深入理解提升树(Boosting tree)算法
- 我的个人微信公众号:Microstrong
微信公众号ID:MicrostrongAI
微信公众号介绍: Microstrong(小强)同学主要研究机器学习、深度学习、计算机视觉、智能对话系统相关内容,分享在学习过程中的读书笔记!期待您的关注,欢迎一起学习交流进步!- 我的知乎主页: https://www.zhihu.com/people/MicrostrongAI/activities
- Github: https://github.com/Microstrong0305
- 个人博客: https://blog.csdn.net/program_developer
- 本文首发在我的微信公众号里,地址:https://mp.weixin.qq.com/s/UepQi5Qezdi27MvbUSyLCA,如有公式和图片不清楚,可以在我的微信公众号里阅读。
目录:
- Boosting基本概念
- 前向分步加法模型
2.1 加法模型
2.2 前向分步算法 - 提升树
3.1 提升树模型
3.2 提升树算法
3.2.1 二叉分类提升树
3.2.1 二叉回归提升树 - 回归提升树示例
- 完整的示例代码
- 关于提升树的若干问题思考
- 总结
- Reference
1. Boosting基本概念
提升(Boosting)方法是一种常用的统计学习方法,应用广泛且有效。在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。
提升方法基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上,就是“三个臭皮匠顶个诸葛亮”的道理。
历史上,Kearns和Valiant首先提出了“强可学习(strongly learnable)”和“弱可学习(weakly learnable)”的概念。指出:在概率近似正确(probably approximately correct,PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。非常有趣的是Schapire后来证明强可学习与弱可学习是等价的,也就是说,在PAC学习的框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。
这样一来,问题便成为,在学习中,如果已经发现了“弱学习算法”,那么能否将它提升(boost)为“强学习算法”。大家知道,发现弱学习算法通常要比发现强学习算法容易得多。那么如何具体实施提升,便成为开发提升方法时所要解决的问题。关于提升方法的研究很多,有很多算法被提出。最具代表性的是AdaBoost算法(AdaBoost algorithm)。
Boosting算法的两个核心问题:
(1)在每一轮如何改变训练数据的权值或概率分布?
AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。
(2)如何将弱分类器组合成一个强分类器?
弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
提升树是以分类树或回归树为基本分类器的提升方法。提升树被认为是统计学习中性能最好的方法之一。提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。下面让我们深入理解提升树的具体算法吧!
2. 前向分步加法模型
2.1 加法模型
考虑加法模型(Additive Model)如下:
f ( x ) = ∑ m = 1 M β m b ( x ; γ m ) f(x) = \sum_{m=1}^{M}{\beta_{m}b(x;\gamma_{m})} f(x)=m=1∑Mβmb(x;γm)
其中, b ( x ; γ m ) b(x;\gamma_{m}) b(x;γm)为基函数, γ m \gamma_{m} γm 为基函数的参数, β m \beta_{m} βm 为基函数的系数。显然上式是一个加法模型。
2.2 前向分布算法
在给定训练数据及损失函数 L ( Y , f ( x ) ) L(Y,f(x)) L(Y,f(x))的条件下,学习加法模型 f ( x ) f(x) f(x) 成为经验风险极小化,即损失函数极小化的问题:
m i n ( β m , γ m ) ∑ i = 1 N L ( y i , ∑ m = 1 M β m b ( x i ; γ m ) ) min_{(\beta_{m},\gamma_{m})}\sum_{i=1}^{N}{L(y_{i},\sum_{m=1}^{M}{\beta_{m}b(x_{i};\gamma_{m})})} min(βm,γm)i=1∑NL(yi,m=1∑Mβmb(xi;γm))
通常这是一个复杂的优化问题。前向分布算法(forward stagewise algorithm)求解这一优化问题的想法是:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近上面要优化的目标函数,那么就可以简化优化的复杂度。
具体地,每步只需优化如下损失函数:
m i n ( β , γ ) ∑ i = 1 N L ( y i , β b ( x i ; γ ) ) min_{(\beta,\gamma)}\sum_{i=1}^{N}{L(y_{i},\beta b(x_{i};\gamma))} min(β,γ)i=1∑NL(yi,βb(xi;γ))
给定训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } , x i ∈ X ⊆ R n , y i ∈ Y = { − 1 , + 1 } T =\left\{ (x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{N}, y_{N})\right\},x_{i}\in X\subseteq R^{n},y_{i}\in Y=\left\{ -1, +1 \right\} T={(x1,y1),(x2,y2),...,(xN,yN)},xi∈X⊆Rn,yi∈Y={−1,+1} 。损失函数 L ( Y , f ( x ) ) L(Y,f(x)) L(Y,f(x))和基函数的集合 { b ( X ; γ ) } \left\{ b(X;\gamma) \right\} {b(X;γ)} ,学习加法模型 f ( x ) f(x) f(x) 的前向分步算法如下:
前向分步算法步骤如下:
输入: 训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T =\left\{ (x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{N}, y_{N})\right\} T={(x1,y1),(x2,y2),...,(xN,yN)} ;损失函数 L ( Y , f ( x ) ) L(Y,f(x)) L(Y,f(x));基函数集 { b ( X ; γ ) } \left\{ b(X;\gamma) \right\} {b(X;γ)};
输出: 加法模型 f ( x ) f(x) f(x)。
(1)初始化 f 0 ( x ) = 0 f_{0}(x)=0 f0(x)=0
(2)对 m = 1 , 2 , . . . , M m=1,2,...,M m=1,2,...,M
(a)极小化损失函数:
( β m , γ m ) = a r g m i n β , γ ∑ i = 1 N L ( y i , f m − 1 ( x i ) + β b ( x i ; γ ) ) (\beta_{m},\gamma_{m})=argmin_{\beta,\gamma}\sum_{i=1}^{N}{L(y_{i},f_{m-1}(x_{i})+\beta b(x_{i};\gamma))} (βm,γm)=argminβ,γi=1∑NL(yi,fm−1(xi)+βb(xi;γ))
得到参数 β m , γ m \beta_{m},\gamma_{m} βm,γm
(b)更新:
f m ( x ) = f m − 1 ( x ) + β m b ( x ; γ m ) f_{m}(x) = f_{m-1}(x)+\beta_{m}b(x;\gamma_{m}) fm(x)=fm−1(x)+βmb(x;γm)
(3)得到加法模型:
f ( x ) = f M ( x ) = ∑ m = 1 M β m b ( x ; γ m ) f(x) = f_{M}(x)=\sum_{m=1}^{M}{\beta_{m}b(x;\gamma_{m})} f(x)=fM(x)=m=1∑Mβmb(x;γm)
这样,前向分步算法将同时求解从 m = 1 m=1 m=1到 M M M的所有参数 β m , γ m \beta_{m} , \gamma_{m} βm,γm 的优化问题简化为逐次求解各个 β m , γ m \beta_{m} , \gamma_{m} βm,γm的优化问题。
3. 提升树
提升树是以分类树或回归树为基本分类器的提升方法。提升树被认为是统计学习中性能最好的方法之一。
3.1 提升树模型
提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。提升树模型可以表示为决策树的加法模型:
f M ( x ) = ∑ m = 1 M T ( x ; Θ m ) f_{M}(x)=\sum_{m=1}^{M}{T(x;\Theta_{m})} fM(x)=m=1∑MT(x;Θm)
其中, T ( x ; Θ m ) T(x;\Theta_{m}) T(x;Θm) 表示决策树; Θ m \Theta_{m} Θm 为决策树的参数; M M M为树的个数。
3.2 提升树算法
提升树算法采用前向分步算法。首先确定初始提升树 f 0 ( x ) = 0 f_{0}(x) = 0 f0(x)=0 ,第 m m m步的模型是:
f m ( x ) = f m − 1 ( x ) + T ( x ; Θ m ) f_{m}(x)=f_{m-1}(x)+T(x;\Theta_{m}) fm(x)=fm−1(x)+T(x;Θm)
其中, f m − 1 ( x ) f_{m-1}(x) fm−1(x) 为当前模型,通过经验风险极小化确定下一棵决策树的参数 Θ m \Theta_{m} Θm :
Θ ^ m = a r g m i n ( Θ m ) ∑ i = 1 N L ( y i , f m − 1 ( x i ) + T ( x i ; Θ m ) ) \hat{\Theta}_{m}=argmin_{(\Theta_{m})}\sum_{i=1}^{N}{L(y_{i},f_{m-1}(x_{i})+T(x_{i};\Theta_{m}))} Θ^m=argmin(Θm)i=1∑NL(yi,fm−1(xi)+T(xi;Θm))
由于树的线性组合可以很好地拟合训练数据,即使数据中的输入与输出之间的关系很复杂也是如此,所以提升树是一个高功能的学习算法。
下面讨论针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同。包括用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题。
3.2.1 二叉分类提升树
对于二分类问题,提升树算法只需将AdaBoost算法中的基本分类器限制为二类分类树即可,可以说这时的提升树算法是AdaBoost算法的特殊情况,这里不再细述。下面叙述回归问题的提升树。
3.2.2 二叉回归提升树
已知一个训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } , x i ∈ X ⊆ R n T =\left\{ (x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{N}, y_{N})\right\},x_{i}\in X\subseteq R^{n} T={(x1,y1),(x2,y2),...,(xN,yN)},xi∈X⊆Rn, x x x为输入空间, y i ∈ Y ⊆ R y_{i}\in Y\subseteq R yi∈Y⊆R , y y y为输出空间。如果将输入空间 x x x划分为 J J J个互不相交的区域 R 1 , R 2 , . . . , R J R_{1},R_{2},...,R_{J} R1,R2,...,RJ ,并且在每个区域上确定输出的常量 c j c_{j} cj ,那么树可表示为:
T ( x ; Θ ) = ∑ j = 1 J c j I ( x ∈ R j ) T(x;\Theta) =\sum_{j=1}^{J}{c_{j}I(x\in R_{j})} T(x;Θ)=j=1∑JcjI(x∈Rj)
其中,参数 Θ = { ( R 1 , c 1 ) , ( R 2 , c 2 ) , . . . , ( R J , c J ) } \Theta = \left\{ (R_{1}, c_{1}),(R_{2},c_{2}),...,(R_{J},c_{J}) \right\} Θ={(R1,c1),(R2,c2),...,(RJ,cJ)} 表示树的区域划分和各区域上的常数。 J J J是回归树的复杂度即叶结点个数。
回归问题提升树使用以下前向分步算法:
f 0 ( x ) = 0 f_{0}(x)=0 f0(x)=0
f m ( x ) = f m − 1 ( x ) + T ( x ; Θ m ) , m = 1 , 2 , . . . , M f_{m}(x) = f_{m-1}(x)+T(x;\Theta_{m}),m=1,2,...,M fm(x)=fm−1(x)+T(x;Θm),m=1,2,...,M
f M ( x ) = ∑ m = 1 M T ( x ; Θ m ) f_{M}(x)=\sum_{m=1}^{M}{T(x;\Theta_{m})} fM(x)=m=1∑MT(x;Θm)
在前向分步算法的第 m m m步,给定当前模型 f m − 1 ( x ) f_{m-1}(x) fm−1(x) ,需求解:
Θ ^ m = a r g m i n ( Θ m ) ∑ i = 1 N L ( y i , f m − 1 ( x i ) + T ( x i ; Θ m ) ) \hat{\Theta}_{m} = argmin_{(\Theta_{m})}\sum_{i=1}^{N}{L(y_{i},f_{m-1}(x_{i})+T(x_{i};\Theta_{m}))} Θ^m=argmin(Θm)i=1∑NL(yi,fm−1(xi)+T(xi;Θm))
得到 Θ ^ m \hat{\Theta}_{m} Θ^m ,即第 m m m棵树的参数。
当采用平方误差损失函数时, L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y,f(x))=(y-f(x))^2 L(y,f(x))=(y−f(x))2 ,其损失变为:
L ( y , f m − 1 ( x ) + T ( x ; Θ m ) ) = [ y − f m − 1 ( x ) − T ( x ; Θ m ) ] 2 = [ r − T ( x ; Θ m ) ] 2 L(y,f_{m-1}(x)+T(x;\Theta_{m}))=[y-f_{m-1}(x)-T(x;\Theta_{m})]^2=[r-T(x;\Theta_{m})]^2 L(y,fm−1(x)+T(x;Θm))=[y−fm−1(x)−T(x;Θm)]2=[r−T(x;Θm)]2
这里, r = y − f m − 1 ( x ) r = y-f_{m-1}(x) r=y−fm−1(x) ,是当前模型拟合数据的残差(residual)。所以,对回归问题的提升树算法来说,只需简单地拟合当前模型的残差。这样,算法是相当简单的。现在将回归问题的提升树算法叙述如下:

4. 回归提升树示例
本示例来源于李航著的《统计学习方法》第8章提升方法中的例8.2。已知如表1所示的训练数据,x的取值范围为区间[0.5, 10.5],y的取值范围为区间[5.0, 10.0],学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
说明:树桩是由一个根节点直接连接两个叶结点的简单决策树。

按照算法8.3,第1步求 f 1 ( x ) f_{1}(x) f1(x) 即回归树 T 1 ( x ) T_{1}(x) T1(x) 。
样本输入空间划分的基本步骤如下:
首先通过以下优化问题:
m i n ( s ) [ m i n ( c 1 ) ∑ x i ∈ R 1 ( y i − c 1 ) 2 + m i n ( c 2 ) ∑ x i ∈ R 2 ( y i − c 2 ) 2 ] min_{(s)}[min_{(c_{1})} \sum_{x_{i}\in R_{1}}^{}{(y_{i}-c_{1})^2}+min_{(c_{2})} \sum_{x_{i}\in R_{2}}^{}{(y_{i}-c_{2})^2}] min(s)[min(c1)xi∈R1∑(yi−c1)2+min(c2)xi∈R2∑(yi−c2)2]
求解训练数据的切分点 s s s:
R 1 = { x ∣ x ≤ s } , R 2 = { x ∣ x > s } R_{1} = \left\{ x|x\leq s \right\}, R_{2}=\left\{ x|x>s \right\} R1={x∣x≤s},R2={x∣x>s}
容易求得在 R 1 , R 2 R_{1}, R_{2} R1,R2 内部使平方损失误差达到最小的 c 1 , c 2 c_{1},c_{2} c1,c2 为:
c 1 = 1 N 1 ∑ x i ∈ R 1 y i , c 2 = 1 N 2 ∑ x i ∈ R 2 y i c_{1}=\frac{1}{N_{1}}\sum_{x_{i} \in R_{1}}^{}{y_{i}}, c_{2}=\frac{1}{N_{2}}\sum_{x_{i} \in R_{2}}^{}{y_{i}} c1=N11xi∈R1∑yi,c2=N21xi∈R2∑yi
这里 N 1 , N 2 是 R 1 , R 2 N_{1},N_{2} 是 R_{1},R_{2} N1,N2是R1,R2 的样本点数。
(1)求训练数据的切分点
这里的切分点指的是将 x x x值划分界限,数据中x的范围是[1,10],假设我们考虑如下切分点:
1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5
对各切分点,不难求出相应的 R 1 , R 2 , c 1 , c 2 R_{1},R_{2},c_{1},c_{2} R1,R2,c1,c2 及 m ( s ) m(s) m(s), m ( s ) m(s) m(s)计算公式如下:
m ( s ) = m i n ( c 1 ) ∑ x i ∈ R 1 ( y i − c 1 ) 2 + m i n ( c 2 ) ∑ x i ∈ R 2 ( y i − c 2 ) 2 m(s)=min_{(c_{1})}\sum_{x_{i}\in R_{1}}^{}{(y_{i}-c_{1})^2}+min_{(c_{2})}\sum_{x_{i}\in R_{2}}^{}{(y_{i}-c_{2})^2} m(s)=min(c1)xi∈R1∑(yi−c1)2+min(c2)xi∈R2∑(yi−c2)2
例如:当 s = 1.5 s=1.5 s=1.5时, R 1 = { 1 } , R 2 = { 2 , 3 , . . . , 10 } R_{1}=\left\{ 1 \right\}, R_{2}=\left\{ 2,3,...,10 \right\} R1={1},R2={2,3,...,10} ,那么:
c 1 = 5.56 c_{1} = 5.56 c1=5.56
c 2 = 1 9 ( 5.70 + 5.91 + 6.40 + 6.80 + 7.05 + 8.90 + 8.70 + 9.00 + 9.05 ) = 7.50 c_{2} = \frac{1}{9}\left( 5.70+5.91+6.40+6.80+7.05+8.90+8.70+9.00+9.05 \right)=7.50 c2=91(5.70+5.91+6.40+6.80+7.05+8.90+8.70+9.00+9.05)=7.50
m ( 1.5 ) = m i n ( c 1 ) ∑ x i ∈ R 1 ( y i − c 1 ) 2 + m i n ( c 2 ) ∑ x i ∈ R 2 ( y i − c 2 ) 2 = 0 + 15.72 = 15.72 m(1.5) = min_{(c_{1})}\sum_{x_{i}\in R_{1}}^{}{(y_{i}-c_{1})^2}+min_{(c_{2})}\sum_{x_{i}\in R_{2}}^{}{(y_{i}-c_{2})^2} = 0 + 15.72 = 15.72 m(1.5)=min(c1)xi∈R1∑(yi−c1)2+min(c2)xi∈R2∑(yi−c2)2=0+15.72=15.72
现将 s s s及 m ( s ) m(s) m(s)的计算结果列表如下:

(2)求回归树
由表2可知,当 s = 6.5 s=6.5 s=6.5时, m ( s ) m(s) m(s)达到最小值,此时 R 1 = { 1 , 2 , . . , 6 } , R 2 = { 7 , 8 , 9 , 10 } R_{1}=\left\{ 1,2,..,6 \right\}, R_{2}=\left\{ 7,8,9,10 \right\} R1={1,2,..,6},R2={7,8,9,10} ,且:
c 1 = 1 6 ( 5.56 + 5.70 + 5.91 + 6.40 + 6.80 + 7.05 ) = 6.24 c_{1}=\frac{1}{6}(5.56+5.70+5.91+6.40+6.80+7.05) = 6.24 c1=61(5.56+5.70+5.91+6.40+6.80+7.05)=6.24
c 2 = 1 4 ( 8.90 + 8.70 + 9.00 + 9.05 ) = 8.91 c_{2} = \frac{1}{4} (8.90+8.70+9.00+9.05)=8.91 c2=41(8.90+8.70+9.00+9.05)=8.91
因此,回归树 T 1 ( x ) T_{1}(x) T1(x) 为:

(3)求当前加法模型 f 1 ( x ) f_{1}(x) f1(x)
当前的加法模型为:
f 1 ( x ) = T 1 ( x ) f_{1}(x) = T_{1}(x) f1(x)=T1(x)
(4)求当前加法模型的残差
用 f 1 ( x ) f_{1}(x) f1(x) 拟合训练数据的残差如表3,表中 r 2 i = y i − f 1 ( x i ) , i = 1 , 2 , . . . , 10 r_{2i}=y_{i}-f_{1}(x_{i}),i=1,2,...,10 r2i=yi−f1(xi),i=1,2,...,10。

用 f 1 ( x ) f_{1}(x) f1(x)拟合训练数据的平方损失误差为:
L ( y , f 1 ( x ) ) = ∑ i = 1 10 ( y i − f 1 ( x i ) ) 2 = 1.93 L(y,f_{1}(x)) = \sum_{i=1}^{10}{(y_{i}-f_{1}(x_{i}))^2=1.93} L(y,f1(x))=i=1∑10(yi−f1(xi))2=1.93
这里的误差为 1.93 1.93 1.93,如果我们定义终止时候的误差比这个误差要小,那么算法继续执行以上步骤,直到满足误差为止。
第2步,求回归树 T 2 ( x ) T_{2}(x) T2(x) 。方法与求 T 1 ( x ) T_{1}(x) T1(x)一样,只是拟合的数据是表3的残差。
(1)求解数据的切分点
仍然对区域 R = { 1 , 2 , . . , 10 } R=\left\{ 1,2,..,10 \right\} R={1,2,..,10} 求解数据的切分点。当 s = 1.5 s=1.5 s=1.5时, R 1 ′ = { 1 } , R 2 ′ = { 2 , 3 , . . . , 10 } R_{1^{'}}=\left\{ 1 \right\}, R_{2^{'}}=\left\{ 2,3,...,10 \right\} R1′={1},R2′={2,3,...,10} ,那么:
c 1 ′ = − 0.68 c_{1^{'}} = -0.68 c1′=−0.68
c 2 ′ = 1 9 ( − 0.54 − 0.33 + 0.16 + 0.56 + 0.81 − 0.01 − 0.21 + 0.09 + 0.14 ) = 0.07 c_{2^{'}}= \frac{1}{9}(-0.54-0.33+0.16+0.56+0.81-0.01-0.21+0.09+0.14)= 0.07 c2′=91(−0.54−0.33+0.16+0.56+0.81−0.01−0.21+0.09+0.14)=0.07
m ( 1.5 ) = m i n ( c 1 ) ∑ x i ∈ R 1 ( r 2 i − c 1 ) 2 + m i n ( c 2 ) ∑ x i ∈ R 2 ( r 2 i − c 2 ) 2 = 0 + 1.42 = 1.42 m(1.5) = min_{(c_{1})}\sum_{x_{i}\in R_{1}}^{}{(r_{2i}-c_{1})^2}+min_{(c_{2})}\sum_{x_{i}\in R_{2}}^{}{(r_{2i}-c_{2})^2} = 0 + 1.42 = 1.42 m(1.5)=min(c1)xi∈R1∑(r2i−c1)2+min(c2)xi∈R2∑(r2i−c2)2=0+1.42=1.42
现将 s s s及 m ( s ) m(s) m(s)的计算结果列表如下(见表4):

(2)求回归树
由表4可知,当 s = 3.5 s=3.5 s=3.5时 m ( s ) m(s) m(s)达到最小值,此时 R 1 ′ = { 1 , 2 , 3 } , R 2 ′ = { 4 , 5 , . . . , 10 } , c 1 = − 0.52 , c 2 = 0.22 R_{1^{'}}=\left\{ 1,2,3 \right\}, R_{2^{'}}=\left\{ 4,5,...,10 \right\}, c_{1} = -0.52, c_{2}=0.22 R1′={1,2,3},R2′={4,5,...,10},c1=−0.52,c2=0.22 ,所以回归树 T 2 ( x ) T_{2}(x) T2(x) 为:
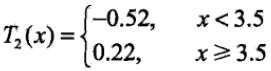
(3)求当前加法模型 f 2 ( x ) f_{2}(x) f2(x)
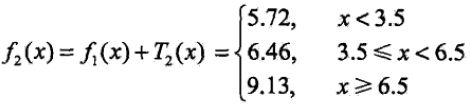
(4)求当前加法模型的残差
用 f 2 ( x ) f_{2}(x) f2(x) 拟合训练数据的残差如表5,表中 r 3 i = y i − f 2 ( x i ) , i = 1 , 2 , . . . , 10 r_{3i}=y_{i}-f_{2}(x_{i}),i=1,2,...,10 r3i=yi−f2(xi),i=1,2,...,10 。

用 f 2 ( x ) f_{2}(x) f2(x) 拟合训练数据的平方损失误差是:

之后的过程同步骤2一样,我就不在这里赘述啦!最后,给出完整的回归提升树模型。

5. 完整的示例代码
本篇文章所有数据集和代码均在我的GitHub中,地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/blob/master/Ensemble%20Learning/Regression_BoostingDecisionTree.py
# coding=utf-8
import numpy as np
label = np.array([5.56, 5.7, 5.91, 6.4, 6.8, 7.05, 8.9, 8.7, 9, 9.05])
# 已经排好序了。实际情况中单一特征的数据或者多特征的数据,选择切分点的时候也像决策树一样选择
feature = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
class Tree_model:
def __init__(self, stump, mse, left_value, right_value, residual):
'''
:param stump: 为feature最佳切割点
:param mse: 为每棵树的平方误差
:param left_value: 为决策树左值
:param right_value: 为决策树右值
:param residual: 为每棵决策树生成后余下的残差
'''
self.stump = stump
self.mse = mse
self.left_value = left_value
self.right_value = right_value
self.residual = residual
'''根据feature准备好切分点。例如:
feature为[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
切分点为[1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5]
'''
def Get_stump_list(feature):
# 特征值从小到大排序好,错位相加
tmp1 = list(feature.copy())
tmp2 = list(feature.copy())
tmp1.insert(0, 0)
tmp2.append(0)
stump_list = ((np.array(tmp1) + np.array(tmp2)) / float(2))[1:-1]
return stump_list
# 此处的label其实是残差
def Get_decision_tree(stump_list, feature, label):
best_mse = np.inf
best_stump = 0 # min(stump_list)
residual = np.array([])
left_value = 0
right_value = 0
for i in range(np.shape(stump_list)[0]):
left_node = []
right_node = []
for j in range(np.shape(feature)[0]):
if feature[j] < stump_list[i]:
left_node.append(label[j])
else:
right_node.append(label[j])
left_mse = np.sum((np.average(left_node) - np.array(left_node)) ** 2)
right_mse = np.sum((np.average(right_node) - np.array(right_node)) ** 2)
# print("decision stump: %d, left_mse: %f, right_mse: %f, mse: %f" % (i, left_mse, right_mse, (left_mse + right_mse)))
if best_mse > (left_mse + right_mse):
best_mse = left_mse + right_mse
left_value = np.average(left_node)
right_value = np.average(right_node)
best_stump = stump_list[i]
left_residual = np.array(left_node) - left_value
right_residual = np.array(right_node) - right_value
residual = np.append(left_residual, right_residual)
# print("decision stump: %d, residual: %s"% (i, residual))
Tree = Tree_model(best_stump, best_mse, left_value, right_value, residual)
return Tree, residual
# Tree_num就是树的数量
def BDT_model(feature, label, Tree_num=100):
feature = np.array(feature)
label = np.array(label)
stump_list = Get_stump_list(feature)
Trees = []
residual = label.copy()
# 产生每一棵树
for num in range(Tree_num):
# 每次新生成树后,还需要再次更新残差residual
Tree, residual = Get_decision_tree(stump_list, feature, residual)
Trees.append(Tree)
return Trees
def BDT_predict(Trees, feature):
predict_list = [0 for i in range(np.shape(feature)[0])]
# 将每棵树对各个特征预测出来的结果进行相加,相加的最后结果就是最后的预测值
for Tree in Trees:
for i in range(np.shape(feature)[0]):
if feature[i] < Tree.stump:
predict_list[i] = predict_list[i] + Tree.left_value
else:
predict_list[i] = predict_list[i] + Tree.right_value
return predict_list
# 计算误差
def Get_error(predict, label):
predict = np.array(predict)
label = np.array(label)
error = np.sum((label - predict) ** 2)
return error
Trees = BDT_model(feature, label)
predict = BDT_predict(Trees, feature)
print("The error is ", Get_error(predict, label))
print(predict)
6. 关于提升树的若干问题思考
(1)提升树与回归树之间的关系?
以决策树为基函数的提升方法称为提升树,对分类问题决策树为二叉分类树,对回归问题决策树是二叉回归树。
(2)提升树与梯度提升的区别?
李航老师《统计学习方法》中提到了在使用平方误差损失函数和指数损失函数时,提升树的残差求解比较简单,但是在使用一般的损失误差函数时,残差求解起来不是那么容易。针对这一问题,Freidman提出了梯度提升(Gradient Boosting)算法,就是利用最速下降法的近似方法,关键是利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
(3)提升树与GBDT之间的关系?
提升树模型每一次的提升都是靠上次的预测结果与训练数据中label值的差值作为新的训练数据进行重新训练,由于原始的回归树指定了平方损失函数所以可以直接计算残差,而梯度提升决策树(Gradient Boosting Decision Tree, GDBT)针对的是一般损失函数,所以采用负梯度来近似求解残差,将残差计算替换成了损失函数的梯度方向,将上一次的预测结果带入梯度中求出本轮的训练数据。这两种模型就是在生成新的训练数据时采用了不同的方法。
思考:讲到这里我又有一个问题,李航老师的《统计学习方法》中提到的梯度提升与GBDT又有什么区别和联系呢?这个问题我还没有想明白,暂且留在这里吧!
7. 总结
本文讨论了针对不同问题的提升树学习算法,它们的主要区别在于使用的损失函数不同。包括用平方误差损失函数的回归问题,例如,本文讲解的回归问题的提升树算法;用指数损失函数的分类问题,例如,基本分类器是二分类树的AdaBoost算法;以及用一般损失函数的一般决策问题,例如梯度提升算法。
Boosting族代表性算法包括:GBDT、XGBoost(eXtreme Gradient Boosting)、LightGBM (Light Gradient Boosting Machine)和CatBoost(Categorical Boosting)等,提升树算法是这些Boosting族高级算法的基础。因此,深入理解提升树算法对于我们后续学习Boosting族高级算法很重要。
8. Reference
【1】《统计学习方法》,李航著。
【2】提升树(Boosting tree)算法总结,地址:http://ihoge.cn/2018/boosting.html
【3】提升树boosting tree模型,地址:https://blog.csdn.net/hao5335156/article/details/82467463
【4】李航 统计学习方法 林轩田 GBDT算法用于回归 python实现,地址:https://blog.csdn.net/m0_37534550/article/details/85787566
【5】提升树GBDT详解,地址:https://blog.csdn.net/sb19931201/article/details/52506157
【6】集成学习-提升树和GBDT - 涨知识的猴头菇的文章 - 知乎 https://zhuanlan.zhihu.com/p/35796662