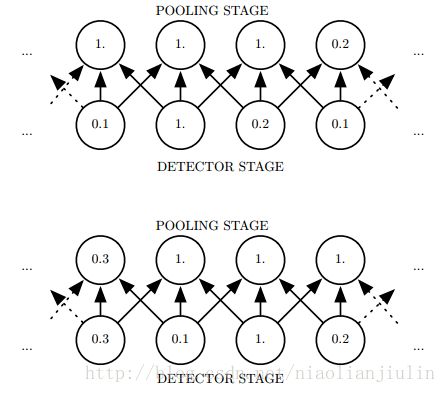
局部平移不变性,是一个很有用的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时。例如,判断一张图是否包含人脸,并不需要知道眼睛的具体位置,只需要知道一只眼在左边,一只眼在右边。
池化能帮助输入的表示近似不变。如图,下面一行的所有值都发生了改变,但上面一行只有一半的值改变。因为最大池化单元只对周围的最大值比较敏感,而不是对精确的位置。
降采样的池化,使得表示的大小减少,减轻了下一层的计算和统计负担。
4. 卷积与池化:无限强的先验
先验概率分布:模型参数的概率分布,刻画了我们看到数据之前,我们认为什么样的模型是合理的信念。先验,强或者弱,取决于先验中概率密度的集中程度。弱先验,具有较高熵值,例如方差很大的高斯分布,允许数据对于参数的改变具有或多或少的自由性。强先验,具有较低熵值,例如方差很小的高斯分布,在决定参数取得最终值时,起着更加积极作用。
无限强的先验,需要对一些参数的概率置零,并且完全禁止对这些参数赋值。可以把卷积网络想象成一个全连接网络,但对其权重有无限强的先验:一个隐藏单元的权重必须和它邻居的权重相同,但可以在空间中移动,大部分权重为0(没连接可以认为就是0嘛)。该先验说明了:该层应该学的函数只包含局部连接关系,并且对平移具有等变性。池化的先验说明了:我们期望该层的每一个单元都具有对少量平移的不变性。
这个想象的一个启发是:卷积和池化可能导致欠拟合。若一项任务依赖于保存精确的空间信息,则所有特征上池化将会增大训练误差。若一项任务中涉及到要对输入中相隔较远的信息进行合并时,那么卷积利用的先验就不正确了。
5. 基本卷积函数的变体
(1)NN中的卷积,通常是指由多个并行卷积组成的运算。一个卷积提取一种特征。我们希望网络每一层能够在多个位置提取多种类型的特征。
(2)有时希望跳过核中的一些位置,降低计算开销,当然特征没有之前好。可看做是对全卷积函数输出的下采样。下采样卷积的步幅,隔多久采一个。
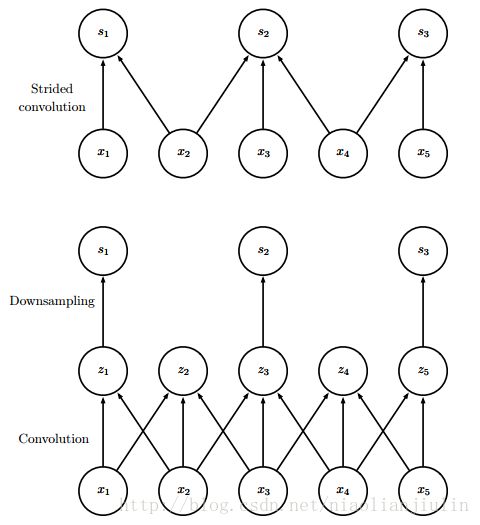
图上部是直接做步幅为2的卷积。图下部是先做单位步幅的卷积,随后降采样。二者的输入输出等价。
(3)零填充。不零填充,则每一层就会缩减。
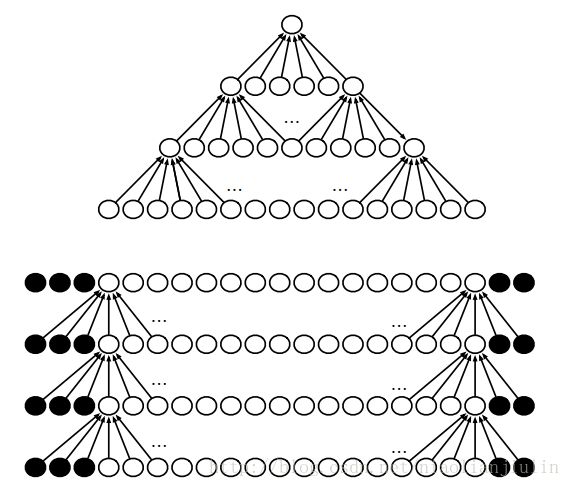
(4)非共享卷积(unshared convolutional)。有时并非想真用卷积,而是一些 局部连接 的网络层。和具有一个小核的离散卷积很像,但并不横跨位置来共享参数。
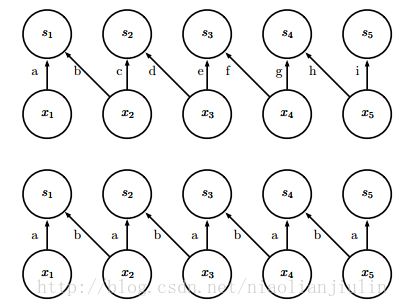
上半部分的感受野有两个像素的局部连接层。下半部分为卷积层。区别在于参数共享上。当我们知道每一个特征都是一小块空间的函数,并且相同的特征不会出现在所有空间上时,局部连接层很有用。例如,我们想要辨别一张图片是否是人脸图像时,只需要去寻找嘴是否再图像下半部即可。
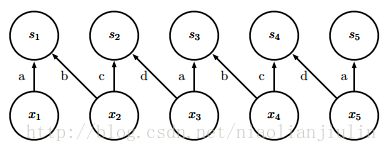
平铺卷积(tiled convolutional):对卷积层和局部连接层的折中。
(5)实现卷积网络时,通常也需要除卷积外的其他运算。卷积是一种线性运算,可表示成矩阵乘法的形式,其中包含的矩阵是关于卷积核的函数。该矩阵稀疏(仅核宽度连,其他为0的表示不连),且核的每个元素都复制给矩阵的多个元素。
这种观点可帮助我们导出实现一个卷积网络所需的很多其他运算。例如,通过卷积定义的矩阵转置的乘法,可用在卷积层反向传播误差的导数计算上。若想要从隐藏层单元重构可视化单元时,同样的运算也需要。