python进阶(爬虫正则表达式)
一、正则表达式的基本知识:
1、正则表达式是一种高度专业化的编程语言,并不是只在python语言中存在,而python需要插入 re 模块才能使用 正则表达式。
2、正则表达式只能处理字符串,用于模糊匹配。
3、正则表达式的区间是闭区间。
4、正则表达式的匹配方式:正则项 被包含于 字符串 时均可匹配 , 可以用 ^ $ 来具体匹配正则项
二、正则表达式组成:
1、正则表达式由字符集[...]、量词(* + ?{ })、边界(^ $)、逻辑( | )、re模块的函数五部分组成。
2、一个字符集(\d \w 这些也属于字符集,它们不需要用 [ ] 包裹 )不论有多复杂,在没有量词的情况下,只代表一个字符。
import re
print(re.findall('\d','234da')) ['2', '3', '4', '5']
print(re.findall('\d\d','234da')) ['23', '45'] 相当于两个字符集三、字符组([....]):
①一个字符组只能匹配一个字符,它是一个闭区间。
②字符集内特殊意义的字符大都会失去原有的含义,类型转义字符 \ 。(转义字符 \ 和 小括号不会失去含义)
④字符组中的范围可以相连:[0-9a-zA-Z+_-],中间不需要加逗号分隔,也不要用[[0-9][a-z][A-Z]+_-]这种中间套[]的方式。
⑤字符组中元素见得关系是或的关系,例:[^abc] [^a|b|c] 
⑥ ^ 如果在[ ]内部的开头,代表 非 ,若果在正则表达式开头,代表匹配必须是 行头。
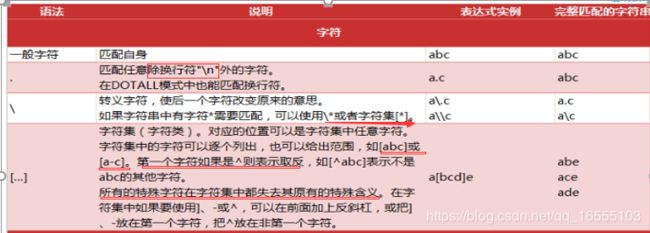
常见的字符:
(1)直接匹配:
匹配表达式就是字符本身。
import re
print(re.findall('ab','++=_-aabjab_-=jk'))
['ab', 'ab'](2)通配字符( . ):
能够匹配除了换行符(\n)以外的所有字符。
import re
print(re.findall('.','+=_-a | \n *')) # 包括 空格
['+', '=', '_', '-', 'a', ' ', '|', ' ', ' ', '*'](3)转义字符(\):
①
import re
print('换行符\n换行了') 转义字符在print语句中的用法。
print('转义符\\n转义了') 转义了 \n
print(r'raw方法将字符串\n转化为元字符!') \n失去意义,字符串前加上 r,就会将转化为无意义的元字符(raw)。
# 换行符可以直接匹配
print(re.findall('\n','jadj \n ajfkfjjjfj'))
print(re.findall('\\n','jadj \n ajfkfjjjfj')
# 需要转义(一些在正则表达式中有意义的字符 * ? + 等)
print(re.findall('\+','jad + ajfkfjjjfj'))
print(re.findall('[+]','jad + ajfkfjjjfj')) []可以使特殊字符没有意义。
print(re.findall('\.','jadj . ajfkfjjjfj'))
print(re.findall('[.]','jadj . ajfkfjjjfj'))
print(re.findall('\[\]','jadj . ajfkfjjj[]fj')) 结果: ['[]'],[]在正则中有意义,需要转义
print(re.findall('\(\)','jadj . ajfkfjjj()fj')) 结果:['()']
换行符
换行了
转义符\n转义了
raw方法将字符串\n转化为元字符!
['\n']
['\n']
['+']
['+']
['.']
['.']
②转义字符(\)匹配方法:
特殊:
print(re.findall('','ajd')) 结果:['', '', '', '']
正则表达式:
\\ ----------- 匹配 \
python中re模块中正则表达式:
转义字符本身匹配 (未解决问题)
print('ajdjca\\cjijfj') # ajdjca\cjijfj
print('ajdjca\cjijfj') # ajdjca\cjijfj
print(re.findall('a\\\c','ajdjca\cjijfj')) 结果:['a\\c']
print(re.findall('a\\c','ajdjca\cjijfj')) 报错③常用方法:
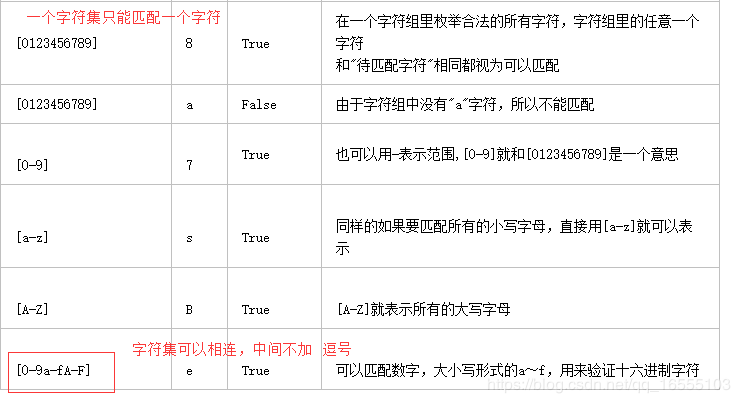
④易错:
1、 字符集元素之间是 或 的关系。
print(re.findall('[^abc]','123adbc'))
print(re.findall('[^(a|b|c)]','123adbc'))
['1', '2', '3', 'd']
['1', '2', '3', 'd']
2、 字符组中的范围 直接相连
print(re.findall('[0-9a-c]','12zafc'))
print(re.findall('[[0-9][a-c]]','12zafc'))
print(re.findall('[]]]]','12zafc[0]]]]'))
['1', '2', 'a', 'c']
[]
[']]]']3、字符:
这种字符可以理解为 字符集[...]的简写方式,在没有量词的情况下
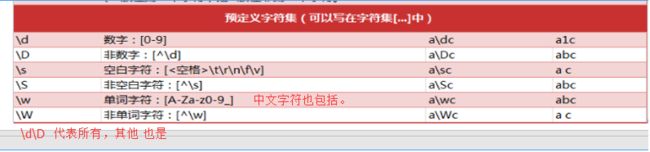
可以嵌套在字符组中。
一个\d或[...]代表一个字符
import re
print(re.findall('[\d]','16hgdh6'))
print(re.findall('\d','16hgdh6'))
print(re.findall('\d\w','16hgdh6'))
['1', '6', '6']
['1', '6', '6']
['16']4、中文字符:
'[\u4e00-\u9fa5]' ------------- 匹配一个中文字符]一个字符集只能匹配一个中文字符。 \w 也包括中文字符。
四、数量词:
特点 : 前闭后闭
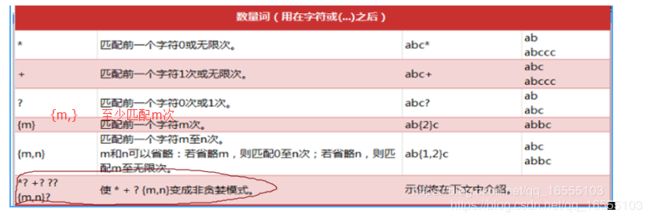
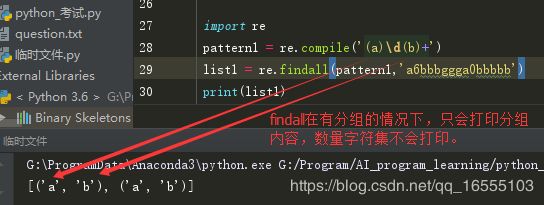
① 数量词只增加其前面 一个字符集的次数,如果要重复多个字符集,应当加入分组(),加入分组以后,findall只会打印分组的内容。如下:
② 默认情况是贪婪匹配。
import re
print(re.findall('ab*','abbbbbbbbbbbdddabba')) ['abbbbbbbbbbb', 'abb', 'a'] 默认贪婪匹配,且只增加前面一个字符。
print(re.findall('ab*?','abbbddda')) ['a', 'a'] 数量词加 ? 改变贪婪匹配
print(re.findall('(ab)*','abababbbddda')) 结果:['ab', '', '', '', '', '', '', ''],注意其实匹配结果是 ababab,
因为findall只打印 分组的内容。其次由于是 * (0 - 无穷),因此空集也会打印。
for i in re.finditer('(ab)*','abababbbddda'): # 遍历查看内容。
print(i.group())===================== 利用非贪婪模式匹配img 标签的 src =======================
 正则:' \".*?\" ' ---- 结果:a.png b.png
正则:' \".*?\" ' ---- 结果:a.png b.png
五、边界匹配:

六、逻辑与分组:
逻辑或可以多个使用: abc | mjk | iop

①分组的常见用法: 匹配邮箱(多个后缀 -------- .com.cn)
/^[a-zA-Z0-9]\w*@\w+(\.[a-zA-Z]{2,3}){1,2}$/
② 关于 | -------- 左边 一旦匹配,右边不在执行:
例: ![]()
-------------------------- 不考虑 平运年 大小月份
1、错误的实例:
^(19\d{2}|200\d)\-(0?[1-9]|1[0-2]\-(0[1-9]|[1-2]\d|3[0-1])$
2、正确的实例:
^(19\d{2}|200\d)\-(1[0-2]|0?[1-9])\-(0[1-9]|[1-2]\d|3[0-1])$
----- 月份不包括 00 日期不包括 00
七、re模块正则表达式的函数:
- 特点:① 匹配的方法有:.findall()、.seach()、.match() ,注意它们的区别
(1)findall用法:

1、 findall 结果是一个 list,finditer结果是一个迭代对象,可以通过for i in 迭代器 print(i.group()) 遍历。
2、没有时返回 空列表,可以用于条件语句当中。
3、pattern可以调用其他函数。

(2)match()与search()用法:
- 特点:①两个都只匹配一次,findall匹配所有。
- ②两个函数在有匹配成功时会返回一个匹配对象,通过 该对象.group()查看所有匹配内容,
- 而group(n) 查看匹配的分组的内容。
import re
str1 = '123abcfdd1234'
print(re.match('[a-z]{5}',str1))
print(re.match('\d+',str1)) <_sre.SRE_Match object; span=(0, 3), match='123'> 可放在if 语句中。
print(re.match('\d+',str1).group()) 123两个函数在匹配失败时会返回None,因此两个函数常用 if 条件语句当中。

import re
str1 = '123abcf1234'
print(re.match('1234',str1)) # None
print()
if re.match('1234',str1):
pass
else:
print('字符串不是以1234开头')
if re.search('1234',str1):
print('字符串包含1234')
答案:
None
字符串不是以1234开头
字符串包含1234
# 例子:
2. 判断以下字符是否全是中文(中文正则模式[\u4E00-\u9FA5])
str='广东省广州市';
import re
str1 = '1回家了吗,'
str2 = '吃饭了吗hhh'
if re.search('[^\u4E00-\u9FA5]+',str2): # 注意search与match的区别
print('不是全是中文')
else:
print('全是中文!')
(3)raw方法:
import re
print(re.findall('\\n','abc\nmk')) # 转义
print(re.findall('\\\\n','abc\\nmk'))
print(re.findall(r'\\n',r'abc\nmk')) r 的用法
['\n'] # 换行符
['\\n'] # 普通字符 \n
['\\n'] # 普通字符 \n
(4)re模块中split、finditer、sub、subn用法:
finditer 有分组时 默认可以遍历(for 循环 加上 .group( )) 所有匹配字符,包括分组。
spilt 不包含分割符 ,
import re
pattern1 = re.compile('\d[a-z]\d')
print(re.split(pattern1,'1a2hjfajh5g678787d833333333'))
print(re.split(pattern1,'1a2hjfajh5g678787d833333333',2)) 分割两次
['', 'hjfajh', '7878', '33333333']
['', 'hjfajh', '78787d833333333'] sub 、subn(比sub多了计数) 类似于 str.replace() 的用法,把 。。 替换为 。。。,它支持分组引用。
八:分组 .group() 与组的引用:
- 特点:分组 ( ) 不仅仅只有findall,search与match同样具有。
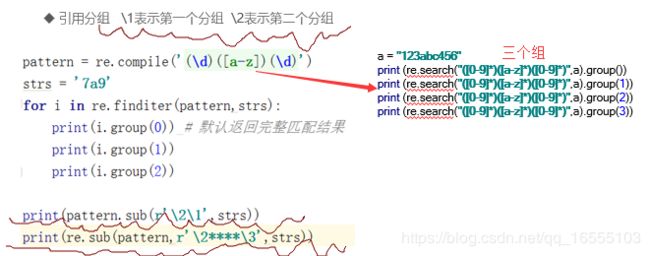
1、利用分组编号打印组信息:
分组编号默认是从 1 开始的。
(1) match 与search findall 打印 分组。
import re
str1 = '123456789abcfdd1234'
aaa = re.match('(\d+)(\d+)',str1) # 第一个是贪婪匹配
print(aaa.group())
print(aaa.group(0))
print(aaa.group(1)) # 第一组
print(aaa.group(2)) # 第二组
print(re.findall('(\d+)(\d+)',str1)
123456789
123456789
12345678
9
[('12345678', '9'), ('123', '4')]2、finditer 打印分组:
默认打印所有匹配信息

3、sub、subn分组引用:
应用:将电话号码13811119999变成138****9999
十、 利用分组巧妙链接地址:
1、
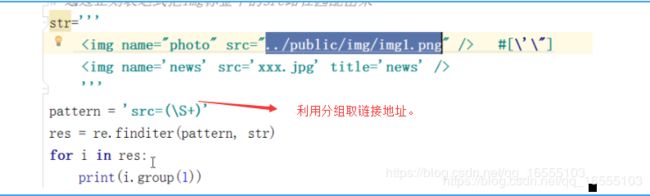
2、利用非贪婪匹配 :
正则:' \".*?\" ' ---- 结果:a.png b.png