纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception
https://zhuanlan.zhihu.com/p/32746221
https://zhuanlan.zhihu.com/p/35405071
一、简介
虽然网络性能得到了提高,但随之而来的就是效率问题。
效率问题主要是模型的存储问题和模型进行预测的速度问题(以下简称速度问题)
- 第一,存储问题。数百层网络有着大量的权值参数,保存大量权值参数对设备的内存要求很高;
- 第二,速度问题。在实际应用中,往往是毫秒级别,为了达到实际应用标准,要么提高处理器性能(看英特尔的提高速度就知道了,这点暂时不指望),要么就减少计算量
只有解决 CNN 效率问题,才能让 CNN 走出实验室,更广泛的应用于移动端。对于效率问题,通常的方法是进行模型压缩(Model Compression),即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题。
二、轻量化模型
1.SqueezeNet
创新点
采用不同于传统的卷积方式,提出 fire module,整个网络是由fire module堆叠而成的。fire module 包含两部分:squeeze 层+expand 层。squeeze 层,该层采用 1*1 卷积核对上一层 feature map 进行卷积,主要目的是减少 feature map 的维数。Expand 层分别用 1*1 和 3*3 卷积,然后 concat,这个操作在 inception 系列里面也有。
具体操作情况如下图所示:

网络结构

Loss函数
softmax函数
ground convolution
https://zhuanlan.zhihu.com/p/48261931
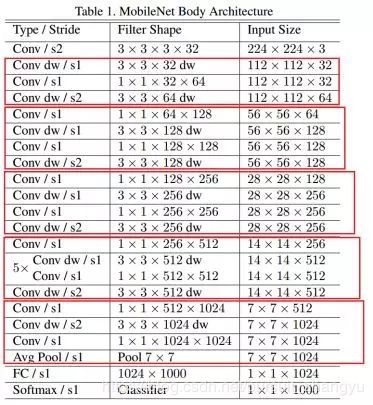
2、MobileNet
一般feature map(H*W*C)进行卷积的时候,卷积核的大小是(DH*DW*C*C1),输出的结果是(H*W*C1)。MobileNet中的depth-wise convolution的做法是将卷积核变为(H*W*C),然后逐通道进行卷积。这样子参数量和计算时间会大幅下降,但是也会带来问题,feature map中的空间信息怎么办,采用的是pointwise convolution 方法,具体使用的卷积核是1*1*C*C1,输出为H*W*C1。没有考虑步长为2的问题
创新点
采用名为 depth-wise separable convolution 的卷积方式代替传统卷积方式,以达到减少网络权值参数的目的。
而 depth-wise convolution + pointwise convolution 需要的卷积核呢?
Depth-wise convolution :一个卷积核负责一个通道,一个通道只被一个卷积核卷积;则这里有 M 个 DK*DK 的卷积核;
Pointwise convolution:为了达到输出 N 个 feature map 的操作,所以采用 N 个 M*1*1 的卷积核进行卷积,这里的卷积方式和传统的卷积方式是一样的,只不过采用了 M*1*1 的卷积核;其目的就是让新的每一个 feature map 包含有上一层各个 feature map 的信息!在此理解为将 depth-wise convolution 的输出进行「串」起来。
depth-wise convolution 和 group convolution 是类似的,depth-wise convolution 是一个卷积核负责一部分 feature map,每个 feature map 只被一个卷积核卷积;group convolution 是一组卷积核负责一组 feature map,每组 feature map 只被一组卷积核卷积。Depth-wise convolution 可以看成是特殊的 group convolution,即每一个通道是一组。
网络结构
3、ShuffleNet
shuffleNet的本质是将卷积运算限制在每个Group内,这样模型的计算量取得了显著的下降。然而导致模型的信息流限制在各个Group内,组与组之间没有信息交换,如图15,这会影响模型的表示能力。因此,需要引入组间信息交换的机制,即Channel Shuffle(通道重排)操作。具体来说是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map。
创新点
1. 利用 group convolution 和 channel shuffle 这两个操作来设计卷积神经网络模型, 以减少模型使用的参数数量。
shuffle 具体来说是 channel shuffle,是将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 是用 point-wise convolution 解决的这个问题)
具体方法为:把各组的 channel 平均分为 g(下图 g=3)份,然后依次序的重新构成 feature map

图(a)为group操作,图(b)为shuffleNet,图©为shuffleNet详细描述。
2.ShuffleNet 借鉴了 Resnet 的思想,从基本的 resnet 的 bottleneck unit 逐步演变得到 ShuffleNet 的 bottleneck unit,然后堆叠的使用 ShuffleNet bottleneck unit 获得 ShuffleNet;
下图展示了 ShuffleNet unit 的演化过程
- 图 (a):是一个带有 depth-wise convolution 的 bottleneck unit;
- 图 (b):作者在 (a) 的基础上进行变化,对 1*1 conv 换成 1*1 Gconv,并在第一个 1*1 Gconv 之后增加一个 channel shuffle 操作;
- 图 (c): 在旁路增加了 AVG pool,目的是为了减小 feature map 的分辨率;因为分辨率小了,于是乎最后不采用 Add,而是 concat,从而「弥补」了分辨率减小而带来的信息损失。

4、Xception
创新点
1. 借鉴(非采用)depth-wise convolution 改进 Inception V3
卷积的时候要将通道的卷积与空间的卷积进行分离
https://zhuanlan.zhihu.com/p/35405071
https://www.zhihu.com/question/265709710
5、MobileNet v2
paper
MobileNet V2是Google继V1之后提出的下一代轻量化网络,主要解决了V1在训练过程中非常容易特征退化的问题,V2相比V1效果有一定提升。
第一版MobileNet v1没有使用residual connection,在第二版在借鉴了residual connection。但是在借鉴的过程中又对网络进行了改进。
- v1 的微结构

- v2 的微结构

可以看到有两个区别。
1. v2在原有的dw之前加了一个pw专门用来升维。这么做是因为dw是小受,给多少通道就输出多少通道,本身没法改变通道数,先加pw升维后,dw就能在高维提特征了。
2. v2把原本dw之后用来降维的pw后的激活函数给去掉了。 这么做据作者说是因为他认为非线性在高维有益处,但在低维(例如pw降维后的空间)不如线性好。
首先说明一下ReLU6,卷积之后通常会接一个ReLU非线性激活,在Mobile v1里面使用ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip)。
2. MobileNet v2 与 ResNet 微结构的区别
- ResNet 的微结构(Residual Module)

- MobileNet v2 的微结构(Inverted Residual Module)

可以看到基本结构很相似。不过ResNet是先降维(0.25倍)、提特征、再升维。而v2则是先升维(6倍)、提特征、再降维。另外v2也用DW代替了标准卷积来做特征提取。
注:上面的示意表达式省略了Shortcut。
6、MobileNet v3
https://www.jiqizhixin.com/articles/2019-05-09-2
https://blog.csdn.net/DL_wly/article/details/90168883
整体来说MobileNetV3有两大创新点
(1)互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
(2)网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
(3)MnasNet 模型引入的基于squeeze and excitation结构的轻量级注意力模型。
h-swish激活函数
2.另外,作者发现一种新出的激活函数swish x 能有效改进网络精度:
![]() 但就是计算量太大了。
但就是计算量太大了。
于是作者对这个函数进行了数值近似:
 事实证明,这个近似很有效:
事实证明,这个近似很有效:

从图形上看出,这两个函数的确很接近。
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
CNN中计算量FLOPs的计算
1、FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
2、计算过程:

如上,根据上图来计算第一层卷积层的FLOPs:
对于某个卷积层,它的FLOPs数量为:![]() ,其中
,其中![]() 表示该层参数的数目。
表示该层参数的数目。
这里AlexNet网络第一卷积层为例,它的FLOPs数目为: ![]() 。
。
ShuffleNet v2
https://blog.csdn.net/u014380165/article/details/81322175
目前大部分的模型加速和压缩文章在对比加速效果时用的指标都是FLOPs(float-point operations),这个指标主要衡量的就是卷积层的乘法操作。但是这篇文章通过一系列的实验发现FLOPs并不能完全衡量模型速度,比如在Figure1(c)(d)中,相同MFLOPs的网络实际速度差别却很大,因此以FLOPs作为衡量模型速度的指标是有问题的。
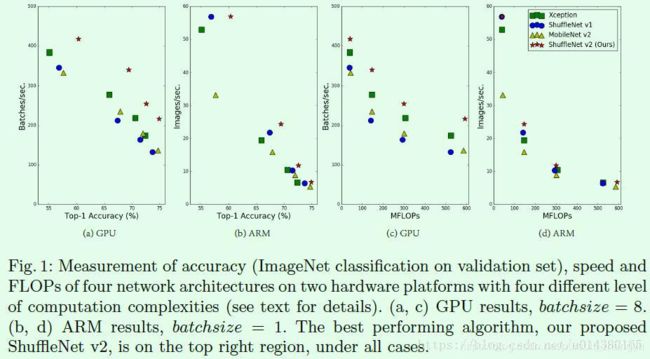
那么,为什么FLOPs相同的模型速度差别会那么大?这也是这篇文章的出发点和后续4个主要实验要证明的内容。首先直观的一点是内存访问消耗时间(memory access cost 缩写为 MAC)是需要计算的,这对模型速度影响比较大,但是却难以在FLOPs指标中体现出来。这个MAC指标将在出现在后续几个实验中,接下来分别介绍这4个实验。
https://zhuanlan.zhihu.com/p/48261931
通过上面的4个实验,论文中针对高性能网络提出了4点准则。
(1)使用相同的通道宽度的卷积
(2) 不要过度使用组卷积,,这会增加内存访问成本。
(3)降低碎片化程度((比如Inception中的多路径)
(4)减少元素级运算(比如element wise add)
group conv的计算量看起来是比较低,但是实际算法跑起来,慢。因为group conv卷积在实现的时候就是将Feature Map进行分片,GPU对矩阵的操作支持的很好,但是这样group conv就会抹除掉这种优势。
为了设计高性能网络,对ShuffleNet v1网络进行了改进。
Figure3是关于ShuffleNet v1和ShuffleNet v2的结构对比,其中(a)和(b)是ShuffleNet v1的两种不同block结构,两者的差别在于后者对特征图尺寸做了缩小,这和ResNet中某个stage的两种block功能类似,同理(c)和(d)是ShuffleNet v2的两种不同block结构。从(a)和(c)的对比可以看出首先(c)在开始处增加了一个channel split操作,这个操作将输入特征的通道分成c-c’和c’,c’在文章中采用c/2,这主要是和前面第1点发现对应。然后(c)中取消了1*1卷积层中的group操作,这和前面第2点发现对应,同时前面的channel split其实已经算是变相的group操作了。其次,channel shuffle的操作移到了concat后面,和前面第3点发现对应,同时也是因为第一个1*1卷积层没有group操作,所以在其后面跟channel shuffle也没有太大必要。最后是将element-wise add操作替换成concat,这个和前面第4点发现对应。多个(c)结构连接在一起的话,channel split、concat和channel shuffle是可以合并在一起的。(b)和(d)的对比也是同理,只不过因为(d)的开始处没有channel split操作,所以最后concat后特征图通道数翻倍。 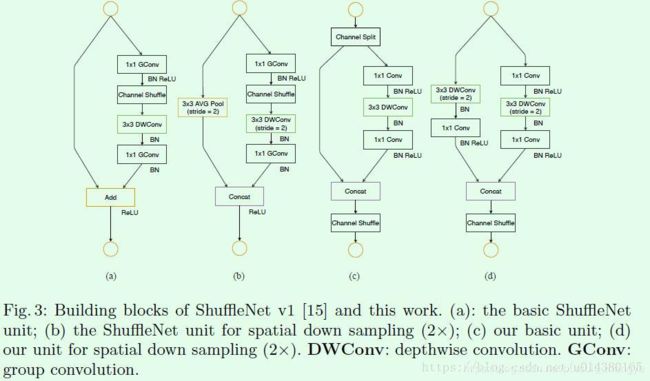
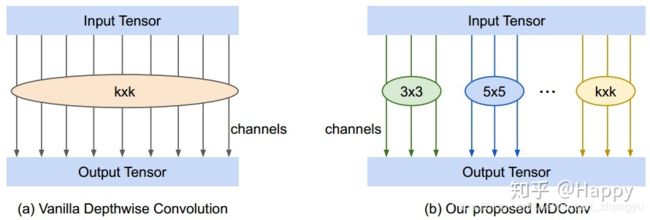
MixNet解读
https://zhuanlan.zhihu.com/p/75242090
自己的话
作者发现一个相同的网络结构(mobileNet v1, mobileNet v2)改变卷积(kernel)的小会对精度产生影响。基于此,作者提出一种新的混合深度卷积(Mixed Depthwise Convolution, MDConv),它很自然的将多个尺寸卷积核混叠到同一个卷积中。