【YOLO】使用VOC数据集训练自己的YOLOv3模型(Keras/TensorFlow)
文章目录
- 0. 前期准备(因人而异)
- 1. 试验官方模型
- 1.1 下载工程文件
- 1.2 转换权重文件
- 1.3 图片识别
- 2. 制作VOC数据集
- 2.1 格式介绍
- 2.2 准备样本及XML标记
- 2.3 生成索引
- 3. YOLO模型训练
- 3.1 生成训练索引
- 3.2 修改配置文件
- 3.3 执行训练
- 4. 模型验证
- 5. 常见问题
- 5.1 如何提高检测效果
- 5.2 Found 0 boxes for img
- 5.3 loss值异常
参考:
https://blog.csdn.net/patrick_Lxc/article/details/80615433
https://blog.csdn.net/m0_37857151/article/details/81330699
0. 前期准备(因人而异)
记录一下前期的一些配置:
首先要安装好python,博主这里用的是Python 3.6 64-bit。
path环境变量中加入python36和python36/Scripts的路径。
使用管理员权限进入cmd命令提示符,运行一下代码:
pip install --upgrade pip #更新pip
pip install tensorflow #安装 tensorflow
pip install --upgrade numpy #numpy是一个基础的数组计算包,有时候版本较老会报错
pip install keras #yolo train.py文件里面要用到keras这个高层神经网络API
pip install pillow #安装 图片处理模块PIL(pillow)
pip install matplotlib #安装 2D绘图库matplotlib
pip install opencv-python #安装 opencv视觉库
中间记得测试一下tensorflow安装有没有问题:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
hello = tf.constant('Hello,TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
如果打算用 GPU版本 训练的话,可以参考我另外一篇文章:https://blog.csdn.net/qinchang1/article/details/90693983
1. 试验官方模型
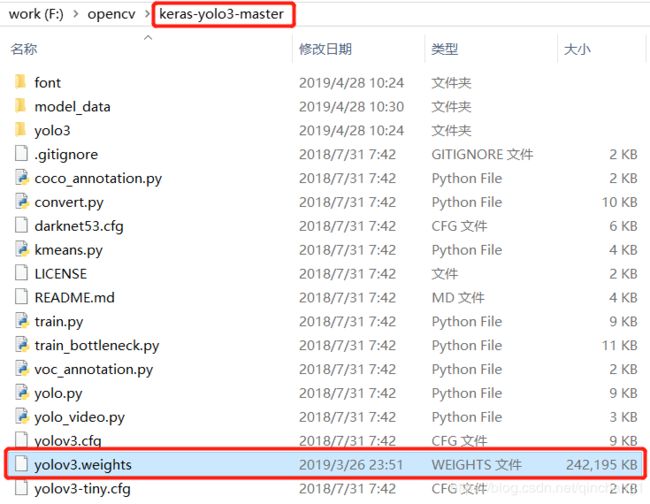
1.1 下载工程文件
YOLOv3下载:
1)yolov3.weights权重文件:https://pjreddie.com/media/files/yolov3.weights
2)keras-yolo3代码: https://github.com/qqwweee/keras-yolo3 (工程文件如下,记得把 .weights权重文件也放进去)
推荐:百度网盘打包下载(* ̄︶ ̄):链接:https://pan.baidu.com/s/1OIQGthndfLSfMC1ZlZH6lA 提取码:rlkd
(建议用我的网盘资源下载,因为github上面的工程文件可能会有更改,导致后续的操作出现不同或问题)
1.2 转换权重文件
这里首先要需要将 DarkNet 的.weights文件转换成 Keras 的.h5文件,在cmd中打开工程文件的路径,运行convert.py并告知 “.weights的输入路径 ” 和 “.h5的输出路径” ,代码如下:
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
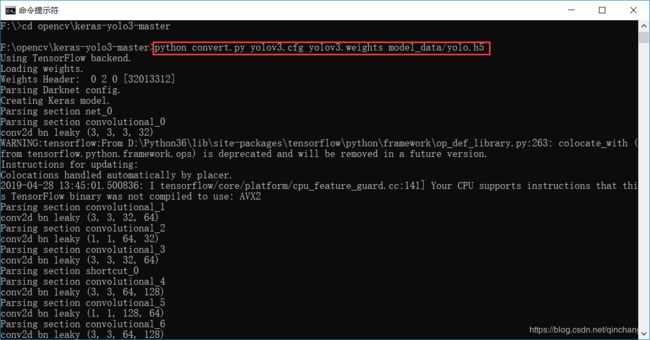
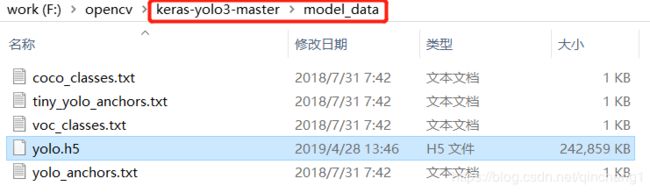
会在model_data文件夹中生成一个yolo.h5文件。
+注意:这个权重文件要留着,后面可能会用上。
1.3 图片识别
在工程文件中打开yolo_video.py,其用法如下:
usage: yolo_video.py [-h] [–model MODEL] [–anchors ANCHORS]
[–classes CLASSES] [–gpu_num GPU_NUM] [–image]
[–input] [–output]
positional arguments:
–input Video input path
–output Video output path
optional arguments:
-h, --help show this help message and exit
–model MODEL path to model weight file, default model_data/yolo.h5
–anchors ANCHORS path to anchor definitions, default
model_data/yolo_anchors.txt
–classes CLASSES path to class definitions, default
model_data/coco_classes.txt
–gpu_num GPU_NUM Number of GPU to use, default 1
–image Image detection mode, will ignore all positional arguments
例如:识别一张图片,则在cmd中的工程文件路径下输入:
python yolo_video.py --image
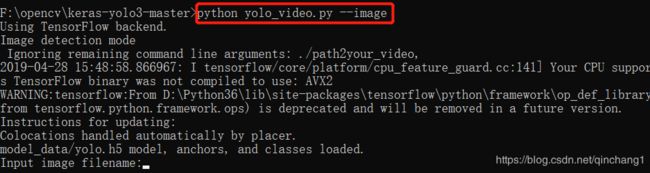
会提示你输入图片路径(这里我的图片是直接放在工程文件里面的,所以直接输入文件名):
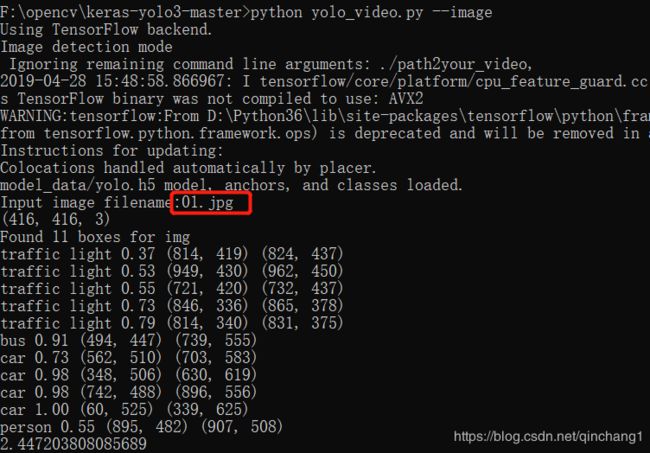
效果如下:
2. 制作VOC数据集
VOC全称Visual Object Classes,出自The PASCAL Visual Object Classes(VOC)Challenge,这个挑战赛从2005年开始到2012年,每年主办方都会提供一些图片样本供挑战者识别分类。
PASCAL VOC官网:http://host.robots.ox.ac.uk/pascal/VOC/
2.1 格式介绍
可以在官网中下载每一年的数据集,也可以自己仿照VOC的格式制作。
其文件格式如下图:
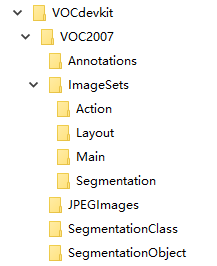
下面是本人对每个文件功能的总结和理解:

我们可以把官方下载的VOC数据集里面的内容删除,只保留各个文件夹;或者按照这个格式建立一个文件夹集。
这个文件夹我们直接放到前面的工程文件keras-yolo3-master中(以便之后的训练不用更改路径)。
2.2 准备样本及XML标记
在JPEGImage文件夹中放入准备好的样本图片:
需要制作每张图片对应的同名xml文件,这里我们以下面这张图片为例,右边的代码是其对应的xml文件内容:

如果你有精力的话,当然可以自己一个个去写:)
不过这里我们用一个labelImg的软件进行标记,
labelImg下载链接:https://pan.baidu.com/s/1Ibenx26FaJUI_t-J3EhSLw 提取码:2gba
解压之后就两个文件,labelImg.exe运行文件,data文件夹里面有个predefined_classes.txt文件。

在predefined_classes.txt文件里面添加需要标记的类的名称。
打开软件,其实操作很简单,就是手动去标注物体,并给其选择对应的类名称:
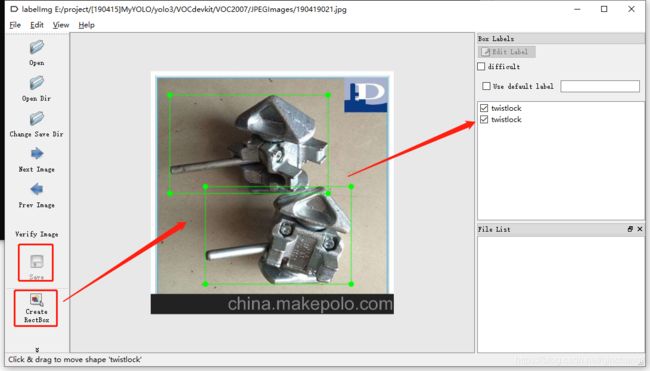
之后保存xml文件,注意路径。
把所有xml文件都放置到VOC数据集里面的Annotations文件夹中。
2.3 生成索引
在VOC2007文件夹中新建一个**.py文件**(名字随意)
在py文件中输入以下代码并运行,用以生成索引
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
之后就会在ImageSets\Main文件夹中生成几个索引文件
{class}_train.txt 保存类别为 class 的训练集的所有索引
{class}_val.txt 保存类别为 class 的验证集的所有索引
{class}_trainval.txt 保存类别为 class 的训练验证集的所有索引
3. YOLO模型训练
3.1 生成训练索引
在工程文件keras-yolo3-master中,修改voc_annotation.py文件
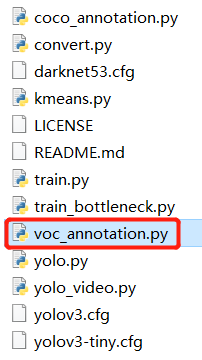
主要是把里面classes的内容改成要训练的对象(要和前面标记的一致,这里我只有一个对象"twistlock")
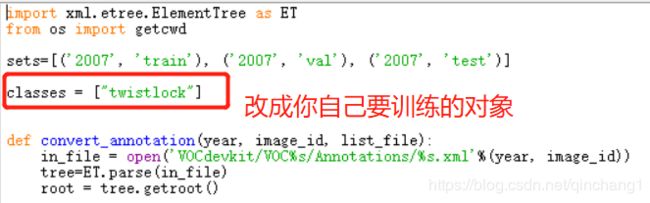
运行这个py程序,生成三个文件"2007_test.txt", “2007_train.txt”, “2007_val.txt”,把前缀"2007_"去掉,得到 “test.txt”, “train.txt”, “val.txt”(建议复制新的副本更改)。
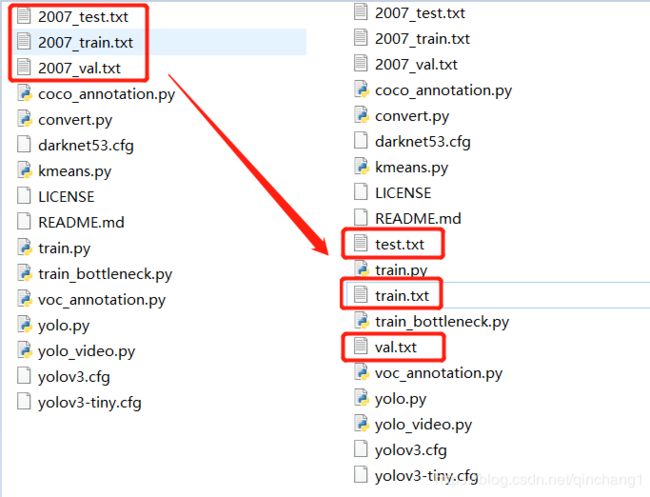
3.2 修改配置文件
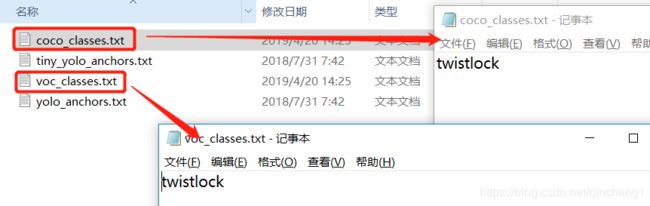
首先要修改一下 model_data 文件夹中的coco_classes.txt和voc_classes.txt,将里面的对象改成自己要训练的对象名称
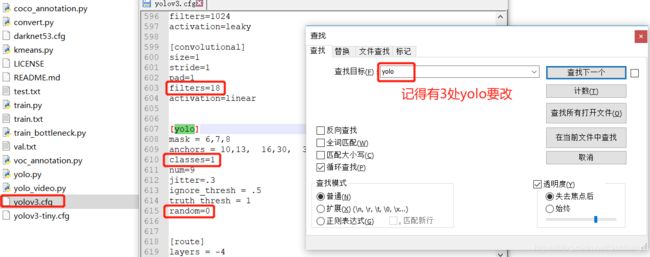
打开yolov3.cfg,在里面查找 yolo(注意有3处),需要修改的地方也有3处:
1.filters = 3 * ( 5 + classes) (这是最后一层卷积层核参数个数)
2.classes = 1 (这个是你要训练的类的数量)
3.random = 0 (原来是1,显存小改为0,关闭多尺度训练,有博客说打开的话会精确一些)
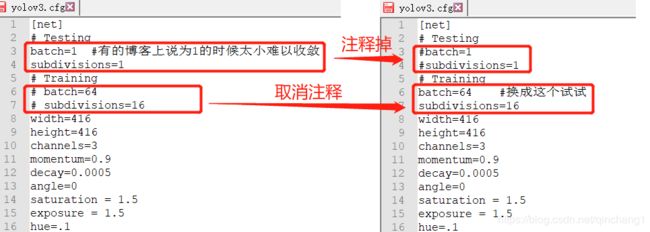
其实也有博客说这个batch和subdivisions要改,换成下面注释掉的几个。
batch:一批训练样本的样本数量,每batch个样本更新一次参数
subdivisions:batch/subdivision作为一次性送入训练器的样本数量
配置文件中参数说明(仅供参考):


3.3 执行训练
文章开头提供的参考博客中修改了train. py文件进行训练,具体的代码修改可以参考原博客,修改内容主要是去除了预载入官方权重。但是,我实际训练效果不佳,得到的模型识别效果很差,多数情况都是0 box,就算有,置信度也很低。
所以,最后我是使用GitHub上原作者的 原版train. py 进行训练的。(这里之前有错误,感谢评论区大佬指出)
PS:参考博客中修改了train. py文件使得训练从0开始而不需要预加载权重文件,这种情况下.cfg文件修改是没有必要的。但是这里我改用原版的train. py文件需要预加载权重文件,这里就需要使用 修改后的.cfg文件 来 生成预加载的权重文件。
!!有很多人提到使用修改后的.cfg文件训练会出现val_loss:nan的情况,建议使用参考博客中的方法,修改train.py文件从0开始训练。
同样在cmd中的工程文件路径下输入执行以下代码:
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
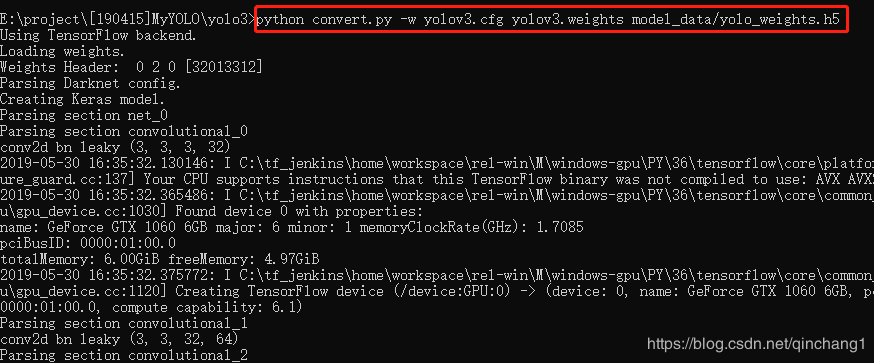
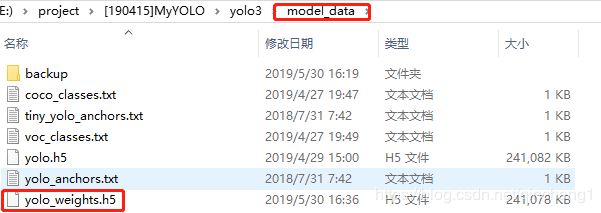
之后就会在model_data文件夹中生成一个yolo_weights.h5文件,这就是之后训练中需要预加载的权重文件。
之后在keras-yolo3-master工程文件夹中找到train. py,根据需要,可以更改里面的迭代次数epochs 等参数
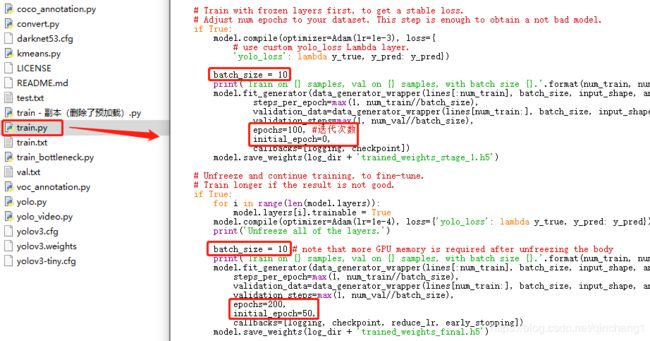
之后运行这个python程序,下面是我的运行效果(不过不太清楚为什么有那么多警告,望大佬赐教)
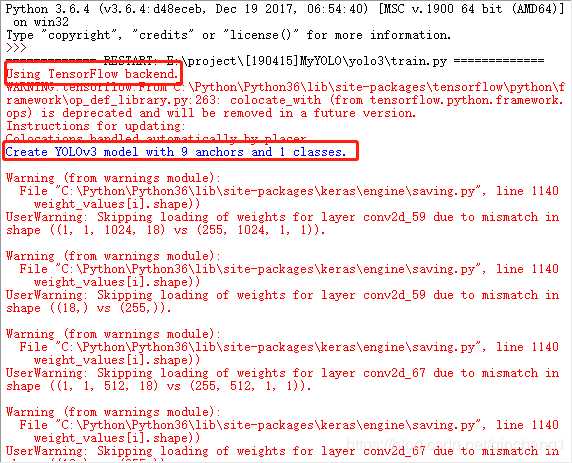
训练过程:

训练结束后,会生成很多过程的h5文件,最后只需要保留trained_weights_final.h5就行。
本次测试仅为初步试验,1个对象,40个样本图片,100次迭代,最后loss值为18.9。
4. 模型验证
参照前面1.3节内容,可以在yolo. py 中把权重文件的名字改成 trained_weights_final.h5 ,也可以直接把 trained_weights_final.h5名字改成 yolo. h5,总之就是之后要加载新的权重文件。
同样地,则在cmd中的工程文件路径下输入:
python yolo_video.py --image
输入图片路径(这里是将图片直接放在工程文件里,所以直接输入名字就行)
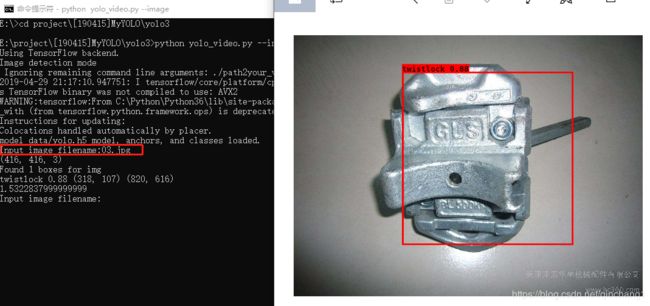
单独的扭锁识别效果还行

但是一旦多了乱了之后识别效果就不是特别好。(原因我分析主要是训练样本里面的对象都是在图片中占比较大的,就是整个图片就是一个扭锁,这样检测多个小扭锁时效果就不会很好)

待我之后多准备一些样本,多更改一些参数,多做些训练,寻找到规律再回来更新一下。
5. 常见问题
5.1 如何提高检测效果
参考:https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
1. 训练前
(1)在.cfg文件中设置flag random=1,它将通过不同分辨率来训练yolo以提高精度。
(2)提高.cfg文件中网络的分辨率,(例如height = 608,width = 608或者任意32的倍数),这样可以提高精度。
(3)确保数据集中每个类都带有标签,并且保证标签正确。(原文里面提供一个脚本工具)
(4)对于要检测的每个对象,训练数据集中必须至少有一个类似的对象,其形状、对象侧面、相对大小、旋转角度、倾斜、照明等条件大致相同。
(5)数据集中应包括对象的不同缩放、旋转、照明、不同的面、不同背景的图像,最好为每个类提供2000个不同的图像,并且训练(2000* 类的数量)的迭代次数或更多。
(6)确保训练的数据集中包含不想被检测的不带标签的对象,即负样本,负样本的数量最好和正样本的数量相同。
(7)对于目标物体较多的图像,在.cfg文件中最后一个[yolo]层和[region]层加入max=200参数或者更高的值。(yolov3可以检测到的对象的全局最大数目是0.0615234375 *(width*height),其中width和height是.cfg文件中[net]部分的参数)
(8)训练小物体时(图像调整到416x416后物体小于16x16),将[route]参数替换为layers = -1, 11,将[upsample]参数改为stride =4。
(9)对于都包含小对象和大对象可以使用以下的修改模型:
Full-model: 5 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg
Tiny-model: 3 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny_3l.cfg
Spatial-full-model: 3 yolo layers: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-spp.cfg
(10)如果要训练区分左右的对象(例如左手右手,道路上左转右转标志等),需要禁用数据翻转增强,在.cfg文件中17行左右的位置加入flip=0。
(11)一般规律——训练数据集应该包含一组您想要检测的对象的相对大小。简单来说,就是需要检测的对象在图像中的百分比是多少,那么训练的图像中也应该包含这个百分比的对象。例如:如果训练的时候目标在图像中都占80-90%,那检测的时候很可能就检测不出目标占0-10%情况。
(12)同一个对象在不同的光照条件、侧面、尺寸、倾斜或旋转30度的情况下,对于神经网络的内部来说,都是不同的对象。因此,如果想检测更多的不同对象,就应该选择更复杂的神经网络。
(13)在.cfg中重新计算锚(anchors)的width和height:在.cfg文件中的3个[yolo]层中的每个层中设置相同的9个锚,但是应该为每个[yolo]层更改锚点masks=的索引,以便[yolo]第一层的锚点大于60x60,第二层大于30x30,第三层剩余。此外,还应在每个[yolo]层之前更改过滤器filters=(classes + 5) * 。如果许多计算出的锚找不到适当的层,那么只需尝试使用所有的默认锚。
2.训练后(对于检测):
通过在.cfg文件中设置(height=608,width=608)或(height=832,width=832)或(32的任意值倍数)来提高网络的分辨率,这将提高精度并使检测小对象成为可能。
这里提高了网络的分辨率,但是可以不需要重新训练(即使之前使用416*416分辨率训练的)。但是为了提高精度,还是建议使用更高的分辨率来重新训练。
注意:如果出现了Out of memory的错误,建议提高.cfg文件中的subdivisions=16参数,改成32或者64等。
5.2 Found 0 boxes for img
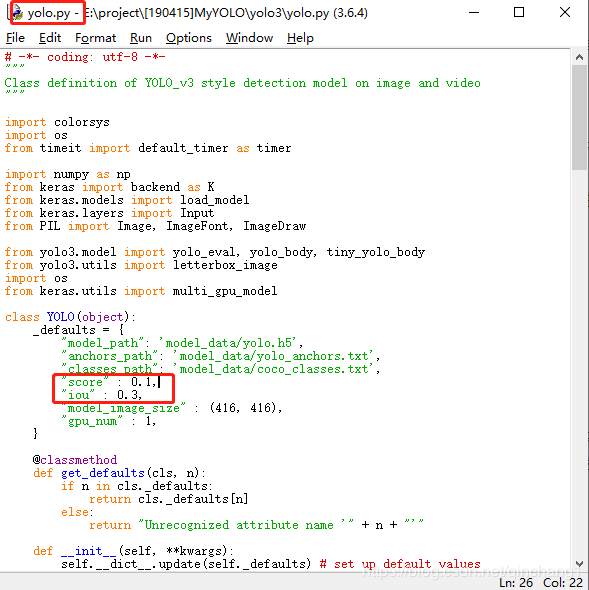
在检测时,减小 yolo. py 文件参数中的 score 和 iou,如下图:
(这样可以使得置信度小和交并比小的框也能显示出来)
如果这时候能出现框了,但是会发现效果不是很好,或者说置信度特别低,说明检测是成功的,但是训练做得比较差;
如果还是不能出现框,考虑有可能检测方法错了(路径设置等),或者是训练过程错误(类名称和索引没配置好等)。
不管什么情况都可以试试5.1节中提到的方法。
5.3 loss值异常
模型训练时,有两个loss值:
1)Train loss(对应本次训练中的loss):使用训练集的样本来计算的损失;
2)Test loss(对应本次训练中的val_loss):使用验证集的样本来计算的损失。
一般来说,损失函数越小,模型就越好。但要考虑过拟合情况:
过拟合:为了得到一致假设而使假设变得过度严格。
例如:训练出来的模型对训练样本检测的效果很好,但是对于验证集(也就是没有进行训练的样本)的检测效果却很差。
结果分析:( ↓ 表示 不断下降,↑ 表示 不断增加,→ 表示 趋于不变)
| train loss | test loss | 说明 |
|---|---|---|
| ↓ | ↓ | 网络正在不断学习收敛 |
| ↓ | → | 网络过拟合 |
| → | ↓ | 数据集有问题 |
| → | → | 此次条件下学习达到瓶颈 |
| ↑ | ↑ | 网络结构或设计参数有问题,无法收敛 |
如有错误,欢迎指正!