数据分析利器 —— 列式储存数据库
列式数据库
什么是列式数据库?可能大家也才到了,既然有列式数据库,那么肯定就有行式的喽!确实是这样的。也许大多数人并不了解数据库储存模型(storage model)和数据库的数据模型(data model),不过对上层是使用者也没多大关系。不过我们现在讲的列式和行式就是指数据库的storage model,而他们支持同样的data schema,即对data model感知不到storage model的实现区别。
一个数据库的data model约定可以进行上层数据操作,而storage model决定这些操作的性能。比如,No Sql数据库使用的是data model是key-value,而储存模型有map结构实现,也可以由tree结构实现。而对于sql数据库,其数据模型是一张二维表,而至于怎么存储这张二维表,很容易就可以想到可以按行存储和按列储存。按行存储就是我们现在常见操作型数据库,而是最大众的数据库,比如MySql、Oracle、……等等你所知道大部分数据库。而按列储存的数据库现在也是很有名,比如Hive、Vertica、Druid、Infobright等。
为什么要行式数据库又要列式数据库?
先让让我们想象关于二维表我们有哪些操作?—— select、update、delete和insert。这些操作都会需要找到相应的位置,所以这些操作的基础都是search。
而基本的算法都是即从时间考虑也是从空间考虑的。我们开始具体举个例子。
在数据库储存作为实际的一堆储存在磁盘上的文件,在设计不得不考虑磁盘的特性。一般的磁盘特性,其实所有的储存都有一个特性就是对于locality良好的存取性能是随机存取的好几倍。我们现在把一块想像成一组固定大小的块,如图: disk logic model 而文件的内容实际会被分开按照磁盘逻辑块来储存,数据库主要任务就是怎么组织这些逻辑块来取得更好的读取性能和便捷性。
在不考虑索引的情况下,所有的磁盘读取都是顺序读取,这意味了要查找一个东西,都需要扫描全表或者部分表。很直观的道理,读取的性能就是取决于扫描的范围。范围越大,速度当然越慢。
我们先假设我们有一堆如下的数据:
| RowId | EmpId | Lastname | Firstname | Salary |
|---|---|---|---|---|
| 001 | 10 | Smith | Joe | 40000 |
| 002 | 12 | Jones | Mary | 50000 |
| 003 | 11 | Johnson | Cathy | 44000 |
| 004 | 22 | Jones | Bob | 55000 |
行式储存模型
好现在我们开始让磁盘里塞,假设我们的磁盘块只能容下5个字段(抽象的,假设我们的这些字段的大小都一样),因为我们是按找行优先的,所以结果就如下:
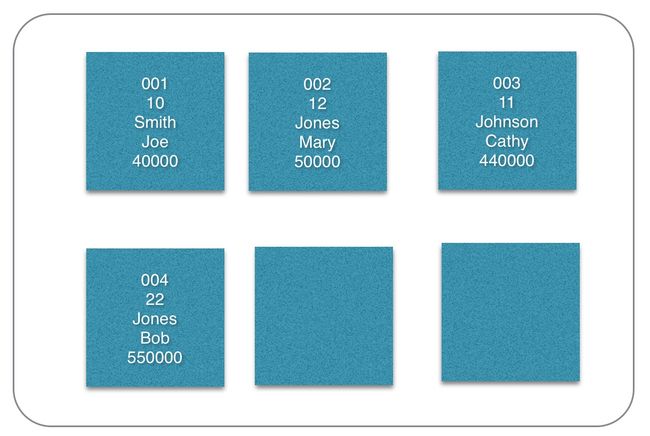
于是当我们要找Jones的所有信息的工资时候,我们会依次从第一块磁盘块直到扫描到最后(为什么要扫到最后,因为是在找全部叫Jones的信息,所以不扫都最后都不能确定是否会遗漏)。一共需要扫4块,然后取出其第二块和第四块信息,找出其工资的信息。
其实基于行式储存,对于where语句处理都需要处理全表。对于磁盘的不停seek,速度就可想而知。当然一般数据库为了应对这种全数据扫描,找到了建立索引的方法。而索引就是对某个或者某些字段的组合的信息,即取出数据的部分信息,以减少每次扫描从全表到部分信息的扫描的过渡。
这种查询方式很适合于一次取出一个行数据,而对于日常应用系统来说这种方式是非常合适的,因为我们设计应用的时候都是针对一个事务,而我们会把一个事务所有属性存储成一行,使用的时候也是有很大的概率涉及到整行的信息,很利于做缓存。还比如我们经常使用的那些经典sql 语句:
select * from user where id = 1001;
select id, user_name, email, address, gender, ... from user where id = 1001;!!还敢不敢列出些更多的字段!!
列式储存模型
而列储存就是下图这种按列优先储存。为了方便我们每块只储存了一个一列,没有存满。

这下我们再考虑上面的查找所有Jones的工资,这下我们只扫描第三个磁盘块,找出Jones都再那些行,然后根据查出来的行号,直接去第五块磁盘(这块对应的式salary列)找出第二、四行的数据,然后输出。一共2次seek。大大小于row-oriented的4次。
这种查询方式的前提就是你就需要这列数据就行了,其前提假设就是查询基本不会使用这个行的其他列数据。显然这种假设对于日常操作系统的围绕着一个主题进行的活动是不合适旳。但是却在分析型数据大显身手。
列式的另一大优势是压缩。因为列的天然凝聚性(比如上面的两个Jones就可以压缩成一个)大大强与行,所以列式储存可以有很高的压缩比,这个进一步使使用的磁盘的数量减少,因为使用的磁盘块少,进一步减少了需要扫描的次数。这方面很利于加快查找速度,但是因为解压缩也是耗时耗内存的过程,所以压缩的控制也是需要一个定平衡点。
优劣总结
从上面的例子可以明显看出列式数据库在分析需求(获取特点——每次查询几个维度,通常是)时候,不仅搜索时间效率占优势,其空间效率也是很明显的。特别是针对动辄按T计算的数据量来说,在分布式环境中能进行压缩处理能节省宝贵的内部带宽,从而提高整个计算任务性能。
关于行式和列式的具体优缺点还有具体的使用场景请看wikipedia。