Detectron:训练自己的数据集——将自己的数据格式转换成COCO格式
Detectron系列:
Detectron:assert len(cfg_list) % 2 == 0 AssertionError
Detectron:用自己训练好的模型进行测试
1.前情提要
Fackbook的开源检测框架Detectron已开源了一段时间:
https://github.com/facebookresearch/Detectron
但苦于之前都是用Keras和Tensorflow,没接触过caffe2,所以一直没有尝试,~~~并且之前没用过linux系统,对于命令基本不懂~~,好在会用浏览器,遇到问题就查查,也算是把坑都给踩遍了,最后总算有惊无险,用上了强大的Detectron啦。
关于安装caffe2和Detectron等有空了在写~! 这篇文章主要说一下如何制作该框架所需的标注格式!但是呢~~~由于自定义自己的数据集比较繁琐,推荐使用Detectron自带的COCO数据集名称,并将自己的数据集转化为COCO数据集的格式,当然如果你是大佬,忽略这个~~现在,没错,就是现在~~~来分享一下如何生成这种COCO格式~~~
2.COCO数据集格式
首先,通过http://cocodataset.org/#format-data(COCO官网)了解了coco数据集的格式如下:

对于目标检测的话,还需要关注BBOX格式如下:
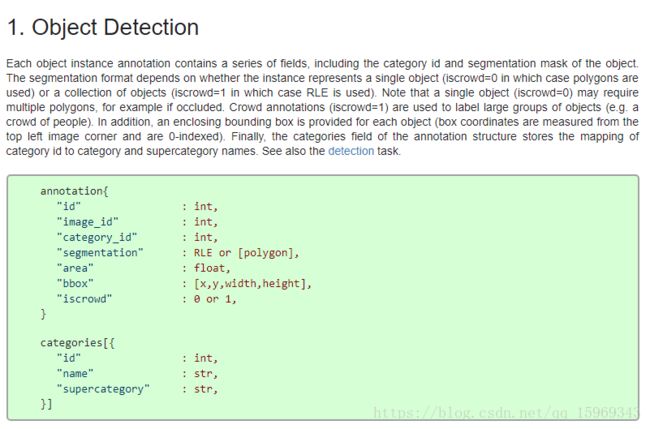
那么,我们只要将我们的数据格式转换为以上即可~
3.转化自己的数据集
3.1数据放置方式
我们需要创建一个文件夹,用于存放图片以及标注数据,具体的放置方式如下:
├── annos.txt
├── annotations
├── classes.txt
└── images
其中,annos放置数据集的原始标注文件,可能是txt,或者csv格式;classes.txt放置你标注的类别名称,每行一个类别,不含背景;images放置数据集的原始图像文件。annotations预备放置与COCO数据集格式的标注文件。下面需要将我们自己的标注文件生成COCO格式的标注文件。
3.2转换自己的数据
我自己的数据如下所示:

每行对应一条BBOX标记:filename,label, x_min, y_min, x_max, y_max ,下面开始转换:
我们使用os提取images文件夹中的图片名称,并且将BBox都读进去:
import json
import os
import cv2
# 根路径,里面包含images(图片文件夹),annos.txt(bbox标注),classes.txt(类别标签),以及annotations文件夹(如果没有则会自动创建,用于保存最后的json)
root_path = 'E:\dogcat\\f_train\data\\get_json\\'
# 用于创建训练集或验证集
phase = 'val'
# 训练集和验证集划分的界线
split = 8000
# 打开类别标签
with open(os.path.join(root_path, 'classes.txt')) as f:
classes = f.read().strip().split()
# 建立类别标签和数字id的对应关系
for i, cls in enumerate(classes, 1):
dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})
# 读取images文件夹的图片名称
indexes = [f for f in os.listdir(os.path.join(root_path, 'images'))]
# 判断是建立训练集还是验证集
if phase == 'train':
indexes = [line for i, line in enumerate(_indexes) if i <= split]
elif phase == 'val':
indexes = [line for i, line in enumerate(_indexes) if i > split]
# 读取Bbox信息
with open(os.path.join(root_path, 'annos.txt')) as tr:
annos = tr.readlines()接着将,以上数据转换为COCO所需要的
for k, index in enumerate(indexes):
# 用opencv读取图片,得到图像的宽和高
im = cv2.imread(os.path.join(root_path, 'images/') + index)
height, width, _ = im.shape
# 添加图像的信息到dataset中
dataset['images'].append({'file_name': index,
'id': k,
'width': width,
'height': height})对于一个图有着多个框的情况判断一下:
for ii, anno in enumerate(annos):
parts = anno.strip().split()
# 如果图像的名称和标记的名称对上,则添加标记
if parts[0] == index:
# 类别
cls_id = parts[1]
# x_min
x1 = float(parts[2])
# y_min
y1 = float(parts[3])
# x_max
x2 = float(parts[4])
# y_max
y2 = float(parts[5])
width = max(0, x2 - x1)
height = max(0, y2 - y1)
dataset['annotations'].append({
'area': width * height,
'bbox': [x1, y1, width, height],
'category_id': int(cls_id),
'id': i,
'image_id': k,
'iscrowd': 0,
# mask, 矩形是从左上角点按顺时针的四个顶点
'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]
})接着将结果保存:
# 保存结果的文件夹
folder = os.path.join(root_path, 'annotations')
if not os.path.exists(folder):
os.makedirs(folder)
json_name = os.path.join(root_path, 'annotations/{}.json'.format(phase))
with open(json_name, 'w') as f:
json.dump(dataset, f)查看结果:
