Python 数据形态及IO操作 !
收集正确的数据是我们完成数据分析的前提.
1.数据型态
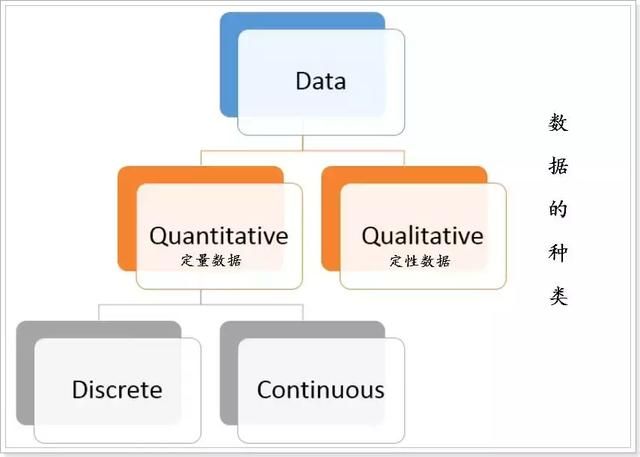
- 定性数据(Qualitative or Categorical Data):是一组表示事物性质、规定事物类别的文字表述型数据,不能将其量化,只能将其定性。
- 叙述特性或种类
- 定量数据(Quantitative or Numerical Data):可以被计数或测量。
- 定性分析与定量分析应该是统一的,相互补充的;定性分析是定量分析的基本前提,没有定性的定量是一种盲目的、毫无价值的定量;定量分析使定性分析更加科学、准确,它可以促使定性分析得出广泛而深入的结论。
- 定量分析是依据统计数据,建立数学模型,并用数学模型计算出分析对象的各项指标及其数值的一种方法。定性分析则是主要凭分析者的直觉、经验,凭分析对象过去和现在的延续状况及最新的信息资料,对分析对象的性质、特点、发展变化规律作出判断的一种方法。
- 相比而言,前一种方法更加科学,但需要较高深的数学知识,而后一种方法虽然较为粗糙,但在数据资料不够充分或分析者数学基础较为薄弱时比较适用,更适合于一般的投资者与经济工作者。但是必须指出,两种分析方法对数学知识的要求虽然有高有低,但并不能就此把定性分析与定量分析截然划分开来。事实上,现代定性分析方法同样要采用数学工具进行计算,而定量分析则必须建立在定性预测基础上,二者相辅相成,定性是定量的依据,定量是定性的具体化,二者结合起来灵活运用才能取得最佳效果。
- 不同的分析方法各有其不同的特点与性能,但是都具有一个共同之处,即它们一般都是通过比较对照来分析问题和说明问题的。正是通过对各种指标的比较或不同时期同一指标的对照才反映出数量的多少、质量的优劣、效率的高低、消耗的大小、发展速度的快慢等等,才能作为鉴别、下判断提供确凿有据的信息。
举个例子:
◆ 定性分析:
分析: _ 知几写了很多篇文章
◆ 定量分析:
分析:_ 知几写了107篇文章。
我的理解是定量分析主要关注的是频率;定性分析关注的是意义。 Python学习交流群:1004391443
定量数据又可分为:
- 离散数据(Discrete Data):指其数值只能用自然数或整数单位计算,例如企业的人数
- 只能用自然数或整数单位计算
- 只能按计量单位数计数,可由一般计数方法取得
- 连续数据(Continuous Data):在一定区间内可以任意取值的数据,其数值是连续不断的,例如人的身高
- 一定区间内可以任意取值的数据,其数值是连续不断的,相邻两个数值可取无限个数值
- 其数值只能用测量或计量的方法获得
2.结构化vs半结构化vs非结构化数据
- 结构化数据
- 每笔数据都有固定的字段、固定的格式,方便程序进行后续取用与分析
- 例如数据库
- 半结构化数据
- 数据介于数据化结构与非结构化数据之间
- 数据具有字段,也可以依据字段来进行查找,使用方便,但每笔数据的字段可能不一致
- 例如:XML,JSON
- 非结构化数据
- 没有固定的格式,必须整理以后才能存取
- 没有格式的文字、网页数据
1.结构化数据
- 结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
- 对数据的处理和捞取可以通过SQL语句。
2.半结构化数据 - XML
xsl boy 23 xlm girl
- 可以使用字段存储数据内容
- 字段不固定,例如xlm就少了age字段
- 可以弹性的存放各种字段格式的数据
3.半结构化数据 - JSON
[
user:{
name:xsl,
gender:boy,
age:12,
},
user:{
name:xsl,
gender:girl,
}
]
- 如同XML可以使用字段存储数据内容
- 使用Key:Value存放数据
- 不用宣告字段的结尾,可以比XML更快更有效传输数据
4.非结构化数据
- 没有固定的数据格式
- 例如网站数据
- 必须透过ETL(Extract,Transformation,Loading)工具将数据转换为结构化数据才能取用
广告Python 3网络爬虫开发实战
作者:崔庆才
京东
由于我们常见的数据是非结构化数据,为了进行数据分析,我们就需要从非结构化数据中挖掘数据,我们就需要先把非结构化数据转换成结构化数据,此时我们就可以使用ETL工具。

数据抽取、转换、存储过程
3.Python IO与档案处理
Python提供了默认操作文件所必需的基本功能和方法。可以使用文件对象执行大部分文件操作。
打开文件
在读取或写入文件之前,需要使用Python的内置open()函数打开文件。此函数创建一个文件对象,该对象将用于调用与其相关联的其他支持方法。
语法:
f = open(file_name [, access_mode][, buffering])
- file_name参数是一个字符串值,指定要访问的文件的名称。
- access_mode确定文件打开的模式,即读取,写入,追加等。可能的值的完整列表如下表所示。这是一个可选参数,默认文件访问模式为(r - 也就是只读)。
- bufferin如果buffering值设置为0,则不会发生缓冲。如果缓冲值buffering为1,则在访问文件时执行行缓冲。如果将缓冲值buffering指定为大于1的整数,则使用指定的缓冲区大小执行缓冲操作。如果为负,则缓冲区大小为系统默认值(默认行为)。
编号模式描述1r打开的文件为只读模式。文件指针位于文件的开头,这是默认模式。2rb打开仅用二进制格式读取的文件。文件指针位于文件的开头,这是默认模式。3r+打开读写文件。文件指针放在文件的开头。4rb+以二进制格式打开一个用于读写文件。文件指针放在文件的开头。5w打开仅供写入的文件。如果文件存在,则覆盖该文件。如果文件不存在,则创建一个新文件进行写入。6wb打开仅用二进制格式写入的文件。如果文件存在,则覆盖该文件。如果文件不存在,则创建一个新文件进行写入。7w+打开写入和取读的文件。如果文件存在,则覆盖现有文件。如果文件不存在,创建一个新文件进行阅读和写入。8wb+打开一个二进制格式的写入和读取文件。如果文件存在,则覆盖现有文件。如果文件不存在,创建一个新文件进行阅读和写入。9a打开一个文件进行追加。如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,它将创建一个新文件进行写入。10ab打开一个二进制格式的文件。如果文件存在,则文件指针位于文件末尾。也就是说,文件处于追加模式。如果文件不存在,它将创建一个新文件进行写入。11a+打开一个文件,用于追加和阅读。如果文件存在,则文件指针位于文件末尾。文件以附加模式打开。如果文件不存在,它将创建一个新文件进行阅读和写入。12ab+打开一个二进制格式的附加和读取文件。如果文件存在,则文件指针位于文件末尾。文件以附加模式打开。如果文件不存在,它将创建一个新文件进行读取和写入。
- write()方法:将任何字符串写入打开的文件。重要的是要注意,Python字符串可以是二进制数据,而不仅仅是文本。
- close()方法:刷新任何未写入的信息并关闭文件对象,之后不能再进行写入操作。
f =open('zj.txt', 'w') #读写模式
f.write('hello xlm') #写入 hello xlm
f.close() 关闭文件
#用with写
with open('zj.txt', 'r') as f:
print(f.read()) #全部读取
with open('zj.txt', 'r') as f:
for line in f.readlines():
print(line) #分行打印出来
print(line.strip()) #去除多余的换行
