注意力模型CBAM
论文:CBAM: Convolutional Block Attention Module
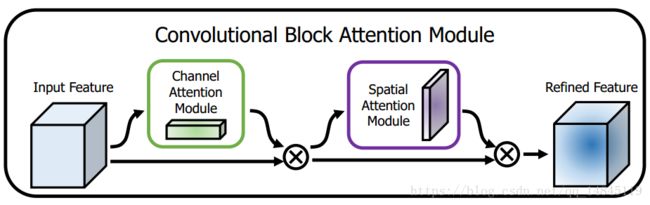
Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
基于传统VGG结构的CBAM模块。需要在每个卷积层后面加该模块。
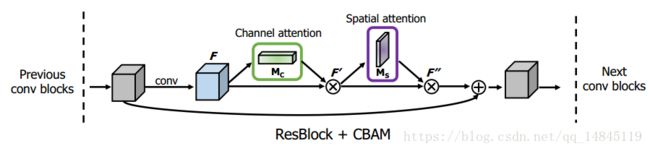
基于shortcut结构的CBAM模块。例如resnet50,该模块在每个resnet的block后面加该模块。
Channel attention module:
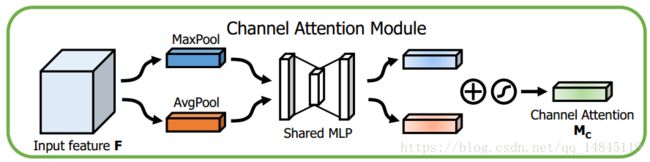
将输入的featuremap,分别经过基于width和height的global max pooling 和global average pooling,然后分别经过MLP。将MLP输出的特征进行基于elementwise的加和操作,再经过sigmoid激活操作,生成最终的channel attention featuremap。将该channel attention featuremap和input featuremap做elementwise乘法操作,生成Spatial attention模块需要的输入特征。
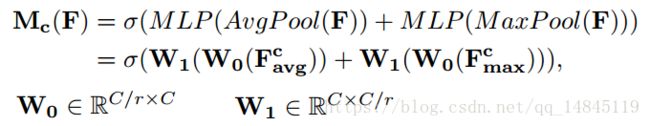
其中,seigema为sigmoid操作,r表示减少率,其中W0后面需要接RELU激活。
Spatial attention module:
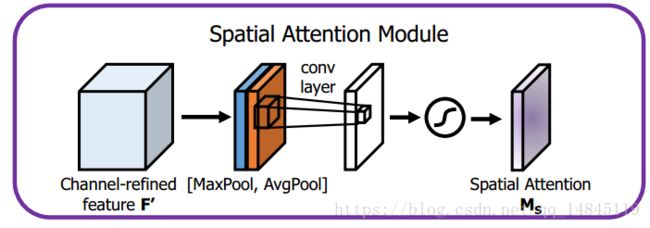
将Channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
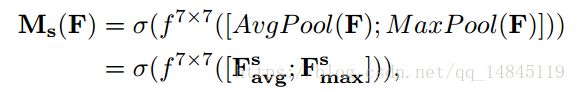
其中,seigema为sigmoid操作,7*7表示卷积核的大小,7*7的卷积核比3*3的卷积核效果更好。
The code:
def cbam_module(inputs,reduction_ratio=0.5,name=""):
with tf.variable_scope("cbam_"+name, reuse=tf.AUTO_REUSE):
batch_size,hidden_num=inputs.get_shape().as_list()[0],inputs.get_shape().as_list()[3]
maxpool_channel=tf.reduce_max(tf.reduce_max(inputs,axis=1,keepdims=True),axis=2,keepdims=True)
avgpool_channel=tf.reduce_mean(tf.reduce_mean(inputs,axis=1,keepdims=True),axis=2,keepdims=True)
maxpool_channel = tf.layers.Flatten()(maxpool_channel)
avgpool_channel = tf.layers.Flatten()(avgpool_channel)
mlp_1_max=tf.layers.dense(inputs=maxpool_channel,units=int(hidden_num*reduction_ratio),name="mlp_1",reuse=None,activation=tf.nn.relu)
mlp_2_max=tf.layers.dense(inputs=mlp_1_max,units=hidden_num,name="mlp_2",reuse=None)
mlp_2_max=tf.reshape(mlp_2_max,[batch_size,1,1,hidden_num])
mlp_1_avg=tf.layers.dense(inputs=avgpool_channel,units=int(hidden_num*reduction_ratio),name="mlp_1",reuse=True,activation=tf.nn.relu)
mlp_2_avg=tf.layers.dense(inputs=mlp_1_avg,units=hidden_num,name="mlp_2",reuse=True)
mlp_2_avg=tf.reshape(mlp_2_avg,[batch_size,1,1,hidden_num])
channel_attention=tf.nn.sigmoid(mlp_2_max+mlp_2_avg)
channel_refined_feature=inputs*channel_attention
maxpool_spatial=tf.reduce_max(inputs,axis=3,keepdims=True)
avgpool_spatial=tf.reduce_mean(inputs,axis=3,keepdims=True)
max_avg_pool_spatial=tf.concat([maxpool_spatial,avgpool_spatial],axis=3)
conv_layer=tf.layers.conv2d(inputs=max_avg_pool_spatial, filters=1, kernel_size=(7, 7), padding="same", activation=None)
spatial_attention=tf.nn.sigmoid(conv_layer)
refined_feature=channel_refined_feature*spatial_attention
return refined_feature