PASCAL-VOC2012数据集介绍
序言
数据集摘要:包含可用于Classification、Detection、Segmentation三大CV任务的高质量标注数据。
PASCAL-VOC官方主页:http://host.robots.ox.ac.uk/pascal/VOC/
PASCAL-VOC2012官方介绍:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
数据集的官方介绍文章:The PASCAL Visual Object Classes Challenge: A Retrospective[2015-IJCV]
PASCAL-VOC2012数据集下载链接:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar [1.9G]
数据集结构
下载PASCAL-VOC2012解压后得到VOC2012文件夹,进入VOC2012文件夹后,得到:

JPEGImages
JPEGImages文件夹中包含PASCAL-VOC2012数据集的所有图片,共计17125张。图片的命名格式为year_%6d.jpg,其中year表示该图片被加入到数据集的年份,%6d表示长度为6位的image_index。这些图片的尺寸大小不一,但是横向图的尺寸大约在375x500左右,纵向图的尺寸大约在500x375左右,基本不会偏差超过100。
ImageSets

1. Action
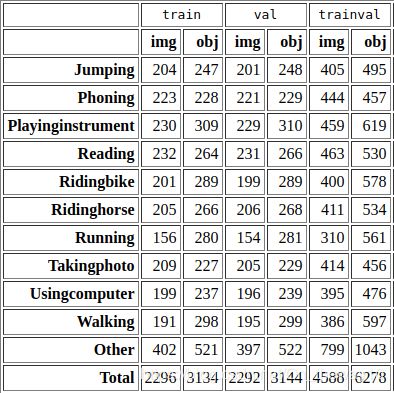
ImageSet包含4个文件夹,其中Action文件夹中包含10类常见的人体动作{jumping, phoning, playinginstrument, reading, ridingbike, ridinghorse, running, takingphoto, usingcomputer. walking}.一共包含33个关于样本划分的文本文件,其中10组组内划分文件[action_train.txt, action_trainval.txt, action_val.txt],外加一组[train.txt, trainval.txt, val.txt],它是整体样本的划分文件。


以jumping_train.txt文件为例,它包含三列,依次为图片的名称、图片中object的index、label{1:正类样本, -1:负类样本}。
2. Layout
包含一组文本文件:train.txt, trainval.txt, val.txt,它用于预测人体的头、手、脚这三部分的bbox,并对bbox内的object分类。

各文本文件都有2列,依次表示:图片名称、图片包含的人数。
3. Main
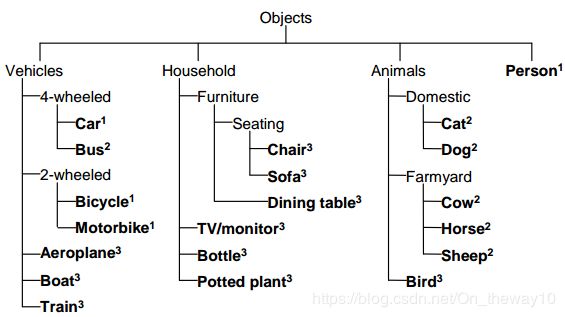
包含63个文本文件,其中20个类的划分文件[class_train.txt, class_trainval.txt, class_val.txt],外加以一组全局样本的[train.txt, trainval.txt, val.txt]划分文件。

###_train.txt、_trainval.txt、_val.txt文件包含2列,依次表示:文件名、label[1:表示正类样本,-1:表示负类样本]。
4. Segmentation
只包含一组[train.txt, trainval.txt, val.txt]文件,各文件只有1列,为图片名称。
Annotations
文件夹中包含数据集全部图片[17125]的标注信息,标注文件以year_index.xml格式存储。下面以2007_000039.xml为例分析:


SegmentationClass
该文件夹下共有2913张year_index.png格式的图片,用于Semantic segmentation[语义分割]。这里的图片共有20+1(背景色)种颜色,例如:所有的狗都被标注为浅紫色,猫为咖啡色,注意这里是.png格式的图片[如果为其它格式,在存储的时候由于压缩、编码等原因会产生浮点型值]。

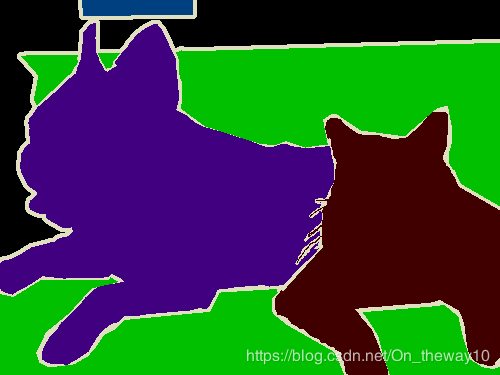


SegmentationObject
该文件夹下也包含2913张图片,存储格式与SegmentationClass中图片的存储格式一致,用于Instance segmentation[实例分割]。在Class里面,一张图片里如果有多架飞机,那么会全部标注为红色。而在Object里面,同一张图片里面的飞机会被不同颜色标注出来。



