协同过滤itembase计算Spark实现(三)
针对电商推荐系统之推荐算法模块工程化,博主前期已经利用spark对基于协同过滤推荐算法进行了实践性的整理,详情见
协同过滤itembase增量计算Spark实现(一)
协同过滤itembase计算Spark实现(二)
随着系统工程化的逐步完善,便会开始考虑如何将系统产品化,面向算法研究人员,测试人员,产品人员甚至其他有推荐算法需求的人员能够通过拖拖拽拽自定义算法实现。这个愿景很美好也很伟大~~
借着美好的愿景,博主便开始了征程,下面介绍基于产品化设计的推荐算法模块代码设计,希望能给各位提供一定的帮助。
代码结构图
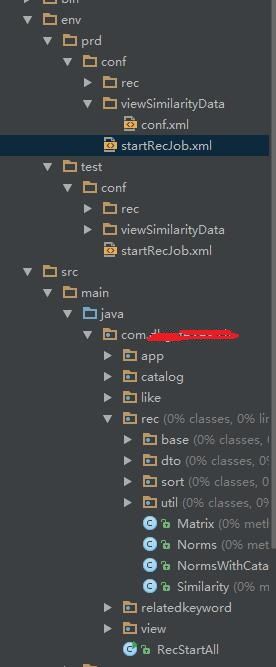
env 主要推荐模块的一些配置信息和数据查看配置信息及算法启动任务三个部分
可以根据开发环境的需要设置prd,pre,dev,sit等配置信息,通过maven实现管理
rec 核心算法模块,建议大伙最好不要直接使用sparkMLlib中算法,情况允许的前提下自己实现一遍算法过程,以保证算法中间过程的可控性。目前此模块只有协同过滤算法,后续可以在此模块下新增其他算法,已增加算法丰富度。
app spark运行的base method
RecStartAll 算法启动接口配置文件
- startRecJob.xml
<config>
<job>
<jobName>catalogjobName>
<filePath>conf/rec/catalog.xmlfilePath>
<classPath>com.ant.search.catalog.CatalogRecclassPath>
job>
config>classpath是catalog模块算法的执行类路径
2.catalog.xml
<conf>
<sparkMaster>spark://ant:7077sparkMaster>
<sparkPath>sparkPath> <sparkConf>spark.executor.memory,12G;spark.executor.cores,1;spark.cores.max,12sparkConf>
<inPutFilePath> view,hdfs://ant:8020/user/search/crosspromotion/browseprefer/;
product,hdfs://ant:8020/user/search/rec-dataload/output/product/csv/;
collect,hdfs://ant:8020/user/search/rec-dataload/output/td_favorite_product/csv/;
historybuy,hdfs://ant:8020/user/search/fse-dataload/output/historyorder/csv/;
shoppingcar,hdfs://ant:8020/user/search/rec-dataload/output/td_shoppingcart_miniorder/csv/
inPutFilePath> <outPutFilePath>hdfs://fse1:8020/fse2/mlrecsearch/itemlike/shard1/inputoutPutFilePath>
conf>算法模块的输入数据,输出地址,spark运行系统参数等,后续也可以自定义选择运行何种推荐算法
3.view.xml
<config>
<conf>
<sparkMaster>spark://ant:7077sparkMaster>
<sparkJarsPath>sparkJarsPath> <sparkConf>spark.executor.memory,12G;spark.executor.cores,1;spark.cores.max,6sparkConf>
<similarityInputPath>算法输出文件地址similarityInputPath>
<showCount>100showCount>
<tableName>自定义表名tableName>
<selectSql>自定义查询sqlselectSql>
conf>
config>demo是通过配置文件的形式实现算法的配置及算法数据查询,既然可以配置了,那一切都不是问题,仅仅是怎样去配置的问题。
启动类
List jobs = XmlReadUtil.getStartJobMes("conf/startRecJob.xml");
for (JobDTO jobDTO : jobs) {
try {
Class cla = Class.forName(jobDTO.getClassPath());
cla.getMethod("startJob", String.class, String.class).invoke(cla.newInstance(),
new Object[]{jobDTO.getJobName(), jobDTO.getFilePath()});
} catch (Exception e) {
e.printStackTrace();
}
} 不许骂我土,通过反射实现
算法模块启动类
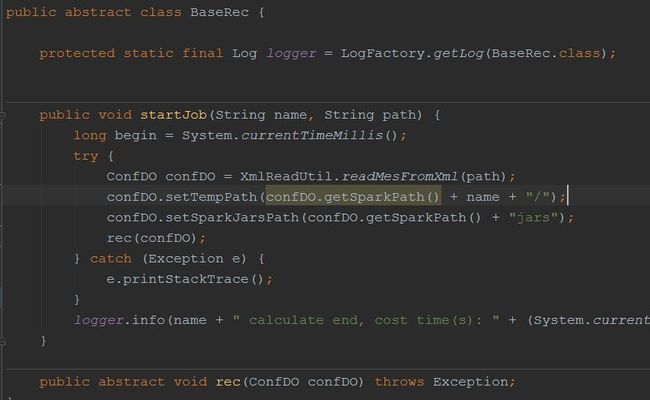
比如spark设置系统参数等通用步骤都在里。

这里只要实现输入,输出即可。设想可以提供一个可视化页面让用户可以自定义输入数据路径,通过拖拖拽拽选择spark RDD方法已达到自定dataclean,dataresult的实现过程。完美~这部分是个关键节点。
感兴趣的朋友们可以集合协同过滤itembase增量计算Spark实现(一),协同过滤itembase计算Spark实现(二)一起细读,已期完成推荐算法可以配置的过程化产品,方便推荐算法的普及及人行门槛。
初步就称其为蚂蚁计划吧!各种诡异的笑,持续三十秒~~
PS:最近博主收到了一份offer,处在换工作的纠结之中,可能更新博客速度不能太及时,抱歉。