【强化学习】使用off-policy算法机器人抓取任务基准;生成对抗网络 GAN 就是强化学习

本文转自雷克世界(ID:raicworld)
编译 | 嗯~阿童木呀
在本文中,我们探讨了用于基于视觉的机器人抓取操作的深度强化学习算法。无模型深度强化学习(RL)已经在一系列具有挑战性的环境中得到了成功应用,但算法的激增使得我们难以辨别出哪种特定的方法最适合于执行一个丰富的、多样化的任务,例如抓取。为了回答这一问题,我们提出了一个机器人抓取的模拟基准,强调了对于没见过的目标的策略学习和泛化。
Off-policy学习能够在各种各样的目标上对抓取数据加以利用,而且多样性对于使该方法能够在训练期间泛化到没见过的目标中起到至关重要的作用。我们对针对各种Q函数估计方法的基准任务进行了评估,一种是以往提出的,使用深度神经网络模型进行机器人抓取,以及一种基于蒙特卡罗回归估计(Monte Carlo return estimation)和off-policy校正相组合的新方法。我们的研究结果表明,几种简单的方法为诸如双Qlearning这样的通用算法提供了一个令人惊讶的强大竞争对手,而我们对稳定性的分析揭示了算法之间的相对权衡。

机器人抓取是最基本的机器人操作任务之一:在与环境中的目标进行交互之前,机器人通常必须从先抓取它们开始。在以前的机器人操作研究中往往试图通过各种各样的方法解决抓取问题,从分析抓取度量到基于学习的方法。直接从自我监督中学习抓取为这一领域提供了相当有发展前景的研究方向:如果机器人能够通过反复的经验逐渐提高自身的抓取能力,那么它可能会在极少人为干预的情况下达到非常高的熟练程度。
实际上,受计算机视觉技术启发的,基于学习的方法近年来取得了良好的效果。然而,这些方法通常不是导致抓取任务序列方面结果的原因所在,要么选择一个单一的抓取姿势,要么贪婪地反复选择下一个最有希望抓取的姿势。虽然先前的研究已经在一个序列决策上下文中,对使用深度强化学习(RL)作为机器人抓取的框架进行了探索,但这样的研究要么仅限于单一的目标,要么是诸如立方体这样的简单几何形状。
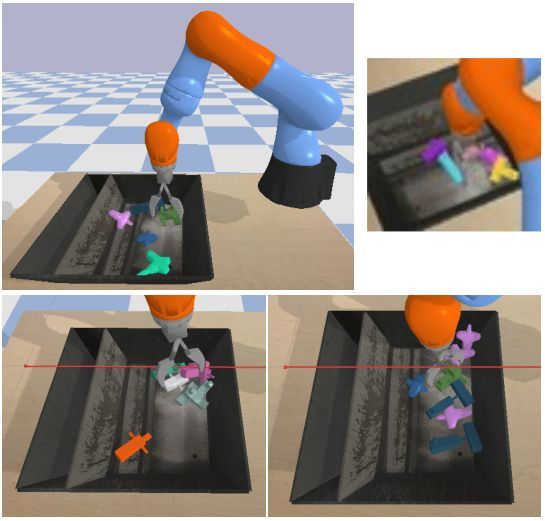
左上角:我们模拟抓取环境的演示。机器人必须在容器中拾取目标,所使用的随机目标如图2所示的。右上角:对机器人的样本观察。左下角:在第一个任务中,机器人选择了各种各样的随机目标,并将其泛化到没见过的测试目标中。右下角:在第二项任务中,机器人必须从杂乱的箱子中挑出一个紫色的十字形物体。
在这项研究中,通过在一个真实的模拟基准中对各种强化学习方法加以比较,我们探讨了强化学习是如何用于自动学习用于不同物体的机器人抓取技巧。
在基于学习的抓取中,最重要的挑战之一是泛化能力:该系统能够学习抓取模式和线索,从而使其能够成功对训练期间不可见的目标实现抓取吗?成功的泛化通常需要对各种各样的目标和场景进行训练,以获得可泛化的感知和控制。先前有关抓取的监督学习研究已经使用了数万乃至数百万个抓取动作,涉及数百个不同的目标。
这种机制对于强化学习来说是一个重大挑战:如果学习主要是on-policy进行的,那么机器人必须反复重访先前所看到的目标以避免遗忘,这使得处理极其多样化的抓取场景变得更加困难。因此,Off-policy强化学习方法可能更适用于诸如抓取这样的任务,其中各种先前看到的目标对于泛化来说具有至关重要的作用。事实上,在以前的研究中所探讨的监督学习方法可以被形式化为Off-policy强化学习的特例,而不考虑抓取任务的序列本质。

左:用于训练的900个物件中的30个。右:100个测试物件中的10个。
我们在本文中的研究目标是了解哪些Off-policy强化学习算法最适合基于视觉的机器人抓取任务。
近年来,为解决Atari游戏和简单模拟机器人的控制等问题,科学家们已经提出了许多无模型、Off-policy深度强化学习方法。然而,这些研究并没有对机器人抓取任务中出现的各种各样的高度变化的情况进行探索,重点通常集中在最终的性能表现上(例如期望奖励),而不是泛化到新的目标和场景中。此外,训练通常涉及逐步收集越来越多的on-policy数据,同时将旧的off-policy数据保留在重放缓冲区中。我们研究这些算法的相对性能是如何在一个强调多样性和泛化能力的off-policy机制中进行变化的。
我们对这些方法的讨论,为以往研究中的各种Q-函数估计技术提供了一个统一的处理方法。我们的研究结果表明,深度强化学习可以成功地从原始像素中学习抓取多种目标,并且可以在我们的模拟器中对以往没有见过的目标进行抓取,且平均成功率为90%。
令人惊讶的是,在这个具有挑战性的领域中,朴素蒙特卡罗评估是一个强有力的基准,尽管在off-policy情况下存在一定的偏差。我们提出的无偏差、校正版本实现了可与其相媲美的性能表现。深度Q-learning在数据有限的机制系统下表现得也很出色。我们还分析了不同方法的稳定性,以及在on-policy 和off-policy情况下,不同off-policy数据数量情况下的性能差异。我们的研究结果揭示了不同方法是如何在现实的模拟机器人任务上进行比较的,并提出了开发新的、更有效的用于机器人操作的深度强化学习算法的途径。
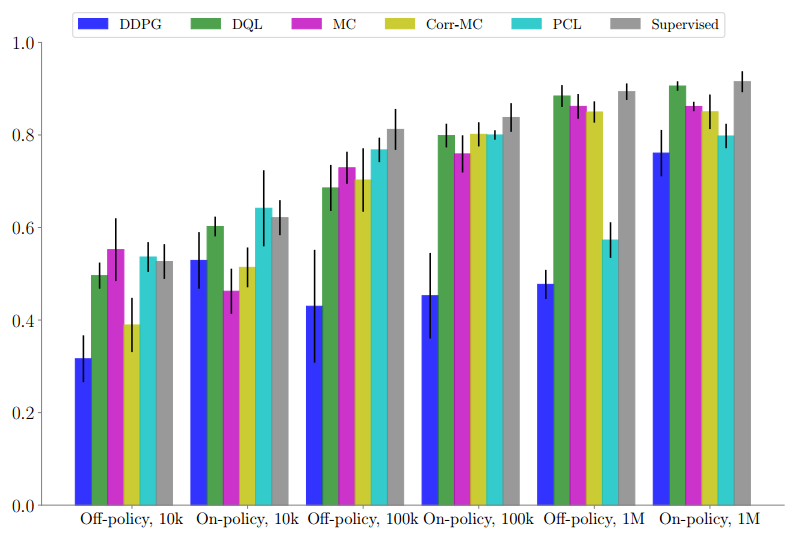
对不同数据集大小的测试目标的定期抓取性能展示。DQL和监督基线性能表现最好。从9个独立运行的随机seeds中计算的标准差。
我们提出了一系列off-policy、无模型深度强化学习算法的经验评估。我们的算法集包括通用的无模型方法,如双Q-learning、DDPG和PCL,以及基于监督学习的使用合成动作的先验方法。
除此之外,我们的方法中还涵盖一个朴素蒙特卡罗方法,它在off-policy情况下存在偏差,但却能够取得合理的性能表现,且常常优于DDPG,以及一个该蒙特卡罗方法的修正版本,也是这项研究的一个新成果。我们的研究实验是在一个涉及两种任务的多样化抓取模拟器上进行的,一个抓取任务是对训练期间全新的、不可见随机目标的泛化能力的评估,以及一个目标抓取任务,它需要在混乱状态下的特定类型的目标进行分离并抓取。
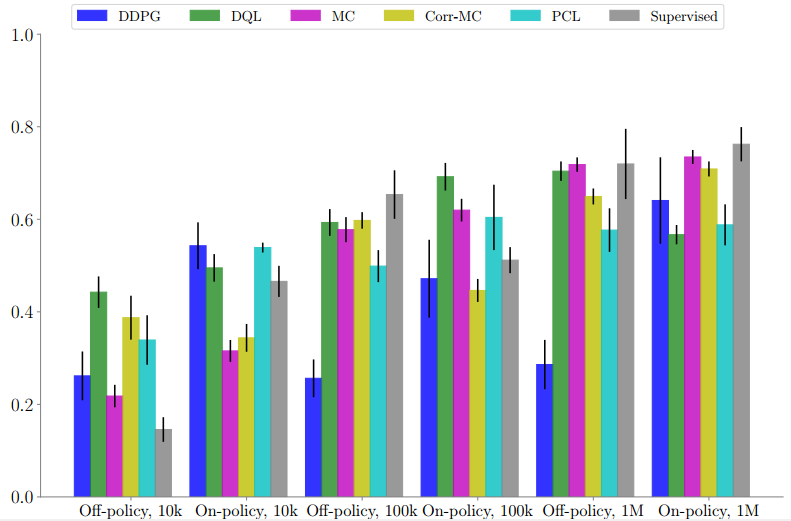
针对不同的数据集大小,将抓取目标锁定在一个有三个目标物件和四个非目标物件的混乱的箱子中。DQL在较少数据和off-policy环境中表现良好,而蒙特卡罗和修正版蒙特卡罗方法在具有最大量数据的环境中表现最好。
我们的评估结果表明,无论是对于on-policy还是off-policy学习来说,DQL的性能表现都要比较少数据机制下的其他算法好得多,并且附加带有对超参数选择具有鲁棒性的理想属性。当数据更丰富时,诸如蒙特卡罗或蒙特卡罗修正版本这样的回归到多步返回的算法,通常会获得稍好的性能表现。
在考虑算法特征时,我们发现使用演员网络(actor network)会大大降低稳定性,导致性能表现较差和严重的超参数敏感性。当数据充足时,使用完整事件值进行监督的方法往往表现得更好,而自助式(bootstrapped)DQL方法在较少数据情况下表现更好。
这些结果表明,在可以使用off-policy数据的机器人环境中,更适合使用单一网络方法以维护稳定性;而在数据充足时,使用(修正)完整事件返回的方法是更好的首选,而bootstrapped方法更适合用于较少数据环境中。这一结果的本质含义是,在未来,对机器人强化学习算法的研究可能会集中在通过调整基于数据可用性的目标值类型以将最佳自助式和多步返回结合起来。我们研究的另一个自然延伸是在实际环境中评估类似的方法。由于我们所评估的算法都能在off-policy环境下成功运行,因此在现实环境中使用它们也可能是一个合理且实用的选择。
原文来源:arXiv
作者:Deirdre Quillen、Eric Jang、Ofir Nachum、Chelsea Finn、Julian Ibarz、Sergey Levine
原文链接:https://arxiv.org/pdf/1802.10264.pdf
生成对抗网络 GAN 就是强化学习(超全资料)

Ian Goodfellow 新智元报道
来源:fermatslibrary.com
编译:闻菲、肖琴
【新智元导读】今天,Ian Goodfellow开展了一场有关生成对抗网络(GAN)的最新AMA问答,从他小时候如何学习编程,如何想出GAN这个idea,到具体的技术和应用,Goodfellow都作出了专业而且诚恳的回答。Goodfellow认为不止是GAN,胶囊网络、强化学习、半监督学习等等方法都很重要,也值得更多人重视。
问:有传言说你是在一家小酒馆里想出了GAN的idea,是这样吗?
Ian Goodfellow :这是真事,不仅仅是传言。我之前在好几次采访中都讲过这个故事了。
参考:专访 Ian Goodfellow:欲在谷歌打造 GAN 团队,用假数据训练真模型
问:在训练GAN方面似乎有两三个阵营(camp),你和在OpenAI、谷歌的人,Mescheder, Sebastian Nowozin和微软研究院的人,以及其他。在这些阵营中你有看到什么相似点吗?
Ian Goodfellow:实际上有更多阵营。FAIR/NYU也是重镇,实际上是FAIR/NYU最先把GAN带进了我们的视野(LAPGAN)。那是第一次GAN生成了逼真的高清图像,也是第一次GAN得到媒体曝光,等等。另外一个重要阵营是伯克利+英伟达,他们专注超高清逼真图像和视频,无监督翻译,等等。我不太清楚你用“阵营”(camps)想表达什么,如果是说用不同的思路和方法在研究GAN,那么确实如此。但“阵营”一般多指相互敌对的团队,在这里并不适用。
问:问个有点偏的问题——有人认为重新思考深度学习模型中“神经元”的工作方式,是应对对抗样本的唯一方法,你怎么看?在以前的演讲中你提到过,这种通用样本的存在是因为这些模型的“线性”(对应之前人们说的“非线性”)。继续采用使用了这些神经元的模型,在方向性上说会不会是错误的?或者说,好好选择激活函数,做好数据增强/防御,能从整体上解决这个问题?
Ian Goodfellow:我不认为这个问题有点偏,因为GAN的判别器需要具有鲁棒性,应对生成器的对抗攻击。同时,我确实认为我们当前使用的神经元,很难在应对对抗样本方面具有鲁棒性。但我并不认为这是唯一有问题的地方。一些最新的工作,比如(https://arxiv.org/abs/1801.02774)表明,要让图像分类安全可靠,我们真的需要从根本上重新考虑我们使用的策略,而不仅仅是训练的模型。
胶囊网络(Capsule networks)能比普通模型更好的应对对抗攻击(https://openreview.net/forum?id=HJWLfGWRb)。目前还不清楚这是不是最好的防御方法——我还没看到有使用最先进的攻击方法来一对一测试模型可靠性的工作。
问:定量评估GAN的指标是什么?
Ian Goodfellow:这取决于你想用GAN来做什么。如果你想将其用于半监督式学习,请使用测试集精度作为评估指标,如果你想使用它来生成高质量的图像(例如超分辨率),那么可能需要使用人类评分员来评估。如果你只是想得到一个通用的自动化的质量得分,那么我认为Frechet Inception Distance(https://arxiv.org/abs/1706.08500)可能是最好的,尤其是对于class-specific(https://arxiv.org/pdf/1802.05957.pdf)的模型来说。这些指标本身现在仍是一个正在进行的重要的研究领域。
问:有没有办法将潜变量(latent variables)映射到fake image的部分?换句话说,是否可以这样说:这2个变量改变图像的背景颜色,这些x变量修改了形状,等等?
Ian Goodfellow:这不是总是可行的,但你可以训练模型这样表现。例如InfoGAN:https://arxiv.org/abs/1606.03657
问:1)如何在GAN和其他生成模型,比如VAE和FVBN(NADE, MADE, PixelCNN)之间选择?选择的时候有什么比较标准吗?2)像Librarian/Fermat's Library这样的在线文库对于ML/DL论文来说重要吗?现在ML/DL论文一般都是直接发表在arXiv。
Ian Goodfellow:我在Fermat’s Library这里做AMA,就是为了推广这些工具,我认为它们很重要,也值得更多人重视。ArXiv现在基本成了绕过同行评议的捷径,让深度学习论文的信噪比骤降。现在仍然有很多优秀的深度学习研究在进行,但同样也存在大量的低质量工作。如今就连最好的那些工作也是好坏掺半——有很好的想法,但却用宣传推广的套路在写,跟其他工作的比较也不准确,等等。这都是因为这些论文没有经过同行评议。
至于方法选择,如果你想生成连续变量的真实样本,做无监督翻译(例如GycleGAN),或者做半监督学习,那么你很可能用得着GAN。如果你想生成的是离散标记(token),你或许还用不着GAN,但我们也在不断改进。如果你想要的是最大似然,就不要用GAN了。
问:GAN与强化学习(RL)原则之间有什么相似之处(如果有的话)?我对这两者都不是专家(只有非常基本的了解),我觉得GAN的“generator - discriminator”的想法和RL的“agent - environment interaction”有着紧密的联系。是这样吗?
Ian Goodfellow:我也不是RL的专家,但我认为GAN是使用RL来解决生成建模问题的一种方式。GAN的不同之处在于,奖励函数对行为是完全已知和可微分的,奖励是非固定的,以及奖励是agent的策略的一个函数。但我认为GAN基本上可以说就是RL。
问:有测试生成模型可迁移性的论文或研究吗?例如我有一个生成狗或者猫的模型,之后想用早一些的层生成狼和老虎。
Ian Goodfellow:我不知道,但肯定有。对于生成器来说,可能偏后期的层(靠近输出的)更容易共享。
问:GAN能用于话题建模(Topic Modeling)吗?除了生成建模(目前主要用于图像),还有其他领域使用GAN框架吗?
Ian Goodfellow:我猜应该有,但我不知道具体的。文档是离散token,比如文字、单词,而GAN需要计算生成器的输出的梯度,因此在有连续输出的地方才能很好的工作。或许你可以用对抗自编码器,或者AVB,在这里生成器实际上是编码器,能够输出连续的代码。这对于文档建模有很大帮助,因为能对topics给出一个分布式表示。
问:GAN在基因组学里有什么应用?
Ian Goodfellow:我不太了解基因组学,但我认为GAN这类的模型可以用于半监督学习。我想在基因组学中,未标记的数据应该比有标记的更多,利用大量的未标记数据从少量标记数据中学习的话,半监督学习会很有帮助。这方面Tim Salimans提出了一些方法,在MNIST、SVHN等基准上特别好用:https://arxiv.org/abs/1606.03498
但需要注意,我们发现其他半监督方法实际上并不怎么好用(https://openreview.net/forum?id=ByCZsFyPf ),但半监督GAN并没有接受这些测试。
问:您最近在Twitter上列举了你觉得最好的10论文GAN论文。你可以写一篇博客文章,介绍从GAN的初学者到GAN专家都适合的所有论文和其他资源吗?
Ian Goodfellow:我可能没有时间做这件事情,而且就算写一篇这样的文章,它会很快就过时。
我在2016年12月写了关于GAN的长文教程:NIPS 2016 Tutorial: Generative Adversarial Networks (https://arxiv.org/abs/1701.00160)
里面的许多想法在今天仍然有价值,尽管这个教程没有包含2017年以来的最新模型,例如Progressive GANs,spectrally normalized GANs, GANs with projection discriminator等等。
问:你是怎样提高你的编程技巧,以便快速尝试各种疯狂的想法,例如GANs?有没有推荐的编程技能的书?以及请推荐一些TensorFlow学习或深度学习框架的书籍。谢谢。
Ian Goodfellow:
回答推荐书籍:我自己学习现代深度学习编程的路径是相当间接的(在我开始使用Python之前,我已经学会了各种C,assembly,web等编程语言),因此我不知道对于今天的学习者来说最好的方法是什么。
在编程能力方面,对我来说一个非常重要的转折点是在斯坦福大学Jerry Cain开的CS107课程,我记得是在2006年春季学习了这门课程。在那之前,我只是一名编程爱好者,系统工作的时候我感到兴奋,但很多时候,系统宕机时我只能感到困惑,不知道是什么地方错了。学完这门课后,我就再没有因为软件开发方面的任何事情困惑过。你可以在YouTube或iTunes U之类的网站上找到这门课的讲座。
回答“你怎样提高编程技能,以便快速尝试各种疯狂的想法,比如GANs”:
我编程的时间很长!我在11岁就学会了编程,中学时我们的数学课有图形计算器,有人在上面用 TI-BASIC编了一个游戏。为了了解这个游戏的工作原理,我从图书馆复制了一本“MacFroggy Teaches Basic ”来学习BASIC语言。
我入坑deep learning的部分原因是我一直在出于爱好做游戏编程。我一直在使用OpenGL Shading Language(GLslang)来编写通用的GPU程序。当CUDA推出时,利用GPU进行CUDA编程实际上比试图将数学问题转换为专为图形设计的语言要容易得多。在Geoff Hinton的关于deep belief nets的论文发表后不久,我的朋友Ethan Dreyfuss就给我讲了有关深度学习的内容,然后我和Ethan一起搭建了斯坦福大学的第一台用于深度学习的CUDA机器。我最初编写的深度学习程序是在CUDA中实现RBM。与我编写GAN时所做的努力相比,这要困难得多。在写GAN时,我已经有很多很好的工具,例如Theano,LISA lab等等。
编写GAN代码很容易,部分原因是我有一个很好的代码库,可以从早期的项目开始。我的整个博士学位期间都在搞深度学习,有很多类似的代码可以随时待命。我的第一个GAN实现主要是从MNIST分类器(https://arxiv.org/pdf/1302.4389.pdf)的代码中复制粘贴来的。
Invited Talks
Adversarial Examples and Adversarial Training
"Defending Against Adversarial Examples". NIPS 2017 Workshop on Machine Learning and Security. [slides(pdf)] [slides(key)]
"Thermometer Encoding: One hot way to resist adversarial examples," 2017-11-15, Stanford University [slides(pdf)] [slides(key)]
"Adversarial Examples and Adversarial Training," 2017-05-30, CS231n, Stanford University [slides(pdf)] [slides(key)]
"Adversarial Examples and Adversarial Training," 2017-01-17, Security Seminar, Stanford University [slides(pdf)] [slides(key)]
"Adversarial Examples and Adversarial Training," 2016-12-9, NIPS Workshop on Reliable ML in the Wild [slides(pdf)] [slides(key)] [video(wmv)]
"Adversarial Examples and Adversarial Training," presentation at Uber, October 2016. [slides(pdf)]
"Physical Adversarial Examples," presentation and live demo at GeekPwn 2016 with Alex Kurakan. [slides(pdf)]
"Adversarial Examples and Adversarial Training," guest lecture for CS 294-131 at UC Berkeley. [slides(pdf)] [slides(key)] [video(youtube)]
"Exploring vision-based security challenges for AI-driven scene understanding," joint presentation with Nicolas Papernot at AutoSens, September 2016, in Brussels. Access to the slides and video may be purchased at the conference website. They will be freely available after six months.
"Adversarial Examples and Adversarial Training" at HORSE 2016. [slides(pdf)] [youtube]
"Adversarial Examples and Adversarial Training" at San Francisco AI Meetup, 2016. [slides(pdf)]
"Adversarial Examples and Adversarial Training" at Quora, Mountain View, 2016. [slides(pdf)]
"Adversarial Examples" at the Montreal Deep Learning Summer School, 2015. [slides(pdf)] [video]
"Do statistical models understand the world?" Big Tech Day, Munich, 2015. [youtube]
"Adversarial Examples" Re-Work Deep Learning Summit, 2015. [youtube]
Generative Adversarial Networks
"Overcoming Limited Data with GANs". NIPS 2017 Workshop on Limited Labeled Data. [slides(pdf)] [slides(key)]
"Bridging theory and practice of GANs". NIPS 2017 Workshop on Bridging Theory and Practice of Deep Learning. [slides(pdf)] [slides(key)]
"GANs for Creativity and Design". NIPS 2017 Workshop on Creativity and Design. [slides(pdf)] [slides(key)]
"Giving artificial intelligence imagination using game theory". 35 under 35 talk at EmTech 2017. [slides(pdf)][slides(key)]
"Generative Adversarial Networks". Introduction to ICCV Tutorial on Generative Adversarial Networks, 2017. [slides(pdf)] [slides(key)]
"Generative Adversarial Networks". NVIDIA Distinguished Lecture Series, USC, September 2017. [slides(pdf)] [slides(key)]
"Generative Adversarial Networks". Adobe Research Seminar, San Jose 2017. [slides(pdf)] [slides(keynote)]
"Generative Adversarial Networks". GPU Technology Conference, San Jose 2017. [slides(pdf)] [slides(keynote)]
"Generative Adversarial Networks". Re-Work Deep Learning Summit, San Francisco 2017. [slides(pdf)] [slides(keynote)]
Panel discussion at the NIPS 2016 Workshop on Adversarial Training: Facebook video
"Introduction to Generative Adversarial Networks," NIPS 2016 Workshop on Adversarial Training. [slides(keynote)] [slides(pdf)] [video (Facebook)]
"Generative Adversarial Networks," NIPS 2016 tutorial. [slides(keynote)] [slides(pdf)] [video] [tech report(arxiv)]
"Generative Adversarial Networks," a guest lecture for John Canny's COMPSCI 294 at UC Berkeley. Oct 2016. [slides(keynote)] [slides(pdf)] [youtube]
"Generative Adversarial Networks" at AI With the Best (online conference), September 2016. [slides(pdf)]
"Generative Adversarial Networks" keynote at MLSLP, September 2016, San Francisco. [slides]
"Generative Adversarial Networks" at Berkeley AI Lab, August 2016. [slides(pdf)]
"Generative Adversarial Networks" at NVIDIA GTC, April 2016. [slides(pdf)][video]
"Generative Adversarial Networks" at ICML Deep Learning Workshop, Lille, 2015. [slides(pdf)] [video]
"Generative Adversarial Networks" at NIPS Workshop on Perturbation, Optimization, and Statistics, Montreal, 2014. [slides(pdf)]
Other Subjects
"Adversarial Robustness for Aligned AI". NIPS 2017 Workshop on Aligned AI. [slides(pdf)] [slides(key)]
"Defense Against the Dark Arts: Machine Learning Security and Privacy," BayLearn, 2017-10-19. [slides(pdf)][video(youtube)]
"Adversarial Machine Learning for Security and Privacy," Army Research Organization workshop, Stanford, 2017-09-14. [slides(pdf)]
"Generative Models I," 2017-06-27, MILA Deep Learning Summer School. [slides(pdf)] [slides(key)]
"Adversarial Approaches to Bayesian Learning and Bayesian Approaches to Adversarial Robustness," 2016-12-10, NIPS Workshop on Bayesian Deep Learning [slides(pdf)] [slides(key)]
"Design Philosophy of Optimization for Deep Learning" at Stanford CS department, March 2016. [slides(pdf)]
"Tutorial on Optimization for Deep Networks" Re-Work Deep Learning Summit, 2016. [slides(keynote)] [slides(pdf)]
"Tutorial on Neural Network Optimization Problems" at the Montreal Deep Learning Summer School, 2015. [slides(pdf)][video]
"Practical Methodology for Deploying Machine Learning" Learn AI With the Best, 2015. [slides(pdf)] [youtube]
Contributed Talks
"Qualitatively characterizing neural network optimization problems" at ICLR 2015. [slides(pdf)]
"Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks" with Yaroslav Bulatov and Julian Ibarz at ICLR 2014. [youtube]
"Maxout Networks" at ICML 2013. [video]
"Joint Training Deep Boltzmann Machines for Classification" at ICLR 2013 (workshop track). [video]
Miscellaneous
I've made several presentations for the Deep Learning textbook, and presented some of them at a study group for the book.
PhD thesis defense. [youtube] [slides]
Ian Goodfellow GAN资料地址:http://www.iangoodfellow.com/slides
Ian Goodfellow 关于GAN的最新AMA地址:https://fermatslibrary.com/arxiv_comments?url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdf

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能金融”、“智能零售”、“智能驾驶”、“智能城市”;新模式:“财富空间”、“工业互联网”、“数据科学家”、“赛博物理系统CPS”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:[email protected]