Hadoop集群环境搭建详细步骤
Hadoop集群环境搭建详细步骤
1、三台机器,配置hosts,并确保java环境jdk1.7.0_72
192.168.5.231 ubuntu231
192.168.5.232 ubuntu232
192.168.5.233 ubuntu233
2、ubuntu231选择作为主节点Master
下载hadoop-2.6.0安装包
二、解压
解压安装包到指定路径
这里的全路径是 /home/spark
三、ssh免密配置
$ ssh-keygen -t rsa
$ ssh-copy-id -i ~/.ssh/id_rsa.pub 要免密码的机器的IP
四、环境变量配置
spark@ubuntu231:~$ vi .profile
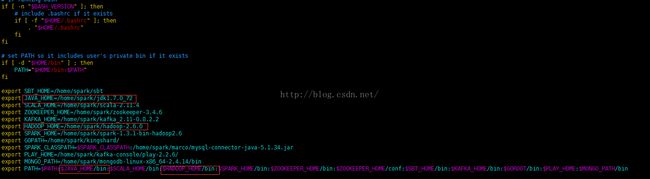
五、配置hadoop
在配置之前先在本地文件系统创建以下文件夹~/hadoop2.6.0/tmp、~/hadoop2.6.0/dfs/data、~/hadoop2.6.0/dfs/name
主要配置在hadoop-2.6.0/etc/hadoop目录下的七个文件
hadoop-env.sh
yarn-env.sh
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
1、配置 hadoop-env.sh文件-->修改JAVA_HOME
export JAVA_HOME=/home/spark/jdk1.7.0_72
2、配置 yarn-env.sh 文件-->>修改JAVA_HOME
export JAVA_HOME=/home/spark/jdk1.7.0_72
3、配置slaves文件-->>增加slave节点
ubuntu232
ubuntu233
4、配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/home/spark/hadoop-2.6.0/tmp)
5、配置 hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
6、配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
7、配置 yarn-site.xml 文件-->>增加yarn功能
六、将配置好的hadoop文件copy到另外两台slave机器上(请保持目录一致)
scp -r hadoop-2.6.0/ [email protected]:~/
scp -r hadoop-2.6.0/ [email protected]:~/
七、格式化namenode
spark@ubuntu231:~$ cd hadoop-2.6.0/
spark@ubuntu231:~/hadoop-2.6.0$ ./bin/hdfs namenode -format
spark@ubuntu232:~$ cd hadoop-2.6.0/
spark@ubuntu232:~/hadoop-2.6.0$ ./bin/hdfs namenode -format
spark@ubuntu233:~$ cd hadoop-2.6.0/
spark@ubuntu233:~/hadoop-2.6.0$ ./bin/hdfs namenode -format
到此我们的hadoop已经配置完成了