python pytesser 识别图片验证码
背景:windows7,已安装python2.7,pip,pillow
需要安装:pytesser 和Tesseract,二者是互相依赖的。
因为是windows系统,安装费了好大劲儿,一直各种不成功pytesser,在这里把自己遇到的问题和解决方案捋一下。
首先可以直接使用 pip install Tesseract 安装Tesseract。
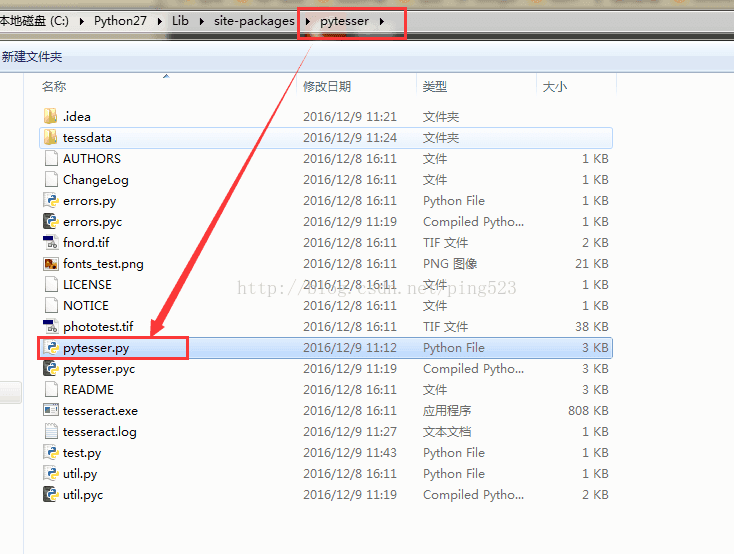
其次,下载pytesser,csdn有很多,下载解压后,重命名文件为:pytesser,然后把该文件放在C:\Python27\Lib\site-packages 目录下(python的安装目录),并且新建一个pytesser.pth文档,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹。
另外注意一下pytesser.py中第六行的import Image,改成from PIL import Image(因为我们安装的不是原版的PIL而是pillow所以要把这个也改一下)
pytesser同时依赖tesseract-ocr,自然是继续安装tesseract-ocr了 。
下载安装包tesseract-ocr-setup-3.02.02.exe
下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
安装时,如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
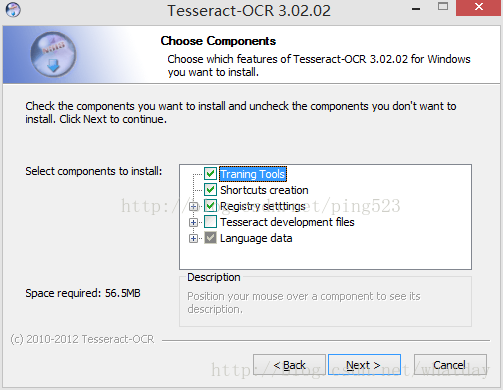
亲测,还是默认安装时间较快。安装好以后,安装目录下的Tesseract-OCR文件夹下也有一个tessdata文件夹,目测内容不一致,还没搞清楚有啥作用和啥区别。
下面就来验证一下:
先来验证pytesser:
在C:/Python27/Lib/site-packages/pytesser目录下,有.tif文件供测试使用。新建一个py文件,里面写入代码:
from pytesser import *
im = Image.open('fnord.tif')
print image_to_string(im)
再来验证tesseract:
打开cmd,输入tesseract,出现以下内容表示安装成功:

我们来使用一下tesseract,看一下识别图片文字的能力和准确性:
找到一张写有hoke的图片,暂时放在了D:下,![]() ,打开命令行,进入D:盘,然后输入
,打开命令行,进入D:盘,然后输入
tesseract hoke.png result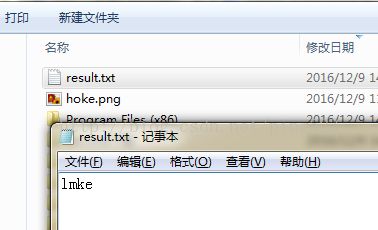
可以看到结果是lmke,还不是很准确,后续继续研究。
如果使用selenium和webdriver+python识别页面上的验证码,可以先识别验证码图片存起来,然后使用命令来读取识别验证码。
参考:http://www.51testing.com/html/14/87714-3693117.html
http://www.th7.cn/Program/Python/201602/768304.shtml