scrapy爬取豆瓣所有电影信息(新手入门超详细版)
本次小实验目标就是爬取豆瓣所有的电影,我们以豆瓣的分类页(https://movie.douban.com/tag/#/)作为start_urls,首要任务就是分析当前页面是否为动态加载,何为js动态加载页面可以百度一下~这里推荐一个小chrome插件—Toggle JavaScript插件,这个插件的功能就是方便地开启和关闭chrome的javascript功能。使用也很方便,点一下关闭,再点一下开启,对我们的起始豆瓣分类页关闭JavaScript功能后,分类及电影等都没有加载,可知本页为动态加载,那么问题来了,如何进行JS动态加载页面的抓取呢?
首先,动态加载的页面,一般数据会在Network的JS或者 XHR 类目里。如下图:
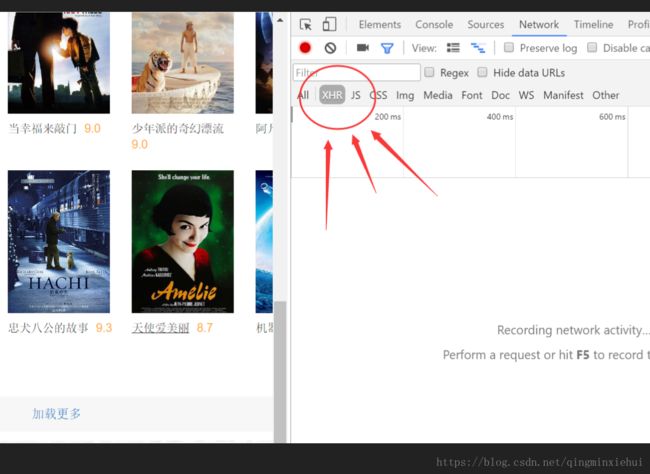
此时这个类目是空的,点击加载更多,看此时给我们返回什么信息, 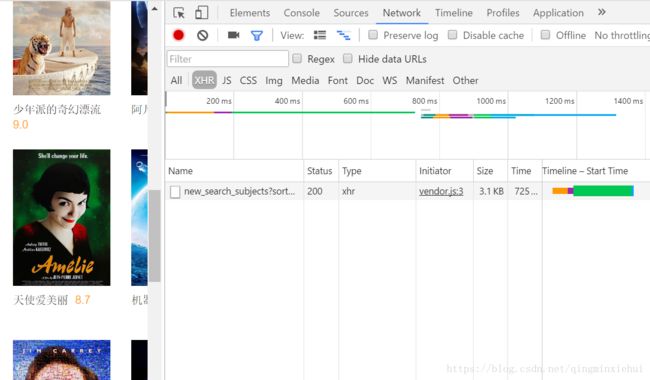
将链接在新窗口打开,返回的是一个json页面, 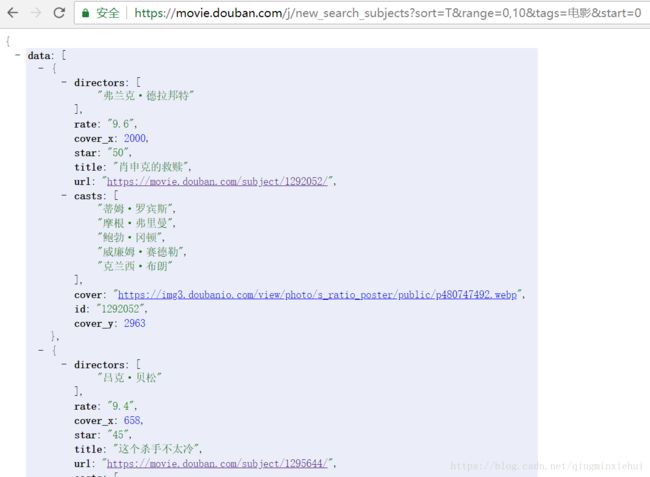
如果你的页面是杂乱无章的,同样给你推荐一个好用的chrome插件--JSONView,安装后你会打开新世界的大门。
同样的方式多打开几个页面,观察链接规律:
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=20
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=40
这时你发现规律了吗?没加载一页url变化的只有最后的start数值,因此如果我们抓取电影分类,翻页循环链接就可以这样写:
for a in range(25): # range(a)当中a为向下翻页的数量
url = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=电影&start={}'.format(a*20)确定了待抓取的页面链接,下面就开始正式的scrapy抓取工作啦,scrapy是一个python实现的网络爬虫框架,使用异步的方式来实现并发。具体的架构大家可以自行百度一下,本文只介绍详细操作。命令行下进入创建项目的文件夹,输入:
scrapy startproject EPG_proj新建scrapy项目之后主要进行操作的几个文件是:
①item.py:这个文件主要用来定义网络爬虫需要采集的字段。本次实验我们尽可能采集更多的字段,部分代码如下:
import scrapy
class EpgprojItem(scrapy.Item):
# define the fields for your item here like:
# movie_name = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 节目形式
program_form = scrapy.Field()
# 短评链接
shortComment_link = scrapy.Field()
# 影评链接
filmReview_link = scrapy.Field()
# 图片链接
image_link = scrapy.Field()
# 电影人员链接
movieStaff_link = scrapy.Field()
# 豆瓣评分
movie_rating = scrapy.Field()
# 评分人数
movie_NumRatingPeople = scrapy.Field()
# 链接地址
movie_linkAddress = scrapy.Field()
# 电影导演
movie_director = scrapy.Field()
# 电影编剧
movie_screenwriter = scrapy.Field()
# 电影主演
movie_starring = scrapy.Field()
# 电影类型
movie_type = scrapy.Field()
# 制片国家/地区
movie_productionCountry = scrapy.Field()
②EPGSpider.py:此文件是整个爬虫的主体部分,页面的url获取和解析获取数据都在此文件当中。
首先先介绍一下豆瓣的在之前是反爬虫,豆瓣之前很少有反爬虫措施,不过现在也开始在逐步的进行反爬虫的操作。针对豆瓣的反爬虫,我们主要进行了如下的一些处理:
a、单位时间内的点击次数,这个是很多网站都会有的反爬虫措施,豆瓣网站的每分钟点击次数具体数值不太清楚,但实际操作应该是每台机器每分钟不超过40次,我们选择每点击一次页面,就暂停3秒来防止被封。在settings.py文件中设置访问延时。
DOWNLOAD_DELAY = 1.5b、UA设置,即用户代理user_agent,关于这个的设置网上有很多,但本实验采用的是如下这种方式:
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()c、cookie的设置,有些网站会根据访问的cookie判断是否为机器人,除非特殊要求,我们都禁用cookie,在settings.py做如下设置:
COOKIES_ENABLED = Falsed、IP代理,这是应对反爬虫的大招,可是免费的代理速度太慢,优质的代理收费又太高,所以个人推荐最好的方式就是ADSL重拨,关于这个内容会在之后的博客详细介绍,目的就是通过ADSL的重拨使IP发生变化,穷人的IP池。
e、设置随机请求头。
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection': 'keep-alive',
'Referer': 'https://accounts.douban.com/',
'Host': 'movie.douban.com',
'User-Agent': f.user_agent()
}以上是关于反爬虫的一些措施,对于一些页面,比如影评信息等需要登陆之后才可以大批量抓取,本着完善程序的想法,我们也做了豆瓣的模拟登陆。详细代码如下:
def parse_before_login(self, response):
print("登录前表单填充")
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
captcha_image_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
if captcha_image_url is None:
print(u"登录时无验证码")
formdata = {
"redir": "https://movie.douban.com/",
"source": "movie",
"form_email": "你的账号",
# 请填写你的密码
"form_password": "你的密码",
}
print(u"登录中")
# 提交表单
return scrapy.FormRequest.from_response(response, meta={"cookiejar": response.meta["cookiejar"]}, headers=self.headers, formdata=formdata, callback=self.parse_after_login)
else:
print("登录时有验证码")
save_image_path = "D:/image/captcha.jpeg"
# 将图片验证码下载到本地
urllib.urlretrieve(captcha_image_url, save_image_path)
# 打开图片,以便我们识别图中验证码
try:
im = Image.open('captcha.jpeg')
im.show()
except:
pass
# 手动输入验证码
captcha_solution = raw_input('根据打开的图片输入验证码:')
formdata = {
"source": "None",
"redir": "https://www.douban.com",
"form_email": "你的账号",
# 此处请填写密码
"form_password": "你的密码",
"captcha-solution": captcha_solution,
"captcha-id": captcha_id,
"login": "登录",
}
print("登录中")
# 提交表单
return scrapy.FormRequest.from_response(response, meta={"cookiejar": response.meta["cookiejar"]},
headers=self.headers, formdata=formdata,
callback=self.parse_after_login)此处的难点在于登陆时有时会有验证码,我们的方案时将验证码存到本地,然后进行加载,手工输入验证码。再之后的内容就是XPATH的获取了,这里也推荐一个极好用的浏览器插件叫XPath Helper,具体用法可自行百度。详细代码存在百度云盘,大家可下载参考,也欢迎提出宝贵建议。
百度网盘链接:https://pan.baidu.com/s/1xXCC-s3KpC3jxJ8a2qd0pQ 密码:o4up
3、pipelines.py:这个文件主要是用来对爬取的数据进行进一步的处理,本次实验我们将爬取的数据存储到mongoDB数据库当中,具体代码如下:
class EpgprojPipeline(object):
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbName = settings['MONGODB_DBNAME']
client = pymongo.MongoClient()
tdb = client[dbName]
self.post = tdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
movieInfo = dict(item)
self.post.insert(movieInfo)
return item
后记:以上就是整个小实验的执行过程,中间难免还有一些有待优化的内容,有一些细节问题也不太清晰,后续的博客会详细探讨,也欢迎大家好的建议。