GAN论文研读(二)-----DCGAN
GAN论文研读(二)—–DCGAN
1. 卷积与转置卷积
cGAN初步解决了GAN不能生成具有特定属性的图片这一问题,但是,GAN难训练,容易出现大量无效图片的弱点仍未得到改善。为此,Alec Radford等人[1]将卷积神经网络框架引入GAN中,替代原先的多层感知机模型,大大提升了GAN生成图片的稳定性。该论文虽没在理论上进行大量推导,但在GAN的工程实现上做出了不小的贡献。
本文首先介绍Toeplize矩阵与二维卷积的关系,在此基础上引出转置卷积这一升采样方法,最后结合论文提出的网络结构介绍DCGAN。
1.1 二维卷积与Toeplitz矩阵
二维信号的卷积可作为图像平滑去噪、提取特征(如边缘特征)的手段。其基本计算式如下:
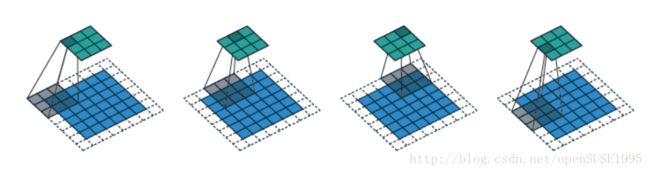
即将卷积核 B B 的反演信号以1为步长,在原图像 A A 上进行滑动平均求解原图像的滤波器响应。CNN中的卷积对传统图像处理中的卷积进行了拓展,丰富了卷积操作的内涵。图像处理中的卷积原本以1为步长,且根据边缘的处理方式,分为full、same和valid三种类型 [2]。CNN中将步长(stride)为1这一限定舍去,步长可以不为1,同时,将三种不同的卷积类型用延拓的大小padding进行统一。一个图像大小为6*6,卷积核大小3*3,stride为2且padding为1的卷积实例如下图所示:
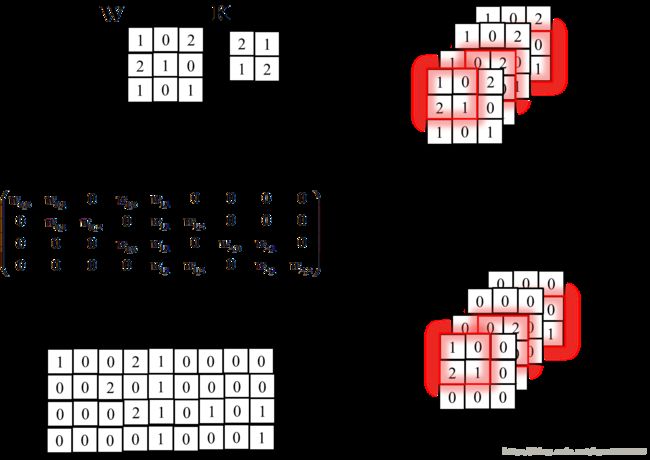
原始卷积定义式并不适合反向求导的公式推导,为此,引入Toeplitz矩阵将卷积运算写成矩阵相乘的形式。Toeplitz矩阵是一种主对角线上的元素相等,平行于主对角线的线上的元素也相等的矩阵他可以直观地将卷积转换为矩阵乘法。为了构造Toeplitz矩阵,首先需要获得经过padding后的图像I以及卷积步长stride,在此基础上,假设可能被卷积核覆盖的区域有 K K 个,则生成 K K 个 I I 的拷贝,将每个拷贝和 K K 对应起来,即每种拷贝对应一种卷积核覆盖图像的方式,对每个拷贝中的像素值,除非该像素被卷积核覆盖,否则将其设为0,最后,将所有拷贝展成行两量并在竖向拼接成一个矩阵,再将卷积核展成列向量,二者相乘并将结果重排大小成卷积后的图像即可。一个Toeplitz的构造实例如下图所示。
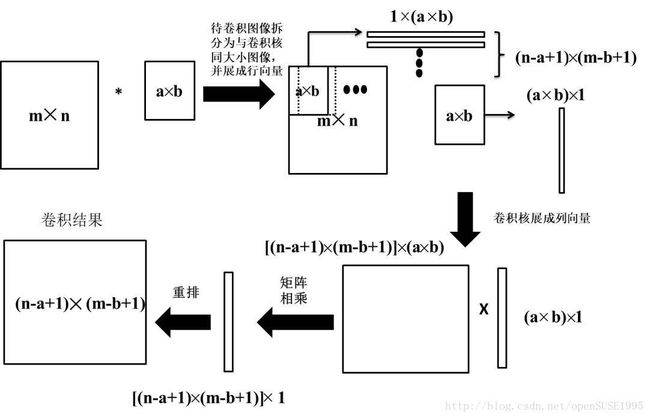
值得一提的是,如果你对MATLAB较为熟悉,就会知道一种基于im2col函数实现的更为简洁的方法。Toeplitz方法中出现了大量无效的0,这些0对于卷积运算并没有帮助,所以自然而然地,可以想到去除那些无用的0,因此,在生成拷贝时就可以将被卷积核覆盖的那部分图像取出而略过原始方案中设0的那些步骤,下图给出了一个案例可供参考。
Toeplitz矩阵将卷积计算转化为单纯的矩阵乘法,从而使卷积过程显得更加直观,同时,它还为转置卷积提供了可行的方案。根据前文所述,容易推导出卷积前后图像的大小关系如下:
其中卷积前后图像的大小分别为 I I 与 I′ I ′ , k k 为卷积核大小, padding p a d d i n g 与 stride s t r i d e 分别为延拓像素数目与卷积步长。
1.2 转置卷积
二维卷积作为一种降采样的过程,可被GAN中的判别器用作提取特征的手段,值得注意的是,生成器 G G 使用卷积这样的降采样方法显得毫无意义,为了将原始一维噪声变为图像,急需一种升采样方法,转置卷积应运而生。
二维卷积可转换为Toeplitz矩阵与卷积核的矩阵乘法,那么能否使用Toeplitz矩阵将卷积结果还原成原始输入图像的大小?答案是肯定的,即使用Toeplitz矩阵的转置与卷积结果相乘,可以将输出恢复到原始输入图像的大小。转置卷积可以理解为是CNN反向传播求解梯度必要的一步(具体原因可参考BP算法中反向传播公式,权重梯度公式中含有 δTα δ T α 操作)。转置卷积具体演算过程本文不做详细介绍,可参考文献[1]来获得一个更为直观的认识。可以推导出经过转置卷积后输入输出大小变化的公式[1]
其中 I′ I ′ 为经过矩阵内补零操作后得到的新输入矩阵的大小, I I 是原始输入矩阵的大小,根据 I+2padding−k I + 2 p a d d i n g − k 是否为 stride s t r i d e 的整数倍, a a 取0或 (I+2padding−k)%stride ( I + 2 p a d d i n g − k ) % s t r i d e 。
如果将判别器 D D 中CNN的前向传播视为不断使用Toeplitz矩阵与输入计算矩阵乘法,并把CNN的反向传播视为反传误差与Toeplitz 矩阵的转置相乘那么生成器 G G 的前向传播与反向传播过程就是 D D 的反过程。
在确定生成器 G G 和判别器 D D 的前传与反传算法后,就可以用深度卷积网络替代传统基于多层感知机的GAN以提升模型的学习能力。
2可训练性的加强—DCGAN
Alec Radford等人于2016年初提出DCGAN以改善GAN的可训练性[3]。他们认为传统GAN之所以不稳定,一个原因便是判别器 D D 搭载的是初级的多层感知机模型,为了将火热的CNN纳入GAN的体系中,作者将多层感知机用CNN进行替换,并做了如下改进:
- 将池化层用 stride=1 s t r i d e = 1 的卷积层代替
- 将输给生成器 G G 的100维噪声映射为四维张量用作CNN输入而不是向量
- 每进行一次卷积操作就进行批规一化(Batch Normalization)
- 使用ReLU层替换传统的Sigmoid函数,并对输出层使用Tanh激活
- 对判别器 D D 使用LeakyReLU函数作为激活函数
- 移除所有全连接层
在以上改进的支撑下,论文给出了生成器 G G 的网络结构[2]:
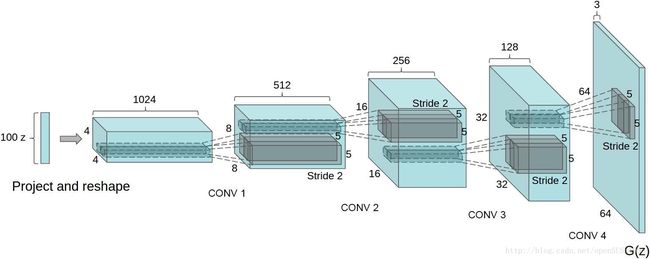
经实验验证,该模型生成的图像较为稳定,虽然只能生成64*64大小的图像,但是这可以通过一些基本的图像处理方法,如金字塔来提升生成图像的分辨率。作者在卧室数据集LSUN上进行了实验,取得了较好的效果

除此之外,作者还发现DCGAN有一个算数加减性质。如下图所示,左侧为图像 A A ,最右侧为图像 B B ,将用于生成图像 A A 的噪声 ZA Z A 与生成 B B 图像的噪声 ZB Z B 每一维度的分量进行从 ZA Z A 到 ZB Z B 的线性插值,可以得到从 A A 图像到 B B 图像的渐变图像。利用该性质,可以生成一些原本数据集中不存在的性质的图像。这一性质有一个有趣的应用,即生成本来不存在的戴墨镜的女性。

在强大的CNN加持下,DCGAN加强了原始GAN的可训练性。下一篇文章将介绍WGAN。该模型将Earth-Mover距离引入GAN模型中,从理论上解决了生成器生成结果不稳定的问题
参考文献:
[1] Dumoulin V., Visin F. A guide to convolution arithmetic for deep learning. https://arxiv.org/pdf/1603.07285.pdf, 2016.pdf, 2016.
[2] Mathwork. MATLAB Docs [EB/OL]. http://cn.mathworks.com/help/matlab/ref/
conv2.html?searchHighlight=conv2&s_tid=doc_srchtitle, 2017.
[3] Radford A., Metz L. Unsupervised Representation Learning with Deep Convolution Generative Adversarial Networks[J]. arXiv:1511.06434,2015.