Postgresq数据库核心架构及执行计划
一、概述
工作中使用springcloud微服务框架,使用JPA作为数据库持久层,JPA支持开发者使用函数命名的方式进行sql操作,但仅限一些简单的增删改查操作,对于较为复杂的或涉及到联合查询的一些sql操作,仍旧需要写原生sql或hql。而对于一些复杂的查询语句,有时需要进行sql语句优化,就需要用到sql执行计划对其进行分析,postgresql的执行计划语法和mysql有所不同,本文特对此做下简要概述,以便后续开发中sql调优时用,同时也介绍一下postgresql的整体架构。
二、Postgresql核心架构
postgresql可运行在Linux、Windows、AIX、FreeBSD、Solaris及其他类UNIX操作系统之上。支持不同语言,如C/C++、Python、PHP、Ruby、JAVA等通过驱动进行连接使用。
postgresql的主进程叫Postmaster,当有客户端请求连接时,Postmaster主进程会先进行身份认证,认证通过后会创建出一个子进程为该连接服务,连接数限制可通过修改配置文件(data目录下的postgresql.conf )中的max_connections参数进行设置。除了客户端连接所创建的进程,postgresql还有一些其他的辅助进程,如:BgWriter、WalWriter等,这些进程都是Postmaster主进程启动完后所创建的,通过这些进行对数据库的日常工作进行管理。
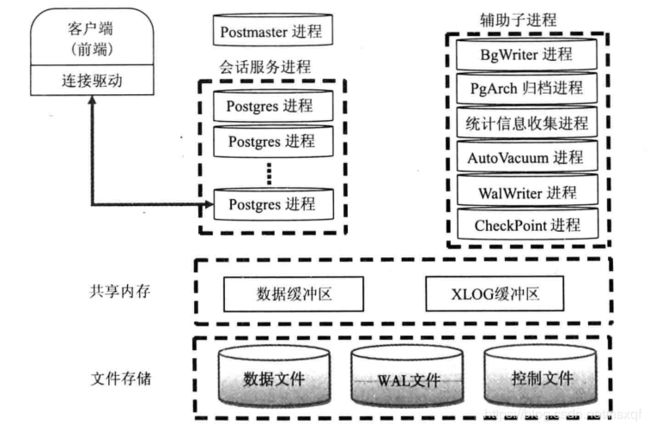
BgWriter(后台写进程):主要作用是定时把共享内存中的一些操作数据更新到磁盘。频率不能太高也不能太低。若频率太低,查询请求进来时还有数据未更新到磁盘,则需要先将数据刷进磁盘后再从磁盘读取,较耗时;若频率太高,会增加磁盘IO次数。可由bgwriter_delay参数对频率进行控制,默认200ms写一次。
WalWriter(预写式日志进程):主要作用是保证数据的一致性和事务的完整性,防止在系统崩溃时最近的事务无法恢复。fsync参数直接控制日志是否先写入磁盘。默认值是ON(先写入)。开启该值时表明,更新数据写入磁盘时系统必须等待WAL的写入完成。可以配置该参数为OFF,更新数据写入磁盘完全不用等待WAL的写入完成,没有了等待的时间,显然接下来的工作能够更早的去做,节省了时间,提高了性能。其直接隐患是无法保证在系统崩溃时最近的事务能够得到恢复,也就无法保证相关数据的真实与正确性。 Wal日志保存在pg_xlog下,每个xlog文件默认16MB。
PgArch(归档进程):由于Wal日志会被循环使用,因此较早的Wal日志会被覆盖,PgArch的作用就是在覆盖前把Wal日志备份出来。保证恢复数据时数据的完整性。
共享内存:共享内存主要包括一些数据缓冲区、及一些全局环境变量,如进程信息、锁信息等。如下图:

三、Postgresql中的执行计划
语法:
| EXPLAIN [ ( option [, ...] ) ] statement 可选项: ANALYZE [ boolean ] 执行语句并显示真正的运行时间和其它统计信息,默认值False。
VERBOSE [ boolean ] 显示额外的信息,包括计划树中每个节点的字段列表,schema识别表和函数名称,触发器的名字等。默认值FALSE。
COSTS [ boolean ] 显示预估的启动及消耗时间成本、行数、行宽。默认为True。
TIMING [ boolean ] 显示实际的启动及消耗时间成本、行数。默认为True。
FORMAT { TEXT | XML | JSON | YAML } 声明输出格式,可以为TEXT, XML, JSON 或 YAML。非文本的输出包含文本输出格式相同的信息,但是更容易被程序解析。默认为TEXT。
BUFFERS [ boolean ] 使用信息。特别包括共享块命中、读、脏和写的次数,本地块命中、读、脏和写,临时块读和写的次数。 命中意味着避免了物理读,因为块在需要时已经在缓存中发现了。共享块包含普通表和索引的数据。 本地块包含临时表和索引的数据;而临时块包含用于排序、哈希、物化计划节点和类似情况的短期工作数据。 脏块的数量表示该查询之前改变且未提交的块的数量;写块的数量表示在查询时被后台进程从缓存释放的脏块数量。 上层节点显示的块的数量是所有它的子节点使用块的数量合计。在文本格式中只打印非零值。 该参数可能只在ANALYZE也启用的时候使用。默认为FALSE。
|
例子说明:
表信息:
city

country

1.全表扫描
explain (analyze, timing true) select * from countrySeq Scan on country (cost=0.00..28.10 rows=10 width=11) (actual time=0.038..0.040 rows=10 loops=1)
Planning time: 0.029 ms
Execution time: 0.053 ms结果解释:
Seq Scan on country:说明对country表进行全表扫描
(cost=0.00..28.10 rows=10 width=11):从左到右依次为 评估消耗时间、评估返回行数、评估行宽
(actual time=0.038..0.040 rows=10 loops=1):从左到右依次为 实际消耗时间、实际返回行数、实际循环数
2.加上where条件
explain (analyze) select * from country where country_id < 5Seq Scan on country (cost=0.00..28.12 rows=4 width=11) (actual time=0.042..0.044 rows=4 loops=1)
Filter: (country_id < 5)
Rows Removed by Filter: 6
Planning time: 0.052 ms
Execution time: 0.060 ms Filter: (country_id < 5)
Rows Removed by Filter: 6
where条件进行了过滤,返回结果为4条,但由于country_id字段未加索引,还是做了全表扫描(Seq Scan on country)
3.还是同样的sql,给country_id字段加上索引后,返回结果有所变化
explain (analyze) select * from country where country_id < 5Bitmap Heap Scan on country (cost=1.67..6.96 rows=4 width=11) (actual time=0.012..0.012 rows=4 loops=1)
Recheck Cond: (country_id < 5)
Heap Blocks: exact=1
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.67 rows=4 width=0) (actual time=0.007..0.007 rows=4 loops=1)
Index Cond: (country_id < 5)
Planning time: 0.059 ms
Execution time: 0.032 msBitmap Heap Scan(位图扫描)是索引扫描的一种,系统会根据实际情况选择合适的索引扫描方式。
Index Cond: (country_id < 5):查询到索引
Bitmap Heap Scan on country:外层通过索引查询到数据
4.再增加一个查询条件(非索引):
explain (analyze) select * from country where country_id < 5 and country_name = 'country6'Bitmap Heap Scan on country (cost=1.67..6.97 rows=1 width=11) (actual time=0.019..0.019 rows=0 loops=1)
Recheck Cond: (country_id < 5)
Filter: ((country_name)::text = 'country6'::text)
Rows Removed by Filter: 4
Heap Blocks: exact=1
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.67 rows=4 width=0) (actual time=0.010..0.010 rows=4 loops=1)
Index Cond: (country_id < 5)
Planning time: 0.088 ms
Execution time: 0.043 ms在3的基础上,会增加一个对country_name字段的过滤操作:Filter: ((country_name)::text = 'country6'::text)
5. 如果在不同的字段上有独立的索引,规划器可能选择使用AND或者OR组合索引。下面的sql,两个条件的字段都用了country_id,即都加了索引,因此不会做Filter操作,而是进行了Or组合索引( BitmapOr)
explain (analyze) select * from country where country_id < 5 or country_id > 5Bitmap Heap Scan on country (cost=4.85..15.95 rows=8 width=11) (actual time=0.015..0.015 rows=9 loops=1)
Recheck Cond: ((country_id < 5) OR (country_id > 5))
Heap Blocks: exact=1
-> BitmapOr (cost=4.85..4.85 rows=10 width=0) (actual time=0.012..0.012 rows=0 loops=1)
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.67 rows=4 width=0) (actual time=0.007..0.007 rows=4 loops=1)
Index Cond: (country_id < 5)
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..3.18 rows=6 width=0) (actual time=0.004..0.004 rows=5 loops=1)
Index Cond: (country_id > 5)
Planning time: 0.063 ms
Execution time: 0.038 ms6.看下联合查询的例子
explain (analyze) select * from country co, city ci where co.country_id < 5 and co.country_id = ci.country_idHash Join (cost=7.01..235.87 rows=3636 width=23) (actual time=0.034..4.371 rows=3999 loops=1)
Hash Cond: (ci.country_id = co.country_id)
-> Seq Scan on city ci (cost=0.00..155.00 rows=10000 width=12) (actual time=0.013..2.830 rows=10000 loops=1)
-> Hash (cost=6.96..6.96 rows=4 width=11) (actual time=0.009..0.009 rows=4 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Bitmap Heap Scan on country co (cost=1.67..6.96 rows=4 width=11) (actual time=0.005..0.006 rows=4 loops=1)
Recheck Cond: (country_id < 5)
Heap Blocks: exact=1
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.67 rows=4 width=0) (actual time=0.004..0.004 rows=4 loops=1)
Index Cond: (country_id < 5)
Planning time: 2.505 ms
Execution time: 4.565 ms由于我们给country表的country_id字段做了索引,规划器会先对country进行索引扫描(-> Bitmap Index Scan on country_country_id_idx),并将扫描结果作为外层city表的Hash节点输入(-> Hash (cost=6.96..6.96 rows=4 width=11) (actual time=0.009..0.009 rows=4 loops=1)),然后Hash Join节点读取外层子节点的数据,再循环检索哈希表的数据。
7.如果我们给city表的country_id加上索引,同样的sql语句结果将发生变化
explain (analyze) select * from country co, city ci where co.country_id < 5 and co.country_id = ci.country_idNested Loop (cost=1.95..148.59 rows=3636 width=23) (actual time=0.026..1.054 rows=3999 loops=1)
-> Bitmap Heap Scan on country co (cost=1.67..6.96 rows=4 width=11) (actual time=0.005..0.005 rows=4 loops=1)
Recheck Cond: (country_id < 5)
Heap Blocks: exact=1
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.67 rows=4 width=0) (actual time=0.002..0.002 rows=4 loops=1)
Index Cond: (country_id < 5)
-> Index Scan using city_country_id_idx on city ci (cost=0.29..26.32 rows=909 width=12) (actual time=0.008..0.149 rows=1000 loops=4)
Index Cond: (country_id = co.country_id)
Planning time: 0.193 ms
Execution time: 1.224 ms规划器使用了Nested Loop(嵌套循环连接)扫描。从查询计划中可以看到,先以索引扫描的方式扫描了city表(Index Scan using city_country_id_idx on city ci)作为内表,又以位图(索引)扫描的方式扫描了country表,作为外表(驱动表),然后进行嵌套循环连接查询。内表循环次数为4次,每次平均1000行,外表4行,总返回行数3999行。
8.该变一下条件,co.country_id < 5改为ci.country_id < 5
explain (analyze) select * from country co, city ci where ci.country_id < 5 and co.country_id = ci.country_idMerge Join (cost=28.55..185.43 rows=3635 width=23) (actual time=0.062..1.304 rows=3999 loops=1)
Merge Cond: (co.country_id = ci.country_id)
-> Sort (cost=28.27..28.29 rows=10 width=11) (actual time=0.046..0.047 rows=5 loops=1)
Sort Key: co.country_id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on country co (cost=0.00..28.10 rows=10 width=11) (actual time=0.039..0.039 rows=10 loops=1)
-> Index Scan using city_country_id_idx on city ci (cost=0.29..110.77 rows=3999 width=12) (actual time=0.013..0.643 rows=3999 loops=1)
Index Cond: (country_id < 5)
Planning time: 0.218 ms
Execution time: 1.487 ms扫描方式变为了Merge Join(合并连接)
Merge Join需要已经排序的输入数据。我们可以看到内表(city)做了索引扫描,一次性查询出3999条数据,由于外表(country)数据量比较少,做了全表扫描,并进行排序,排序后直接进行Merge Join,得到查询结果。
9.具体选择使用什么样的方式要看数据的量,以及联结列上是否存在索引,若把上面的sql再做下改动,ci.country_id < 5改为ci.country_id = 1,查询策略就会发生改变。此时规划器认为Nested Loop扫描方式更优,先对内表(city)进行一次索引扫描,再对外表(country)进行一次位图(索引)扫描,最后进行Nested Loop扫描。
explain (analyze) select * from country co, city ci where ci.country_id = 1 and co.country_id = ci.country_idNested Loop (cost=1.93..41.91 rows=999 width=23) (actual time=0.032..0.298 rows=999 loops=1)
-> Bitmap Heap Scan on country co (cost=1.64..3.16 rows=1 width=11) (actual time=0.014..0.014 rows=1 loops=1)
Recheck Cond: (country_id = 1)
Heap Blocks: exact=1
-> Bitmap Index Scan on country_country_id_idx (cost=0.00..1.64 rows=1 width=0) (actual time=0.010..0.010 rows=1 loops=1)
Index Cond: (country_id = 1)
-> Index Scan using city_country_id_idx on city ci (cost=0.29..28.77 rows=999 width=12) (actual time=0.016..0.151 rows=999 loops=1)
Index Cond: (country_id = 1)
Planning time: 0.106 ms
Execution time: 0.360 ms
Nested Loop,Hash Join,Merge Join
上面例子中几处都涉及到了联合查询,下面大致介绍以下Nested Loop,Hash Join,Merge Join这三种扫描方式
Nested Loop,嵌套循环连接,是两个表做连接时最直接的一种连接方式,可以理解成两个for循环。一般用于关联字段已建立索引的情况下,联合查询时,会遍历外表(驱动表),然后根据关联字段和内表组做关联查询。由于需要遍历外表的每一行,因此外表的数据量一定要小,返回结果集的响应时间才会快。
Hash Join,这种扫描方式一般用于两张表的关联字段均无索引的情况,优化器会选择两张表中的数据库较小的表,在内存中建立对应的散列表,然后扫描外表(数据量较大的表),找出内存中散列表匹配的行。由于需要将表放入内存中,因此使用这种方式时,内表不能太大,若内表太大而不能完全放入内存,会被分割成若干份,临时写入磁盘,增加I/O开销。
Merge Join,合并连接。这种方式要求合并字段已建立索引或已被排序过,这样合并时就不需要排序了,其性能会由于Hash Join。
一般情况下,除非强制指定使用哪种扫描策略,否则系统会根据实际情况自动选择较优的扫描方式进行数据查询。
四、总结
本文介绍了pgsql的基本架构及执行计划,并举了一些常见的查询例子,最后介绍了三种联合查询的扫描机制。
不管是哪个平台,业务量起来后或多或少都会出现一些性能瓶颈,对于服务本身,一般会做横向扩展,对于数据库,查询优化遵循以下优先级原则:
1.优化SQL和索引:有效利用慢查询、Explain来做优化。
2.增加缓存:利用Redis或Mem等来缓存查询结果。
3.数据库读写分离。
4.垂直拆分,将表根据业务进行拆分,也可认为是分库。
5.水平拆分,针对业务流进行分表。