Hadoop实战:明星搜索指数统计,找出人气王
项目介绍
本项目我们使用明星搜索指数数据,分别统计出搜索指数最高的男明星和女明星。
数据集
明星搜索指数数据集,如下图所示。猛戳此链接下载数据集

思路分析
基于项目的需求,我们通过以下几步完成:
1、编写 Mapper类,按需求将数据集解析为 key=gender,value=name+hotIndex,然后输出。
2、编写 Combiner 类,合并 Mapper 输出结果,然后输出给 Reducer。
3、编写 Partitioner 类,按性别,将结果指定给不同的 Reduce 执行。
4、编写 Reducer 类,分别统计出男、女明星的最高搜索指数。
5、编写 run 方法执行 MapReduce 任务。
MapReduce Java 项目
设计的MapReduce如下所示:
Map = {key = gender, value = name+hotIndex}
Reduce = {key = name, value = gender+hotIndex}
Map
每次调用map(LongWritable key, Text value, Context context)解析一行数据。每行数据存储在value参数值中。然后根据'\t'分隔符,解析出明星姓名,性别和搜索指数。
public static class ActorMapper extends Mapper< Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//value=name+gender+hotIndex
String[] tokens = value.toString().split("\t");
String gender = tokens[1].trim();//性别
String nameHotIndex = tokens[0] + "\t" + tokens[2];//名称和搜索指数
context.write(new Text(gender), new Text(nameHotIndex));
}
}map()函数期望的输出结果Map = {key = gender, value = name+hotIndex}
Combiner
对 map 端的输出结果,先进行一次合并,减少数据的网络输出。
public static class ActorCombiner extends Reducer< Text, Text, Text, Text> {
private Text text = new Text();
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
int hotIndex = 0;
String name="";
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[1]);
if(hotIndex>maxHotIndex){
name = valTokens[0];
maxHotIndex = hotIndex;
}
}
text.set(name+"\t"+maxHotIndex);
context.write(key, text);
}
}Partitioner
根据明星性别对数据进行分区,将 Mapper 的输出结果均匀分布在 reduce 上。
public static class ActorPartitioner extends Partitioner< Text, Text> {
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
String sex = key.toString();
if(numReduceTasks==0)
return 0;
//性别为male 选择分区0
if(sex.equals("male"))
return 0;
//性别为female 选择分区1
if(sex.equals("female"))
return 1 % numReduceTasks;
//其他性别 选择分区2
else
return 2 % numReduceTasks;
}
}Reduce
调用reduce(key, Iterable< Text> values, context)方法来处理每个key和values的集合。我们在values集合中,计算出明星的最大搜索指数。
public static class ActorReducer extends Reducer< Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable< Text> values, Context context) throws IOException, InterruptedException {
int maxHotIndex = Integer.MIN_VALUE;
String name = " ";
int hotIndex = 0;
for (Text val : values) {
String[] valTokens = val.toString().split("\\t");
hotIndex = Integer.parseInt(valTokens[1]);
if (hotIndex > maxHotIndex) {
name = valTokens[0];
maxHotIndex = hotIndex;
}
}
context.write(new Text(name), new Text( key + "\t"+ maxHotIndex));
}
}
reduce()函数期望的输出结果Reduce = {key = name, value = gender+max(hotIndex)}
Run 驱动方法
在 run 方法中,设置任务执行各种信息。
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取配置文件
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "star");//新建一个任务
job.setJarByClass(Star.class);//主类
job.setNumReduceTasks(2);//reduce的个数设置为2
job.setPartitionerClass(ActorPartitioner.class);//设置Partitioner类
job.setMapperClass(ActorMapper.class);//Mapper
job.setMapOutputKeyClass(Text.class);//map 输出key类型
job.setMapOutputValueClass(Text.class);//map 输出value类型
job.setCombinerClass(ActorCombiner.class);//设置Combiner类
job.setReducerClass(ActorReducer.class);//Reducer
job.setOutputKeyClass(Text.class);//输出结果 key类型
job.setOutputValueClass(Text.class);//输出结果 value类型
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.waitForCompletion(true);//提交任务
return 0;
}编译和执行 MapReduce作业
1、myclipse将项目编译和打包为star.jar,使用SSH将 star.jar上传至hadoop的$HADOOP_HOME目录下。
2、使用cd $HADOOP_HOME切换到当前目录,通过命令行执行Hadoop作业
hadoop jar star.jar zimo.hadoop.Star.Star运行结果
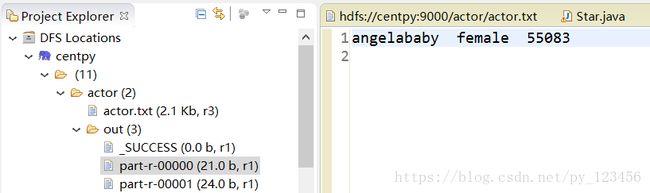
你可以在DFS Locations界面下查看输出目录。

以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。