七大查找算法(附C语言代码实现)
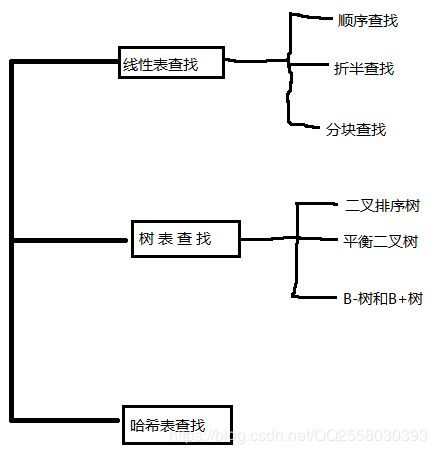

平均查找长度ASL(Average Search Length)定义为:
n是查找表中记录的个数。pi是查找第i个记录的概率,一般地,认为每个记录的查找概率相等,即pi=1/n(1≤i≤n),ci是找到第i个记录所需进行的比较次数。
1. 顺序查找
说明:顺序查找适合于存储结构为顺序存储或链接存储的线性表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
复杂度分析:
- 查找成功时的平均查找长度为:(假设每个数据元素的概率相等) ASL = 1/n(1+2+3+…+n) = (n+1)/2 ;
- 当查找不成功时,需要n+1次比较,时间复杂度为O(n);
- 所以,顺序查找的时间复杂度为O(n)。
C++实现源码:
#include
int FindBySeq(int *ListSeq, int ListLength, int KeyData)
{
int tmp = 0;
int length = ListLength;
for (int i = 0; i < ListLength; i++)
{
if (ListSeq[i] == KeyData)
return i;
}
return 0;
}
int main()
{
int TestData[5] = { 34, 35, 26, 89, 56 };
int retData = FindBySeq(TestData, 5, 89);
printf("retData: %d\n", retData);
return 0;
} 2. 二分查找
说明:元素必须是有序的,如果是无序的则要先进行排序操作。
基本思想:也称为是折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
复杂度分析:最坏情况下,关键词比较次数为log2(n+1),且期望时间复杂度为O(log2n);
注:折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找能得到不错的效率。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。——《大话数据结构》

#include
int binsearch(int *sortedSeq, int seqLength, int keyData)
{
int low = 0, mid, high = seqLength - 1;
while (low <= high) {
mid = (low + high) / 2;//奇数,无论奇偶,有个值就行
if (keyData < sortedSeq[mid]) high = mid - 1;//是mid-1,因为mid已经比较过了
else if (keyData > sortedSeq[mid]) low = mid + 1;
else return mid;
}
return -1;
}
int main()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int location;
int target = 4;
location = binsearch(array, 9, target);
printf("%d\n", location);
return 0;
} 改进方法:——————————————
插值查找
在介绍插值查找之前,首先考虑一个新问题,为什么上述算法一定要是折半,而不是折四分之一或者折更多呢?
打个比方,在英文字典里面查“apple”,你下意识翻开字典是翻前面的书页还是后面的书页呢?如果再让你查“zoo”,你又怎么查?很显然,这里你绝对不会是从中间开始查起,而是有一定目的的往前或往后翻。
同样的,比如要在取值范围1 ~ 10000 之间 100 个元素从小到大均匀分布的数组中查找5, 我们自然会考虑从数组下标较小的开始查找。
经过以上分析,折半查找这种查找方式,不是自适应的(也就是说是傻瓜式的)。二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
通过类比,我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
也就是将上述的比例参数1/2改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
复杂度分析:查找成功或者失败的时间复杂度均为O(log2(log2n))。
int binsearch(int *sortedSeq, int seqLength, int keyData)
{
int low = 0, mid, high = seqLength - 1;
while (low <= high) {
mid = low + (keyData - sortedSeq[low]) / (sortedSeq[high] - sortedSeq[low]) * (high-low);
if (keyData < sortedSeq[mid]) high = mid - 1;//是mid-1,因为mid已经比较过了
else if (keyData > sortedSeq[mid]) low = mid + 1;
else return mid;
}
return -1;
}斐波那契查找
在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念——黄金分割。
黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二,较大部分与较小部分之比等于整体与较大部分之比,其比值约为1:0.618或1.618:1。
0.618被公认为最具有审美意义的比例数字,这个数值的作用不仅仅体现在诸如绘画、雕塑、音乐、建筑等艺术领域,而且在管理、工程设计等方面也有着不可忽视的作用。因此被称为黄金分割。
大家记不记得斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数开始,后边每一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查找技术中。
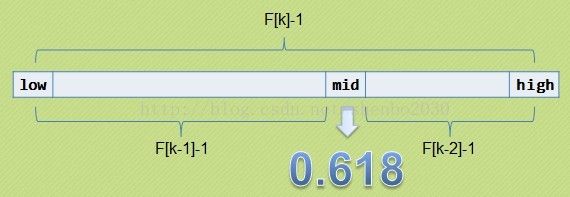
基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
相对于折半查找,一般将待比较的key值与第mid=(low+high)/2位置的元素比较,比较结果分三种情况:
1)相等,mid位置的元素即为所求
2)>,low=mid+1;
3)<,high=mid-1。
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。他要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1;
开始将k值与第F(k-1)位置的记录进行比较(及mid=low+F(k-1)-1),比较结果也分为三种
1)相等,mid位置的元素即为所求
2)>,low=mid+1,k-=2;
说明:low=mid+1说明待查找的元素在[mid+1,high]范围内,k-=2 说明范围[mid+1,high]内的元素个数为n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以可以递归的应用斐波那契查找。
3)<,high=mid-1,k-=1。
说明:low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]内的元素个数为F(k-1)-1个,所以可以递归 的应用斐波那契查找。
复杂度分析:最坏情况下,时间复杂度为O(log2n),且其期望复杂度也为O(log2n)。
#include
#include
#define MAXN 20
/*
*产生斐波那契数列
* */
void Fibonacci(int *f)
{
int i;
f[0] = 1;
f[1] = 1;
for (i = 2; i < MAXN; ++i)
f[i] = f[i - 2] + f[i - 1];
}
/*
* 查找
* */
int Fibonacci_Search(int *a, int key, int n)
{
int i, low = 0, high = n - 1;
int mid = 0;
int k = 0;
int F[MAXN];
Fibonacci(F);
while (n > F[k] - 1) //计算出n在斐波那契中的数列
++k;
for (i = n; i < F[k] - 1; ++i) //把数组补全
a[i] = a[high];
while (low <= high)
{
mid = low + F[k - 1] - 1; //根据斐波那契数列进行黄金分割
if (a[mid] > key)
{
high = mid - 1;
k = k - 1;
}
else if (a[mid] < key)
{
low = mid + 1;
k = k - 2;
}
else
{
if (mid <= high) //如果为真则找到相应的位置
return mid;
else
return -1;
}
}
return 0;
}
int main()
{
int a[MAXN] = { 5, 15, 19, 20, 25, 31, 38, 41, 45, 49, 52, 55, 57 };
int k, res = 0;
printf("请输入要查找的数字:\n");
scanf("%d", &k);
res = Fibonacci_Search(a, k, 13);
if (res != -1)
printf("在数组的第%d个位置找到元素:%d\n", res + 1, k);
else
printf("未在数组中找到元素:%d\n", k);
return 0;
} 3. 分块查找
查找关键字为80的记录

4. 树表查找
常见的树表:
- 二叉排序树
- 平衡二叉树
- B-树
- B+树
4.1 最简单的树表查找算法——二叉树查找算法。
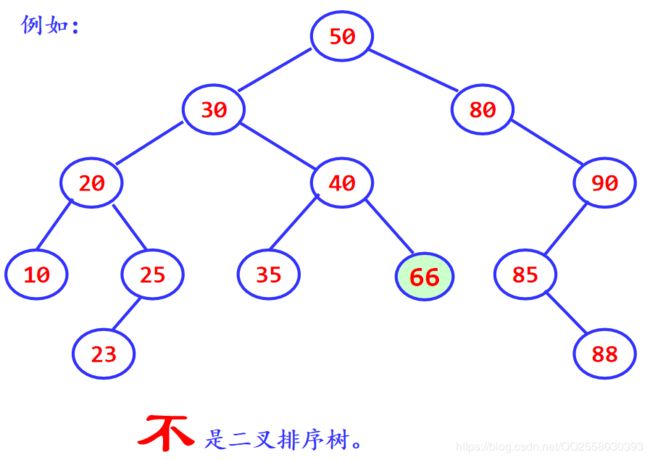
基本思想:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2)若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3)任意节点的左、右子树也分别为二叉查找树。
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。
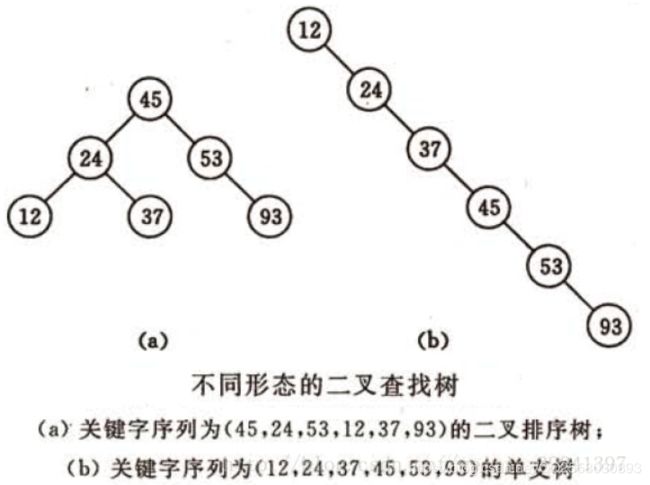
实例代码:
BSTNode *SearchBST(BSTNode *bt,KeyType k)
{
if (bt==NULL || bt->key==k) //递归出口
return bt;
if (kkey)
return SearchBST(bt->lchild,k); //在左子树中递归查找
else
return SearchBST(bt->rchild,k); //在右子树中递归查找
} B-树
参考:B树,B-树,B+和红黑树的区别