python实战笔记之(3):Selenium模拟浏览器抓取淘宝商品美食信息
淘宝的请求页面是非常复杂的,含有各种请求参数或加密参数,如果直接请求或是分析Ajax将会非常繁琐。Selenium是一个自动化测试工具,它可以驱动浏览器去完成各种操作,比如模拟点击、输入、下拉等各种功能,这样我们就只需要关心操作而不需要关心后台的具体请求过程。本文使用Selenium+Chrome/PhantomJS对淘宝美食信息进行抓取,并存储到MongoDB,使用的解析库是PyQuery。
(1)目标站点分析
首先我们分析一下淘宝站点,打开https://www.taobao.com/,在搜索框输入关键词“美食”,接着进行元素审查,分析原始请求的Response。可以看到,返回结果里有很多js,一些导航内容和css,没有任何的商品信息,其它的请求也比较复杂,包含了很多参数,原始请求的参数也比较多,并且一些参数我们很难直接看出来它的作用:
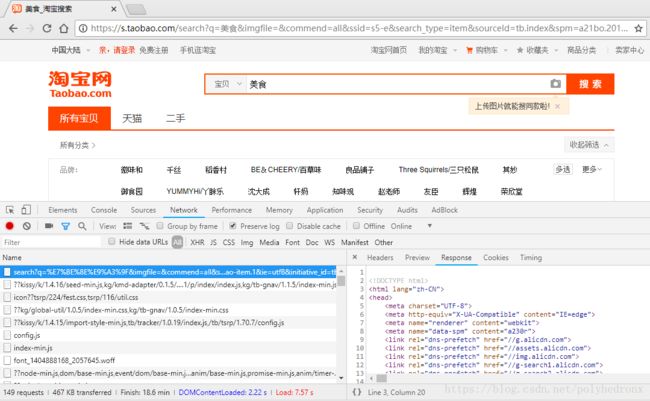

面对一个如此复杂的局面,我们很难通过分析Ajax请求得到想要的信息,所以选用Selenium实现。
(2)流程框架
1.搜索关键字
利用Selenium驱动浏览器搜索关键字,得到查询后的商品列表。
2.分析页码并翻页
得到商品页码数,模拟翻页,得到后续页面的商品列表。
3.分析提取商品内容
利用PyQuery分析源码,解析得到商品列表。
4.存储到MongoDB
将商品列表信息存储到数据库MongoDB。
(3)爬虫代码
# TB_meishi.py
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from TB_meishi_config import *
import pymongo
client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB]
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
def search():
try:
browser.get('https://www.taobao.com')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q")) # 等待元素出现,CSS选择器
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")) # CSS选择器
)
input.send_keys(KEYWORD)
submit.click()
total_page = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")) # CSS选择器
)
get_products()
return total_page.text
except TimeoutException:
return search()
def next_page(page_number):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")) # CSS选择器
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))
)
input.clear()
input.send_keys(page_number)
submit.click()
# 判断页码是否成功切换
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number))
)
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
#等待宝贝信息加载完成
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item")))
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text().replace('\n', ''),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
save_to_mongo(product)
def save_to_mongo(result):
try:
if db[MONGO_DB].insert(result):
print('存储到MongoDB成功', result)
except Exception:
print('存储到MongoDB失败', result)
def main():
try:
total_page = search()
# 正则表达式用()表示要提取的分组
# group(0)是原始字符串,group(1)、group(2)……表示第1、2、……个子串
total_page = int(re.compile('(\d+)').search(total_page).group(1))
for page in range(2, total_page+1):
next_page(page)
except Exception:
print('出错啦!')
finally:
browser.close()
if __name__ == '__main__':
main()
# TB_meishi_config.py
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_TABLE = 'product'
KEYWORD = '美食'
上面是用Chrome浏览器进行爬取的python程序,Chrome方便调试,但缺点就是每次运行程序都会跳出来一个浏览器界面,所以我们改用PhantomJS。下面是PhantomJS的一些介绍和有用信息:
PhantomJS是一个基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于webkit浏览器做的事情,它都能做到。它不仅是个隐形的浏览器,提供了诸如CSS选择器、支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,同时也提供了处理文件I/O的操作,从而使你可以向操作系统读写文件等。PhantomJS的用处可谓非常广泛,诸如网络监测、网页截屏、无需浏览器的 Web 测试、页面访问自动化等。
PhantomJS官方地址:http://phantomjs.org/
PhantomJS官方下载地址:http://phantomjs.org/download.html
PhantomJS官方API:http://phantomjs.org/api/
PhantomJS官方示例:http://phantomjs.org/examples/
PhantomJS GitHub:https://github.com/ariya/phantomjs/
下载完解压并配置到环境变量里就可以了。
下面给出使用PhantomJS进行爬取的程序:
# TB_meishi.py
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from TB_meishi_config import *
import pymongo
client = pymongo.MongoClient(MONGO_URL, connect=False)
db = client[MONGO_DB]
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
wait = WebDriverWait(browser, 10)
# 设置PhantomJS窗口大小
browser.set_window_size(1400, 900)
def search():
print('正在搜索...')
try:
browser.get('https://www.taobao.com')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q")) # 等待元素出现,CSS选择器
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")) # CSS选择器
)
input.send_keys(KEYWORD)
submit.click()
total_page = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")) # CSS选择器
)
get_products()
return total_page.text
except TimeoutException:
return search()
def next_page(page_number):
print('翻页到 page:', page_number)
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")) # CSS选择器
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))
)
input.clear()
input.send_keys(page_number)
submit.click()
# 判断页码是否成功切换
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number))
)
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
#等待宝贝信息加载完成
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item")))
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text().replace('\n', ''),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
save_to_mongo(product)
def save_to_mongo(result):
try:
if db[MONGO_DB].insert(result):
print('存储到MongoDB成功', result)
except Exception:
print('存储到MongoDB失败', result)
def main():
try:
total_page = search()
# 正则表达式用()表示要提取的分组
# group(0)是原始字符串,group(1)、group(2)……表示第1、2、……个子串
total_page = int(re.compile('(\d+)').search(total_page).group(1))
for page in range(2, total_page+1):
next_page(page)
except Exception:
print('出错啦!')
finally:
browser.close()
if __name__ == '__main__':
main()
# TB_meishi_config.py
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_TABLE = 'product'
# 禁止图片加载,并使用缓存
SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
KEYWORD = '美食'
更新:
本来觉得一切都很顺利,今天可以洗洗睡了,临睡前运行一遍程序,竟然爆出了Warning:
![]()
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '翻译过来就是:新版本的Selenium不再支持PhantomJS了,请使用Chrome或Firefox的无头版本来替代。
好吧,既然如此,我们就紧跟时代的步伐,弃用PhantomJS,改用无头版本的Chrome,解决方案如下:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# 禁止加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option('prefs', prefs)
# 使用Headless Chrome
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
更多的Chrome启动参数可以参考这里:http://peter.sh/experiments/chromium-command-line-switches/