DCGAN论文及代码学习
文章目录
- DCGAN
- DCGAN代码
- 数据集
- 代码结构
- 模型 model.py
- tf中的函数封装 ops.py
- 图片处理等功能性函数封装 utils.py
- 主函数 main.py
- 代码运行结果
参考文章: https://blog.csdn.net/stalbo/article/details/79359095
DCGAN论文地址: https://arxiv.org/pdf/1511.06434.pdf
我的代码是根据此项目修改学习的: https://github.com/carpedm20/DCGAN-tensorflow
我自己的项目地址是: https://github.com/qinpengzhi/myDCGAN
DCGAN
在读DCGAN(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)之前,我首先读的文章是GAN(Generative Adversarial Nets)
在以往的尝试中,将CNN应用于GAN,都没有获得成功。但是经过一系列探索,我们找到一类结构,可以在分辨率更高、更深的生成模型上稳定地训练。而本篇文章的方法是基于对CNN的以下改进:
- 全卷积网络(all convolutional net):用步幅卷积(strided convolutions)替代确定性空间池化函数(deterministic spatial pooling functions)(比如最大池化)。允许网络学习自身 upsampling/downsampling方式(生成器G/判别器D)。在网络中,所有的pooling层使用步幅卷积(strided convolutions)(判别网络)和微步幅度卷积(fractional-strided convolutions)(生成网络)进行替换
- 在卷积特征之上消除全连接层:例如:全局平均池化(global average pooling),曾被应用于图像分类任务(Mordvintsev et al.)中。global average pooling虽然可以提高模型的稳定性,但是降低了收敛速度。图1所示为模型的框架。
- 批量归一化(Batch Normalization):将每个单元的输入都标准化为0均值与单位方差。这样有助于解决poor initialization问题并帮助梯度流向更深的网络。防止G把所有rand input都折叠到一个点。但是,将所有层都进行Batch Normalization,会导致样本震荡和模型不稳定,因此,生成器(G)的输出层和辨别器(D)的输入层不采用Batch Normalization
- 激活函数:在生成器(G)中,输出层使用Tanh函数,其余层采用 ReLu 函数 ; 判别器(D)中都采用leaky rectified activation
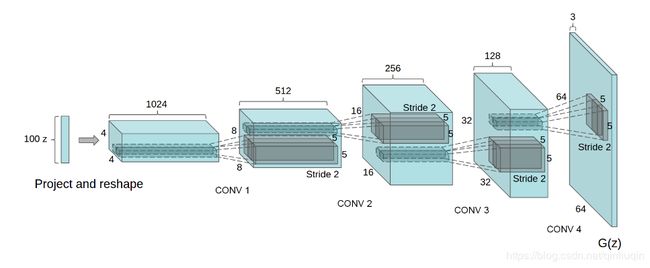 上图是论文中的生成模型对于LSUN scene数据集的结构,在下面实验的对于celebA人脸数据集中对应的是512到64,而不是1024到128
上图是论文中的生成模型对于LSUN scene数据集的结构,在下面实验的对于celebA人脸数据集中对应的是512到64,而不是1024到128
DCGAN代码
数据集
我用到的是CalebA人脸数据集(官网链接)是香港中文大学的开放数据,包含10,177个名人身份的202,599张人脸图片,并且都做好了特征标记,这对人脸相关的训练是非常好用的数据集。可以通过官网的百度云进行下载。其中img文件夹有三个文件,“img_align_celeba.zip”是jpg格式的,比较小,1G多,我采用的是这个文件,直接解压即可。其他文件夹的含义和标注可以网上搜索查阅。
代码结构

其中checkpoint是生成的模型保存的地方;logs是tensorboard --logdir logs来通过浏览器可视化一些训练过程;而samples是每训练100次patch后,验证generator输出的图片的保存文件夹;main是函数主入口,通过flags保存一系列参数;model是这个DCGAN的生成对抗性模型,而ops封装了一些model中调用的tensorflow的函数,方便调用,比如线性,反卷积(deconvolution)批量归一化(batch_norm)等;utils是一些图片处理保存之类的功能性函数
模型 model.py
# -*- coding: utf-8 -*-
import tensorflow as tf
from glob import glob
import numpy as np
import time
import os
from ops import *
from utils import *
class DCGAN(object):
#sample是需要测试的图片数量,batch_size是需要训练的图片数量
def __init__(self,sess,batch_size=64,input_height=108,input_width=108,output_height=64,
output_width=64,sample_num=64):
self.sess = sess
self.batch_size = batch_size
self.input_height = input_height
self.input_width = input_width
self.output_height = output_height
self.output_width = output_width
self.sample_num=sample_num
self.build_model()
def build_model(self):
self.inputs = tf.placeholder(
tf.float32, [self.batch_size, self.output_height, self.output_width, 3], name='real_images')
##生成一个100维的向量,这和论文上的一样
self.z = tf.placeholder(tf.float32, [None, 100], name='z')
self.G = self.generator(self.z)
self.sampler = self.sampler(self.z)
self.D,self.D_logits = self.discriminator(self.inputs,reuse=False)
self.D_,self.D_logits_=self.discriminator(self.G,reuse=True)
self.d_loss_real=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits,labels=tf.ones_like(self.D)))
self.d_loss_fake=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits_,labels=tf.zeros_like(self.D_)))
self.g_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.D_logits_,labels=tf.ones_like(self.D_)))
self.d_loss=self.d_loss_real+self.d_loss_fake
self.z_sum=tf.summary.histogram("z",self.z)
self.d_sum=tf.summary.histogram("d",self.D)
self.d__sum=tf.summary.histogram("d_",self.D_)
self.G_sum=tf.summary.image("G",self.G)
self.d_loss_real_sum=tf.summary.scalar("d_loss_real", self.d_loss_real)
self.d_loss_fake_sum=tf.summary.scalar("d_loss_fake",self.d_loss_fake)
self.d_loss_sum=tf.summary.scalar("d_loss",self.d_loss)
self.g_loss_sum=tf.summary.scalar("g_loss",self.g_loss)
##这一点特别重要,因为在指定训练的时候需要指定要调节的参数
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'd_' in var.name]
self.g_vars = [var for var in t_vars if 'g_' in var.name]
self.saver=tf.train.Saver()
#通过100的向量生成对应的图片,在生成器(G)中,输出层使用Tanh函数,其余层采用 ReLu 函数
def generator(self,z):
with tf.variable_scope("generator") as scope:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = s_h / 2, s_w / 2
s_h4, s_w4 = s_h / 4, s_w / 4
s_h8, s_w8 = s_h / 8, s_w / 8
s_h16, s_w16 = s_h / 16, s_w / 16
h0 = linear(z, 512 * s_h16 * s_w16, 'g_ho_lin')
h0 = tf.reshape(h0, [-1, s_h16, s_w16, 512])
h0 = tf.nn.relu(batch_norm(h0))
h1 = deconv2d(h0, [self.batch_size, s_h8, s_w8, 256], name='g_h1')
h1 = tf.nn.relu(batch_norm(h1))
h2 = deconv2d(h1, [self.batch_size, s_h4, s_w4, 128], name='g_h2')
h2 = tf.nn.relu(batch_norm(h2))
h3 = deconv2d(h2, [self.batch_size, s_h2, s_w2, 64], name='g_h3')
h3 = tf.nn.relu(batch_norm(h3))
h4 = deconv2d(h3, [self.batch_size, s_h, s_w, 3], name='g_h4')
return tf.nn.tanh(h4)
#判别式函 数判别器(D)中都采用leaky rectified activation
def discriminator(self,image,reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
h0 = lrelu(conv2d(image, 64, name='d_h0_conv'))
h1 = lrelu(batch_norm(conv2d(h0, 128, name='d_h1_conv')))
h2 = lrelu(batch_norm(conv2d(h1, 256, name='d_h2_conv')))
h3 = lrelu(batch_norm(conv2d(h2, 512, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [self.batch_size, -1]), 1, 'd_h4_lin')
return tf.nn.sigmoid(h4),h4
#和generator 内容一样,将generator的模型参数重新reuse就可以
def sampler(self,z):
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = s_h / 2, s_w / 2
s_h4, s_w4 = s_h / 4, s_w / 4
s_h8, s_w8 = s_h / 8, s_w / 8
s_h16, s_w16 = s_h / 16, s_w / 16
h0 = linear(z, 512 * s_h16 * s_w16, 'g_ho_lin')
h0 = tf.reshape(h0, [-1, s_h16, s_w16, 512])
h0 = tf.nn.relu(batch_norm(h0))
h1 = deconv2d(h0, [self.batch_size, s_h8, s_w8, 256], name='g_h1')
h1 = tf.nn.relu(batch_norm(h1))
h2 = deconv2d(h1, [self.batch_size, s_h4, s_w4, 128], name='g_h2')
h2 = tf.nn.relu(batch_norm(h2))
h3 = deconv2d(h2, [self.batch_size, s_h2, s_w2, 64], name='g_h3')
h3 = tf.nn.relu(batch_norm(h3))
h4 = deconv2d(h3, [self.batch_size, s_h, s_w, 3], name='g_h4')
return tf.nn.tanh(h4)
#训练函数,在main函数中调用来训练
def train(self,config):
d_optim=tf.train.AdamOptimizer(learning_rate=config.learning_rate,
beta1=config.beta1).minimize(self.d_loss,var_list=self.d_vars)
g_optim=tf.train.AdamOptimizer(learning_rate=config.learning_rate,
beta1=config.beta1).minimize(self.g_loss,var_list=self.g_vars)
tf.global_variables_initializer().run()
self.g_sum=tf.summary.merge([self.z_sum,self.d__sum,self.G_sum,
self.d_loss_fake_sum,self.g_loss_sum])
self.d_sum=tf.summary.merge([self.z_sum,self.d_sum,self.d_loss_real_sum,
self.d_loss_sum])
self.writer=tf.summary.FileWriter("./logs",self.sess.graph)
##弄一批验证集进行验证
sample_z=np.random.uniform(-1,1,size=(self.sample_num,100))
dataTotal = glob(os.path.join(config.data_dir, config.dataset, "*.jpg"))
sample_files=dataTotal[0:self.sample_num]
sample=[get_image(sample_file) for sample_file in sample_files]
sample_inputs=np.array(sample).astype(np.float32)
for epoch in xrange(0,config.epoch):
self.data=glob(os.path.join(config.data_dir,config.dataset,"*.jpg"))
np.random.shuffle(self.data)
##" // "表示整数除法
batch_idxs=len(self.data)/config.batch_size
##每一轮设置计数器
counter=1
start_time=time.time()
could_load, checkpoint_counter = self.load(config.checkpoint_dir)
if could_load:
counter = checkpoint_counter
print(" [*] Load SUCCESS")
else:
print(" [!] Load failed...")
for idx in xrange(0,int(batch_idxs)):
batch_files= self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch=[get_image(batch_file) for batch_file in batch_files]
batch_images = np.array(batch).astype(np.float32)
#从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
batch_z=np.random.uniform(-1,1,[config.batch_size,100]).astype(np.float32)
##update Dicriminator network
## global_step,当前迭代的轮数,需要注意的是,如果没有这个参数,那么scalar的summary将会成为一条直线
_,summary_str=self.sess.run([d_optim,self.d_sum],feed_dict={self.z:batch_z,self.inputs:batch_images})
self.writer.add_summary(summary_str,counter)
##update Generator network
_,summary_str=self.sess.run([g_optim,self.g_sum],feed_dict={self.z:batch_z})
self.writer.add_summary(summary_str,counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_,summary_str= self.sess.run([g_optim,self.g_sum], feed_dict={self.z: batch_z})
self.writer.add_summary(summary_str,counter)
##eval是tensorflow中启动计算的值
errD_fake=self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({self.inputs: batch_images})
errG = self.g_loss.eval({self.z: batch_z})
counter+=1
print("Epoch: [%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (epoch, config.epoch, idx, batch_idxs,
time.time() - start_time, errD_fake + errD_real, errG))
if np.mod(counter,100)==1:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
save_images(sample_inputs, image_manifold_size(sample_inputs.shape[0]),
'./{}/train_{:02d}_{:04d}_1.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
if np.mod(counter,500)==1:
self.save(config.checkpoint_dir,counter)
#保存模型
def save(self,checkpoint_dir,step):
model_name="DCGAN.model"
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess,os.path.join(checkpoint_dir,model_name),global_step=step)
#从checkpoint中获取已经存在的模型
def load(self, checkpoint_dir):
import re
print(" [*] Reading checkpoints...")
checkpoint_dir = os.path.join(checkpoint_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
counter = int(next(re.finditer("(\d+)(?!.*\d)", ckpt_name)).group(0))
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0
tf中的函数封装 ops.py
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.contrib import *
##线性函数
def linear(input,output_size,scope=None,stddev=0.02,bias_start=0.0):
shape= input.get_shape().as_list()
##tf.random_normal_initializer() is the same as tf.RandomNormal()
##tf.constant_initializer() is the same as tf.Constant()
with tf.variable_scope(scope or "Linear"):
matrix=tf.get_variable(
"Matrix",[shape[1],output_size],tf.float32,
tf.random_normal_initializer(stddev=stddev))
bias = tf.get_variable("bias",[output_size],initializer=tf.constant_initializer(bias_start))
##tf.multiply是点乘.tf.matmul是矩阵乘法
return tf.matmul(input,matrix)+bias
##batch_norm
def batch_norm(input,epsilon=1e-5,momentum=0.9,scope=None,train=True):
# is_training:图层是否处于训练模式。在训练模式下,它将积累转入的统计量moving_mean并
# moving_variance使用给定的指数移动平均值
# decay。当它不是在训练模式,那么它将使用的数值moving_mean和moving_variance。
return tf.contrib.layers.batch_norm(
input,decay=momentum, updates_collections=None,
epsilon=epsilon,scale=True,is_training=train)
##deconv2d
def deconv2d(input,output_shape,
k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name="deconv2d"):
with tf.variable_scope(name):
w = tf.get_variable('w',[k_h,k_w,output_shape[-1],input.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
deconv=tf.nn.conv2d_transpose(input,w,output_shape=output_shape,
strides=[1,d_h,d_w,1])
biases=tf.get_variable('biases',[output_shape[-1]],initializer=tf.constant_initializer(0.0))
##tf.nn.bias_add是将偏差项加到value上,是tf.add的一个特例,其中bias必须是一维的
deconv=tf.reshape(tf.nn.bias_add(deconv,biases),deconv.get_shape())
return deconv
##leaky relu。leaky relu 的 α的取值为0.2。
def lrelu(x,leak=0.2,name="lrelu"):
return tf.maximum(x,leak*x)
##conv2d将pool层融合在了stride中
def conv2d(input,output_dim,k_h=5,k_w=5,d_h=2,d_w=2,stddev=0.02,name="conv2d"):
with tf.variable_scope(name):
w=tf.get_variable('w',[k_h,k_w,input.get_shape()[-1],output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv=tf.nn.conv2d(input,w,strides=[1,d_h,d_w,1],padding="SAME")
biases=tf.get_variable('biases',[output_dim],initializer=tf.constant_initializer(0.0))
conv=tf.reshape(tf.nn.bias_add(conv,biases),conv.get_shape())
return conv
图片处理等功能性函数封装 utils.py
# -*- coding: utf-8 -*-
import scipy.misc
import numpy as np
#通过图片地址得到图片,crop默认是true,就是找到图片中心,切割108*108的图片像素
#再将切割的像素进行resize到64
def get_image(image_path, input_height=108, input_width=108,
resize_height=64, resize_width=64,
crop=True, grayscale=False):
image = imread(image_path, grayscale)
return transform(image, input_height, input_width,
resize_height, resize_width, crop)
def imread(path, grayscale = False):
if (grayscale):
return scipy.misc.imread(path, flatten = True).astype(np.float)
else:
return scipy.misc.imread(path).astype(np.float)
def transform(image, input_height, input_width,
resize_height=64, resize_width=64, crop=True):
if crop:
cropped_image = center_crop(
image, input_height, input_width,
resize_height, resize_width)
else:
cropped_image = scipy.misc.imresize(image, [resize_height, resize_width])
return np.array(cropped_image)/127.5 - 1.
def center_crop(x, crop_h, crop_w,
resize_h=64, resize_w=64):
if crop_w is None:
crop_w = crop_h
h, w = x.shape[:2]
j = int(round((h - crop_h)/2.))
i = int(round((w - crop_w)/2.))
return scipy.misc.imresize(
x[j:j+crop_h, i:i+crop_w], [resize_h, resize_w])
def image_manifold_size(num_images):
manifold_h = int(np.floor(np.sqrt(num_images)))
manifold_w = int(np.ceil(np.sqrt(num_images)))
assert manifold_h * manifold_w == num_images
return manifold_h, manifold_w
#将生成的图片进行保存,因为samples是同时生成64张图片,
#因此将生成8*8的格子图片,每个位置保存一张图
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def inverse_transform(images):
return (images+1.)/2.
def imsave(images, size, path):
image = np.squeeze(merge(images, size))
return scipy.misc.imsave(path, image)
def merge(images,size):
h,w=images.shape[1],images.shape[2]
c=images.shape[3]
img = np.zeros((h * size[0], w * size[1], c))
for idx,image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
主函数 main.py
将datadir改成你的celeA图片文件夹的地址,sample_dir改成celeA图片文件夹就可以直接运行,如果input_size和output_size要改,记住将utils中的也改掉
# -*- coding: utf-8 -*-
import tensorflow as tf
import pprint
from model import DCGAN
flags=tf.app.flags
flags.DEFINE_boolean("train", True, "True for training, False for testing [False]")
flags.DEFINE_float("learning_rate",0.0002,"Learning rate of for adam [0.0002]")
flags.DEFINE_float("beta1",0.5,"Momentum term of adam [0.5]")
flags.DEFINE_integer("epoch", 25, "Epoch to train [25]")
flags.DEFINE_integer("batch_size", 64, "The size of batch images [64]")
flags.DEFINE_string("data_dir","/home/qpz/data/gan-data","Root directory of dataset [data]")
flags.DEFINE_string("dataset","celebA","The name of dataset [celebA, mnist, lsun]")
flags.DEFINE_string("checkpoint_dir", "checkpoint", "Directory name to save the checkpoints [checkpoint]")
flags.DEFINE_string("sample_dir", "samples", "Directory name to save the image samples [samples]")
flags.DEFINE_boolean("crop", True, "True for training, False for testing [False]")
FLAGS=flags.FLAGS
def main(_):
pp = pprint.PrettyPrinter()
pp.pprint(flags.FLAGS.__flags)
run_config = tf.ConfigProto()
run_config.gpu_options.allow_growth = True
with tf.Session(config=run_config) as sess:
dcgan=DCGAN(sess)
if FLAGS.train:
dcgan.train(FLAGS)
if __name__ == '__main__':
tf.app.run()
代码运行结果
记住生成的图片类似这种就算成功了

这是我仅仅上传100个patch的结果,我之前训练一直没有人脸形状出现,幻想着也许多训练几轮就有效果,都是不可能的,如果你一开始都没有人脸的样子,那就要考虑是不是代码写错了 PS我刚开始是在tf.train.AdamOptimizer(…).minimize(self.d_loss,var_list=self.d_vars)中没有指定var_list,希望读者也注意,因为G和D网络在backpropagation时候如果不指定需要更新的参数,那会同时将两个网络的参数都进行更新,导致错误。