游戏研发与运营环境Docker化
在泛娱乐时代,游戏行业特殊的业务特点为技术团队提出了更高的要求,而Docker对游戏研发的运营环境带来了很多好处。发展至今,游戏研发的行业现状是怎么样的?Docker和架构改进之间如何应用?通过Docker构建起来的容器平台,能否提高资源利用率?如何镜像分发技术标准化、统一化应用部署流程?
以下为正文:
行业现状
开发语言方面我主要想讲的是后端程序语言。中国游戏兴起大致于2002~ 03年,在那个时候开始做服务器游戏,即有网络的游戏,当时大部分使用C++。到后来一直到现在,开发语言有C++、Java、C#、Python、php,这些语言虽然都可以支持游戏后端,但应用场景不一样。
目前的互联网大型游戏,例如征途这类需要支持一两百万人同时在线的游戏,开发语言基本上都是C++,而页面游戏则偏向于更轻量级的服务器,一般仅需要支持一两千人同时在线,有不少人用Java与C#语言来开发。在国外,Python语言是用来做服务器架构的,但在国内它一般是被当成脚本做服务器。PHP语言是这两年手游兴起后,互联网游戏中使用得比较多,但大多数是通过http协议或邮件协议通信。从这些年游戏行业的发展来看,不能确定Go语言是否肯定可以替代Java,但很大概率会替代C++,这也可能是游戏后端未来发展的方向。
当前后端开发脚本语言主要有两种:Lua和JS。在大型游戏中,Lua语言用得多, 后来JS语言也逐渐变多。而NodeJS是一种后端服务器开发框架语言,但更适合做相对轻量级的游戏。
后端的开发编译环境越来越多,大约有一半是在Windows下开发的。然而百分之七八十开发后的后端程序运行环境都是在linux中,中青宝的后端程序就是这样。

如图1所示,这是一个传统的服务器,是网络游戏后端架构的服务器拓扑图。图上所示的是一个游戏区,一个游戏区是什么概念?它可能是由一组分步式的服务器组成,一组服务器可能包括:网关,DB,逻辑服等。一般情况下,网关是可分布的,即横向扩展,用来实现网络的负载均衡。以前开发征途游戏时,这样一个区的架构部署,一般需要用16台宿主主机来部署。这样一套区的架构可支持四万多人同时在线。06、07年时,机器配置比较低,对开发人员和运维人员的技能要求比较高,加上C++语言的特点、并发、锁同步、异常等问题很容易造成服务器宕机,所以之前架构及语言的技术门槛是比较高的。但这在当年算作非常好的一套架构,这套架构的思想对于后来大型网络游戏的发展有很重要的意义,甚至影响了后来互联网的发展。例如腾讯做大型游戏时也借鉴了这套架构,通过和他们交流才知道这对他们的影响也是巨大的。
在开发版本控制上, 2006年之前基本上是使用CVS管理,2006年之后换成SVN,在2012年、2013年又换成了git。开发流程一般是程序加代码,放在服务器上,由QA进行服务器代码测试,测试完成之后再做Release版本。开发网和运营网是严格隔离的,中间会有一个跳转机(跳转机对安全性的要求非常高),再通过运维部署到生产机上,以前的开发流程上对人和每个环节的要求都很高,特别是对测试,QA出版本与运维。因为很多测试和运维并不是研发人员,但安装软件都需要正版,还需要安装各种插件,这对他们的要求变得很高,由于经常出现开发环境和生产环境的不同,而导致出现了莫名其妙的问题。开发人员在开发过程当中,不能直接上生产机(游戏行业是不允许开发人员上生产机改动数据的),所以查bug非常难,做到最后才发现很多bug是因为环境不一样导致的。一个开发人员不能上机器,还需要猜测bug出现在哪,这其实很艰辛。所以描述现状之后,需要考虑docker后带来的好处。
架构改进
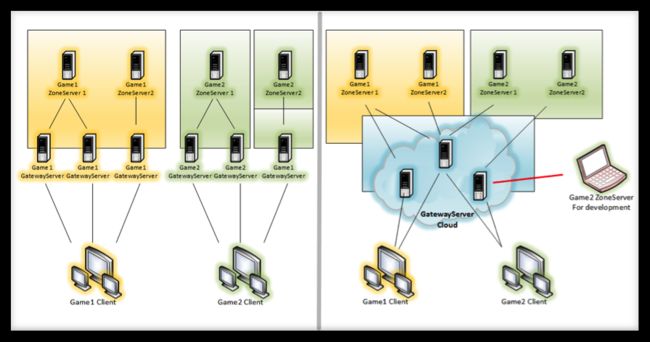
如图2所示的架构,理念上的改进比实际的改进要更多一些,我从2002年开始关注docker和Go语言。因为对老游戏的架构非常了解,所以我在架构改进思路的基础上,想通过docker和云化,让运维和测试变得更方便、安全、简单。一个是docker化,另一个是云化,即网络部分能拿出来,放在云服务上,但真正能给游戏公司做云服务的门槛都会稍高一些。相对来说游戏公司的人才也不缺乏,所以他们自己能管理好自己的机器。
还有一个更重要的原因,当年的那一些服务器架构,不适合用云服务器来管理。如果运行一两千人的游戏无所谓,但如果是同时在线几万人的大区模式,这对机器的要求就会很高。当时的架构,很难适应现在的云服务公司所能提供的这些流程。所以我们都是朝这个方向来做改进的。一个是docker化,一个是云化的游戏架构。
我们以前是一个游戏和网关,它们之间是绑定的。如果一区需要三个网关,这三个网关只能给一区服务。因为里面有很多分不开的逻辑,但这会导致一个很大的问题:如果想跑到云服务器上,它们之间的逻辑交互性太强,操作会比较难,利用率也不高。例如一组会配六个物理机,它的峰值能达四万人,但是实际上峰值四万人是开始的几天,之后并没有那么大的量。甚至每个游戏的峰值,可能因为活动的不一样,一区是八点,二区是九点。其实,为了承受住峰值很多硬件是超配的。
我们认为首先能云化的是网关。新的改进思路,就是把跟网络相关的部分全部拿出来,它和游戏本身无关,只是替用户和游戏之间转发数据而已,并不需要跟某一个区域绑定。区和区之间可以同时共享网关,玩家和服务器之间、客户端程序和游戏服务器之间,都不再有网络这一部分。这样就有一个很大的优势:对于开发人员的知识范畴降低了。因为做网络游戏开发有很大一部分都是在处理网络,网络要高效。从流量安全等角度,这部分的复杂度是很高的。
从业务逻辑看,由于现在大部分都在用脚本做,所以门槛没有网络层高。把网关相关的提出来,在游戏开发的过程当中,对于个人的使用能力降低,对于程序员的门槛降低,安全性提高。网关相关工作可能需要最核心的人做,我认为这方面需要有一些保密的要求。更重要的是现在网络相关的部分,已经可以独立拿出来放在云服务公司。例如今天一区搞活动,可能有四万人的峰值,我们用的六台网关。明天二区搞活动,一区不搞活动,同样用这个网关,这大幅度的提高了硬件的利用率,这个就是我们现在的改进思路。

这是一个更详细的描述(如图3所示),我们把网络相关的部分(网关)和登录部分云化。还有一种构思,把游戏相关的业务及存储不再放在云服务上,甚至放在公司的机房里,它会更加独立。客户端和服务器之间的通信,就是游戏和网关之间的通信,那么逻辑服务器甚至可以不在一个物理机房,因为它本身可以用自己的PC机来充当。
Docker化
在开发一个客户端程序的时候,它可以一边写客户端代码,一边用自己的客户端机器(不管是windows还是mac机) 靠docker构建起一个自己的测试服务器,而这个测试服务器可以通过互联网的网关去运行。实际上,整个测试和研发的过程中,几乎不需要投入多余的硬件,也不需要客户端做任何的调试,让服务器程序来配合,这样这些过程都可以简化。
这个对于现在来说或许有点复杂,对此我们做了一个很详细的规划,包括每一部分做什么。就整体来说,这一部分我们会放在ADC或者是交付云服务公司来支持,让各种逻辑服务器、聊天服务器、DB服务器等自行管理,由此看来,这一套架构是更加轻量级的架构。它的逻辑就是:一块是客户端,网关登陆等被放在云服务器上,而另一块逻辑相关的部分可以被游戏公司自由的支配。
docker化有两个方向,一个是把研发环境docker化,一个是把运营生产环境docker化。docker化的第一个目的就是降低研发期的硬件投入。一般来说,一个处于研发期的团队会配给三十个人。按照五个前端五个后端来考虑,每人需要配一台服务器做开发,做开发还要给QA搭建测试机,给策划搭建自己的测试机,所有人加起来至少需要要二十台左右的机器。做征途时,单是研发环节的硬件成本就要两百多万。研发期对于CPU的要求不高,但要满足它各式各样的环境就需要有大量的硬件投入。如果用现有的架构,对于后端开发来说,几乎不需要投入硬件,因为流程docker化了。比如客户端程序或一个策划,如果你需要测试搭建一个区,三十个研发人员会搭建三十个区。但你有windows就可以装虚拟机,就能跑docker,继而就可以跑后端程序,所有的流程就会变成这样。第二从降低研发投入来讲,docker也很有优势。我刚到中青宝的时候这里有两百多台研发机器,但现在只剩下七十多台。实际上研发业务并没有减,只是停掉了一百多台机器。可见环境的随意搭建和调试,对于游戏开发是很重要的。
做demo之前,很多人都想在基础环境、流程上运行,一旦游戏从demo出来,从开始到正式的做游戏阶段,想要上线和公测,这个过程的时间非常长。主要原因是策划QA程序,包括美术,也要看自己的效果,也需要有自己的测试环境,整个环节耗费的成本很大。现在通过服务器架构改进,再加上docker,从环境随意搭建的角度来讲,门槛非常低。中青宝刚有一批大学生入职,大概有二十个程序,他们基本上第一周就可以把自己的游戏区跑起来,这个在之前是超乎想象的。按照现在的这个流程,中青宝的这批大学生成长会很快。我们把可能需要的资源全部准备妥当,比如要在哪里下载什么东西,全部不需要他们操心,因为我们专门有人维护docker。对于这些大学生,他们就可以直接冲着策划和需求去做,一周内就能熟悉开发环境。因为在整个的大框架下,他们一开始用lua去做就不会闯太多的祸,这个跟以前的思路相比有了比较大的变化。统一研发配置,这个我为什么强调。写过代码的人知道,每个人写代码有自己的习惯,有的人喜欢弄成两个空格而有的人弄成四个。这个对于公司来讲确实很纠结,但就个人习惯而言没有谁对谁错,只要统一就行。因为编辑环境都在docker下控制,docker是被我们控制,所以做到统一很简单。中青宝现有的平台服务器,都被docker标准化部署。这些都是依靠docker把环境配置成统一的标准,让谁都没有争议。
第三,运维人员的培训成本低,这是一个非常关键的因素。我们在做征途的研发时,很多的流程不能固化,接触不到运维的生产机,所以我们不得不教运维人员怎么做,虽然到最后运维人员都变得会写程序,但是这个培训的代价很大,而且一轮培训下来真正成长起来的只有四五个人。这也会有一些其他的麻烦,比如我对运营环境不了解,运营环境一变我们就不会解决了,最后变成一个深坑。现在流程都被docker之后,运维人员几乎变成了一个“搬砖”的人。因为docker,整个研发环境和生产环境,全部由研发人员配置,运维只需要把它拉到生产机上跑起来。因为运维本身是在互联网上工作的,对于公司的安全性有好处。我们之前一步一步教他们,很多东西需要去调试,因此他们掌握了公司很多的核心理念,但在有技术壁垒的公司,运维其实是一个很危险的岗位,因为他们是在内网跟外网之间工作。
第四,提高硬件资源利用率。做运维的都很清楚,做游戏时总会有一些机器闲着,其实可以把两个机器合在一起,这样能给公司省一台机器。但由于工作太繁琐而没人愿意去做。但现在这些资源对于运维来讲,只是一两个指令而已。现在对于运维人员的考核很简单,比如一台网关能跑五千人,如果这台网关没有到五千人,不管你有多少个游戏,第二个网关物理机都不会给你,因为他可以随意的配置;但如果达到了五千人,我们就认为这个机器有点忙,就会给你新配机器。运维之前压力大是因为合服这些东西很麻烦。以前可以找好的运维,比如花两万请一个很牛的运维,但是我们一个月网关费用只省了五百,这样并不划算。但是现在不一样,现在可以用三千块的人把这个硬件省下来。所以运维不是一个绝对的,很多东西都是需要权衡性价比的。什么叫性价比?举个很简单的例子,以前征途服务器是有内存泄露的,查了很久都没查出来。请过很高端的人去查,比如我就主要把精力花在了查运维泄露上,跟运维讨论下来也确实没有办法。但后来发现,如果加一个两千块的内存,至少够泄露两周的内存,那就随它泄露吧。加一个两千块的内存比一天的薪资还低,相比之下这种性价比很高,这个就叫做利用率。
提到这个概念,程序员会想到它的内存效率,好象这样它的逻辑并不严密。但放到真正的生产环境,你在乎的是这个人的薪资高,还是买个硬件更划算?现在的利用率就是通过用docker这个门槛来衡量的。
第五,应对市场弹性空间大。中青宝前段时间测试,他们预测同时会来五万人,需要两百多个机器。但实际上,能同时拉来两百台PC的压力很大,虽然可能只会有两万人,但是我们不得不准备五万人的机器。万一来了怎么办?如果提前给运维一天时间,他可以把运维环境准备好,但如果五点钟开服,六点钟发现机器不够,运维必然来不及,但是现在基本上来得及。因为毕竟游戏公司有很多款游戏,硬件足够,但没有闲置的。像我们这种环境如果五点钟开服,发现当时人数很多怎么办?可以立即换机房换机器,用docker一个小时之内再部署,不用像以前需要提前预备。我觉得这个留给市场的活动空间更大,不需要做太多前期和预测性的投入。

图4是一个游戏部署装环境,以前每个人需要装完所有环境,每个人的工作环境都一样。每来一个新人,不管这个新人能力如何,首先配上一台机器和一个环境。有些新人还需要有能力的人帮他配,基本上每次都会花大量的时间。但现在整个环境只配一个,不需要专门给新人配环境。

如图5所示,这是现在工作环境的布置,专门有一个人负责维护docker,这种环境下我会跟这个人紧密互动,因为我要把需求都告诉他,控制每个游戏的节奏。他自己负责配置,然后其他人都可以通过docker进行部署。整个过程只需要关注制作镜像的过程,剩下的生产配置部分会放出权限给其他人做。这样做在调试过程当中有很多的优势,不会因为环境不一样而浪费时间。重要的docker化,一方面是降低开发流程的成本和运维,另一方面是把它运维化。目前网关这类东西是可以用云服务来支撑的,而且中青宝现在也有这样一套架构,在实际生产中能投入使用。
本文是中青宝CTO王海军日前在「七牛云主办的架构师实践日——容器核心技术与最佳实践」的演讲内容整理。PPT、速记和现场演讲视频等参见“七牛架构师实践日”官网。
七牛架构师实践日是由七牛云发起的线下技术沙龙活动,联合业内资深技术大牛以及各大巨头公司和创业品牌的优秀架构师,致力于为业内开发者、架构师和决策者提供最前沿、最有深度的技术交流平台,帮助大家知悉技术动态,学习经验成果。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
编辑推荐:架构技术实践系列文章(部分):
- 游戏研发与运营环境Docker化
- 当当网高可用架构之道
- 黄哲铿:应对电商大促峰值的九个方法
- 1号店交易系统架构如何向「高并发高可用」演进
- 从C10K到C10M高性能网络的探索与实践
- 服务化架构的演进与实践
- 1号店架构师王富平:一号店用户画像系统实践
- 唯品会官华:实现电商平台从业务到架构的治理体系
- 沈剑:58同城数据库架构最佳实践
- 荔枝FM架构师刘耀华:异地多活IDC机房架构
- UPYUN的云CDN技术架构演进之路
- 初页CTO丁乐:分布式以后还能敏捷吗?
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构