Azkaban3.59.x 最新版极简入门
1. Azkaban概述
Azkaban技术产生前景:
在大数据分析场景中,以ETL( Extract抽取 -Transform交互转换 -Load加载 )为例 ,数据的操作包含了如下流程:RDBMS ==>Sqoop ==>Hadoop ==>Sqoop ==>RDBMS/NoSQL/...,这里涉及了三个流程:数据抽取 ==> 数据清洗 ==> 数据入库。
这三个步骤出现了明显的顺序问题。假设数据抽取需要3h,数据清洗需要2h,数据入库需要1h。我们可以使用linux shell提供的crontab 来实现。他的优点是使用简单,缺点却有很多:
1. 流程不便于跟踪和监控(流程某个环境出错没办法监控)。
2. 在这个流程中有些模块执行的时间可能出现延迟/提前。比如数据清洗预测需要2h,结果用了3h,此刻数据入库在前一个任务还没执行完就已经开始执行了;比如清洗预测需要2h,结果用了1h,导致后面的流程出现无效等待的状态。
因此,像Azkaban这样的调度框架在我们数据平台中就扮演着很重要的角色。
大数据中常见的调度框架
大数据中常见的调度框架,最常见的就是crontab。除此之外还有很多集成框架:
- Quartz:Quartz是OpenSymphony[ˈəʊpən ˈsɪmfəni] 开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用。
- Azkaban:Azkaban是由Linkedin公司推出的一个批量工作流任务调度器, 其使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流 。
- Oozie:Oozie是一个工作流引擎服务器,用于运行hadoop map/reduce和hive等任务工作流。同时Oozie还是一个java web程序,运行在java servlet容器中,如tomcat中。Oozie以action为基本单位,可以将多个action构成一个DAG图的模式运行。Oozie工作流通过HPDL(一种通过XML自定义处理的语言)来构造Oozie工作流。
- Zeus:宙斯是阿里巴巴开源的一款分布式Hadoop作业调度平台,实现任务的分布式调度,支持多机器的水平扩展。
Azkaban概述
Azkaban是一个由LinkedIn 创建的用来跑Hadoop 任务的批量的工作流执行器;其解决了job依赖顺序的问题,并提供了一个简单易用的用户界面检测我们的工作流。
Azkaban特性如下:
-
兼容所有Hadoop版本
-
简单易用的web操作界面和web工作流资源提交机制
-
在Azkaban中每个项目相互独立互不影响。
-
良好的工作流执行封装(执行任务流无需太复杂的操作 一个按钮搞定)。
-
模块化和插件化:执行的具体任务不会与Azkaban相互耦合,代码侵入性低。
-
认证与授权:良好的权限管理机制
-
跟踪用户的行为:方便出现问题后知道是哪个用户的错误导致的。
-
任务成功/失败后的 邮件通知机制
-
任务错误的重试机制
Azkaban3.x 以后不提供直接的安装包下载,其安装包需通过Gradle脚本来编译, 并且要求最低的Java版本是8. 如下是Azkaban的学习网站:
- Azkaban的官网:https://azkaban.github.io
- Azkaban的框架源码:https://github.com/azkaban/azkaban
- Azkaban文档:https://github.com/azkaban/azkaban.github.io
#2. Azkaban架构简析
Azkaban由三个关键组件构成(如下图):
- MySQL关系型数据库:Azkaban使用数据库存储大部分状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
- AzkabanWebServer:AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。
- AzkabanExecutorServer:早期版本的Azkaban在单个服务中具有AzkabanWebServer和AzkabanExecutorServer功能,目前Azkaban已将AzkabanExecutorServer分离成独立的服务器。其好处是某个任务流失败后,可以更方便的将其重新执行,便于Azkaban升级。

Azkaban的两种运行模式
在版本3.0中,Azkaban提供了以下两种模式:
- solo server mode:最简单的模式,数据库内置的H2数据库,AzkabanWebServer和AzkabanExecutorServer都在一个进程中运行,任务量不大项目可以采用此模式(特别适合初学者学习使用,功能齐全)。
- multiple executor mode: 适用于更多的生产环境,其使用MySQL 来进行元数据管理并且支持主从结构。在这种模式下web server和executor server 独立运行在不同的主机中。这种模式带来的好处是可以让Azkaban更加健壮和可扩展。
在学习的过程中,我们可以使用来solo server 这种模式来运行Azkaban实例。
3. Azkaban的下载和编译
-
下载之前 请确保本机的 Java 版本为 1.8 。
-
下载Azkaban源码:

-
解压azkaban压缩包并进入该目录:

azkaban-common: 基本的依赖包
azkaban-db: 框架核心组件-数据库工具
azkaban-exec-server & azkaban-web-server : 框架核心组件
azkaban-solo-server: 集成运行模式工具包
azkaban-spi : azkaban存储接口以及exception类
azkaban-hadoop-security-plugin: hadoop 有关kerberos插件
-
在编译源码之前,先要下载gradle的依赖包,至于要什么版本,查看如下:

如下地址是Gradle的官方下载地址:https://services.gradle.org/distributions
下载好对应的版本后,将压缩包存放到如下位置:

修改配置文件:

-
返回安装包主目录执行编译程序(注意官方给出的编译版本不带测试命令-x test,示例如下)
# Build without running tests >$ ./gradlew build installDist -x test -
执行上面的命令,出现了git有关的异常,这里主要是系统没有安装git命令,使用
yum install -y git,后重新执行步骤4,接下来等待漫长的下载(因为默认使用的是国外的gradle镜像进行资源下载)。
-
为了减少编译时下载占用时间,一般会为gradle远程资源提供镜像地址方便下载:
#在 ${AZKABAN_HOME}/build.gradle文件中配置,然后重新执行步骤4: mavenLocal() maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/'} maven{ url 'http://maven.oschina.net/content/groups/public/'}
-
编译成功后,可以找到整个架构的每个部分都会多出一个build文件夹,这才是我们要安装的文件:
[root@azkabanvm azkaban]# ls azkaban-solo-server/build classes distributions install libs resources tmp [root@azkabanvm azkaban]# ls azkaban-exec-server/build classes distributions install libs resources tmp [root@azkabanvm azkaban]# ls azkaban-web-server/build classes distributions dust install jsToPackage less libs nodejs resources tmp [root@azkabanvm azkaban]# ls azkaban-db/build classes distributions install libs sql tmp
4. Azkaban-solo-server安装
在上一节的讲解中,我们已经完成Azkaban各个模块的编译。如下:
$AZKABAN_SOURCE_HOME/azkaban-solo-server/build/distributions/*.tar.gz(zip)
$AZKABAN_SOURCE_HOME/azkaban-web-server/build/distributions/*.tar.gz(zip)
$AZKABAN_SOURCE_HOME/azkaban-executor-server/build/distributions/*.tar.gz(zip)
将其对应包下的.tar.gz文件拷贝到独立的文件夹下(该文件夹用来安装 Azkaban)并解压,并且不要忘记拷贝azkaban-db/build/distributions/xxx.sql文件(这是一个数据库初始化的脚本文件) :
[root@azkabanvm packages]# ll
total 58276
drwxr-xr-x. 6 root root 4096 Sep 29 01:24 azkaban-exec-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 15767192 Sep 29 01:24 azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz
drwxr-xr-x. 8 root root 4096 Sep 29 01:25 azkaban-solo-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 23876418 Sep 29 01:25 azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz
drwxr-xr-x. 6 root root 4096 Sep 29 01:25 azkaban-web-server-0.1.0-SNAPSHOT
-rw-r--r--. 1 root root 20009922 Sep 29 01:25 azkaban-web-server-0.1.0-SNAPSHOT.tar.gz
初始化MySQL,这里直接贴出最简单的安装方式:
yum install -y mysql-server
yum install -y mysql
service mysqld start
mysql> mysql -u root -p
mysql> ##第一次安装没有密码 直接按Enter键 然后修改当前密码
mysql> set password for 'root'@'localhost' = password('root') ;
mysql> grant all privileges on *.* to [email protected] identified by 'root';
mysql> FLUSH PRIVILEGES;
mysql> create database azkaban;
将sql文件导入到azkaban数据库中:
mysql> use azkaban;
mysql> source /usr/local/azkaban/packages/create-all-sql-0.1.0-SNAPSHOT.sql;
mysql> show tables;
生成秘钥文件:
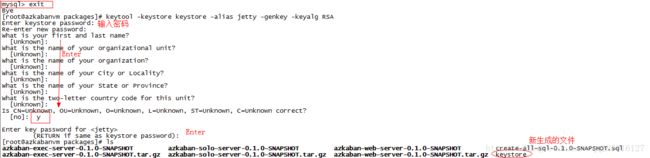
打开azkaban-solo-server-0.1.0-SNAPSHOT/conf/azkaban.properties文件(这里主要配置的是数据库驱动和证书认证):
default.timezone.id=Asia/Shanghai
database.type=mysql
mysql.port=3306
## 这里最好配置IP地址
mysql.host=192.168.66.170
mysql.database=azkaban
mysql.user=root
mysql.password=sql_9879
mysql.numconnections=100
jetty.use.ssl=true
jetty.maxThreads=25
jetty.ssl.port=8666
jetty.port=8081
#注意这里要统一配置好keystore文件存储的路径
jetty.keystore=.../keystore
jetty.password=000000
jetty.keypassword=000000
#注意这里要统一配置好keystore文件存储的路径
jetty.truststore=.../keystore
jetty.trustpassword=000000
从azkaban.properties文件内容可以看出还有一个文件是用来管理登录的用户的,那就是azkaban-users.xml,我们可以在这个文件中配置密码:

在本机的 /etc/hosts 文件中添加本机IP地址的映射:
127.0.0.1 azkabanvm
返回azkaban-solo-server-0.1.0-SNAPSHOT目录,在这个目录下启动solo:
[root@azkabanvm azkaban-solo-server-0.1.0-SNAPSHOT]# bin/start-solo.sh
[root@azkabanvm azkaban-solo-server-0.1.0-SNAPSHOT]# jps
3252 Jps
3227 AzkabanSingleServer
#如果进程没有启动 可以在当前目录下会自动创建启动脚本的日志:
[root@azkabanvm azkaban-solo-server-0.1.0-SNAPSHOT]# cat soloServerLog__2018-09-29+18\:30\:29.out
注意:上面的solo-server会创建一个叫AzkabanSingleServer的进程,并在启动一会之后主动退出,这个操作可以用来检查我们的配置文件是否正确。而我们真正要启动的是一个Executor 进程和 Web进程。
5. web/executor-server 安装
将solo-server下的azkaban.properties文件和azkaban-users.xml文件拷贝到web/conf 文件夹下。
启动web服务:
[root@azkabanvm azkaban-web-server-0.1.0-SNAPSHOT]# bin/start-web.sh
[root@azkabanvm azkaban-web-server-0.1.0-SNAPSHOT]# jps
3744 Jps
3336 AzkabanWebServer
从启动的日志文件中我们也可以看到启动的端口,注意这里一定要保证防火墙是关闭的:
[root@azkabanvm azkaban-web-server-0.1.0-SNAPSHOT]# service iptables stop
在网页端访问ssl页面:
将solo-server下的azkaban.properties文件和azkaban-users.xml文件拷贝到executor/conf 文件夹下。
进入executor文件夹,启动executor进程:
[root@azkabanvm azkaban-exec-server-0.1.0-SNAPSHOT]# bin/start-exec.sh
[root@azkabanvm azkaban-exec-server-0.1.0-SNAPSHOT]# jps
3634 Jps
3607 AzkabanExecutorServer
3336 AzkabanWebServer
6. 普通shell命令Job
登录页面后,创建一个Job项目。
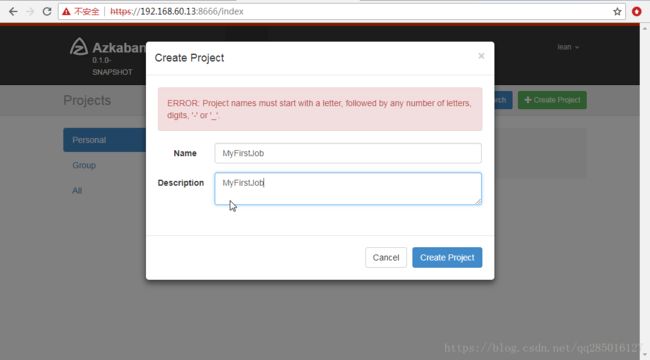
创建command.job文件,内容如下,拷贝完成后将其打包成zip文件 上传Job项目中:
#command.job
type=command
command=echo 'hello'
第一次执行项目时出现卡住的现象,主要是azkaban要求执行Job必须运行在最低有3G的内存空间里,如果你不需要这样的限制可以修改executor/plugins/jobtypes/commonprivate.properties文件,将memCheck.enabled=false。然后重启整个服务(包括web和executor)。重新执行任务才会成功。
7. HDFS操作的Job
除了可以在Azkaban上执行普通的shell命令,还可以执行HDFS的命令,接下来用一个小案例来实现:

首先要确保命令没有错,接下来自己写一个job,内容如下:
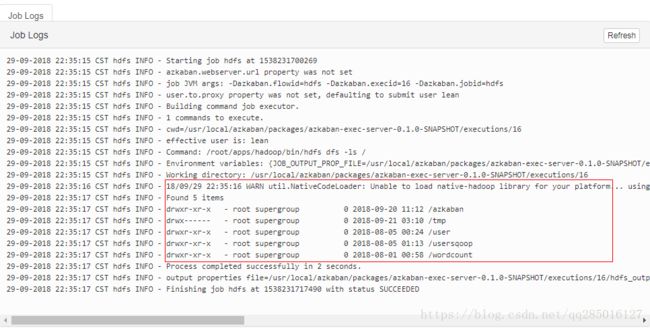
#hdfs.job
type=command
command=/root/apps/hadoop/bin/hdfs dfs -ls /
在控制台查看结果如下:
8. MapReduce操作的Job
既然可以操作HDFS,那么是否可以执行MapReduce , 为了验证这个结果,首先要有个MapReduce程序,如下:

对于执行MapReduce,操作时候可以将jar包和job文件一起打包,也可以在job内部指定jar包的路径:
#mapreduce.job
type=command
command=/root/apps/hadoop/bin/hadoop jar /root/apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 5 5
执行结果如下:

9. Hive操作的Job
首先 要保证环境中有hive工具可以使用,并有对应的数据库可以操作,hive.job内容如下:
##hive.job
type=command
command=/root/apps/hive/bin/hive -f curd.sql
curd.sql 内容如下:
describe user_info;
将这两部分内容打包到azkaban平台,执行如下:
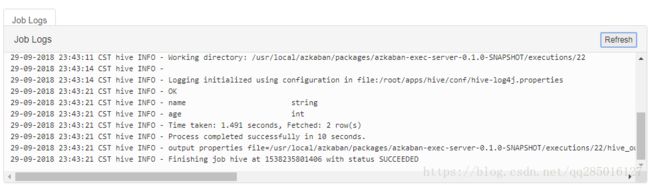
10. 任务的依赖关系
在Azkaban中实际生产中,更多使用的是多个不同任务的Job形成新的的Job,其内部的每个job都需要定义好执行的顺序,这里可以使用dependencies属性来配置。
##foo.job
type=command
command=echo "foo"
##bar.job
type=command
dependencies=foo
command=echo "bar"
11. Azkaban知识点补充
Azkaban支持的指令类型有很多种,比如shell指令,hadoop shell指令,Java代码,hadoop java代码,Pig 指令,Hive指令等等,但是最常见的还是shell 的command指令,官方路径是: https://azkaban.readthedocs.io/en/latest/jobTypes.html 。
在一个job中可以一次性执行多个不同的command指令,像 command.1 , command.2 等等…
##multiple commands job
type=command
command.1=ls /root
command.2=mkdir /root/wolfcode
command.3=...
当前我们最常用的是方式是通过Azkaban 提供的网页端来操作任务流,同时Azkaban 也提供了ajax api的方式来操作任务流,详情可以查看官方文档:https://azkaban.readthedocs.io/en/latest/ajaxApi.html?highlight=ajax。
1.执行工作流界面:From the Flow View panel, you can right click on the graph and disable or enable jobs. Disabled jobs will be skipped during execution as if their dependencies have been met. Disabled jobs will appear translucent.
2.在工作流的左边还有一个通知面板,在当执行完成/成功/失败的时候,可以通过配置email来进行相关责任人的通知(这个模块因为及时性比较低 一般用不到)
3.在工作流左下角还有一个定时器的按钮,其时间的规范与crontab 的时间规范一致,其用来指定任务做定时执行。
