Bi-LSTM-CRF算法详解-1
第1节 介绍
1.介绍
Bi-LSTM-CRF算法是目前最为流行的NER算法。
BiLSTM和CRF可以看做NER模型中的两个不同层
1.1 开始之前
假设我们有一个数据集,其中有两种实体类别:Person和Organization。对于每一个类别又分为开始单词和中间单词,所以就有了5种类别。
- B-Person (Person的第一个单词)
- I- Person (Person的中间单词)
- B-Organization (Organization的第一个单词)
- I-Organization (Organization的中间单词)
- O (其他实体)
比如 x x x是包含5个单词的句子 w 0 , w 1 , w 2 , w 3 , w 4 w0,w1,w2,w3,w4 w0,w1,w2,w3,w4.其中[ w 0 , w 1 w_0,w_1 w0,w1]是Person实体, [ w 2 , w 3 w_2,w_3 w2,w3] 是Organization实体,其他是“O”.
1.2 BiLSTM-CRF model
- 首先,句子x中的每一个单词都会被表示成一个向量,这个向量包含单词的character embedding 以及word embedding. 这里的character embedding随机初始化.word embedding通常来自一个预训练的word embedding文件. 所以的embeddings都会在训练过程中微调
- 然后,BiLSTM-CRF模型的输入是这些embeddings,输出是句子x的所以单词的预测标签.

我们需要知道BiLSTM这一层输出结果的意义
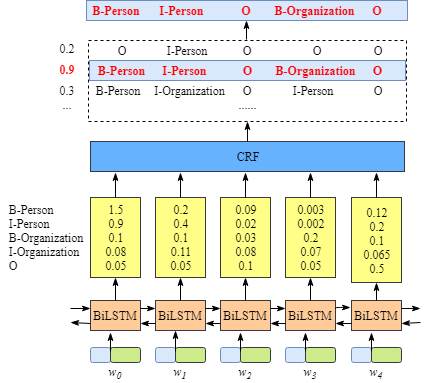
上图说明BiLSTM的输出是该单词对应每一个类别的scores。举例来说,对于
w0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) 以及0.05 (O). 这些score作为CRF layer的输入.
然后所有的BiLSTM blocks预测的score都会被喂到CRF layer. CRF layer中,在所有的label sequence选择预测得分最高的序列作为最佳答案.
1.3 如果没有CRF layer会怎么样
你可能会发现,如果没有CRF Layer,也可以只用BiLSTM来训练NER模型
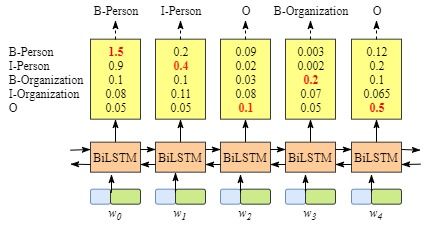
由于每个word的BiLSTM的输出是labe得分情况. 可以选择每个单词中得分最高的label作为结果。
例如,对于单词 ω 0 \omega_0 ω0, “B-Person”得分最高(1.5), 因此可以选择“B-Person” 作为预测label.
尽管这里可以得到正确的预测结果,但是在有些如下面的情况中,

很显然,预测的labels是不对的。“I-Organization I-Person”以及 “B-Organization I-Person”.因为两个不同类别的中间词不可能挨着等等
1.4 CRF layer 可以学到训练集中的限制
CRF layer 可以对最终的预测labels添加一些限制来确保结果是有效的. 这些限制可以由CRF layer在训练过程中自动的训练数据集中学到.
这些限制可以是
- 句子的第一个单词应该是“B-“或 “O”,不可能是 “I-“
- “B-label1 I-label2 I-label3 I-…”, 在这个模式中, label1, label2, label3 应该是同一个实体label.例如 “B-Person I-Person”是可以的, “B-Person I-Organization” 无效
- “O I-label” 不合法。命名实体的开始应该是 “B-“ 而不是 “I-“
添加了这些限制之后,预测结果中的无效序列会大幅减少
小结
接下来会分析CRF loss function来解释为什么CRF layer 可以学到训练数据中的这些限制。
第二节 CRF 层
在CRF层的损失函数中有两种类型的score,这两种类型的score是CRF layer的关键部分.
2.1 Emission score
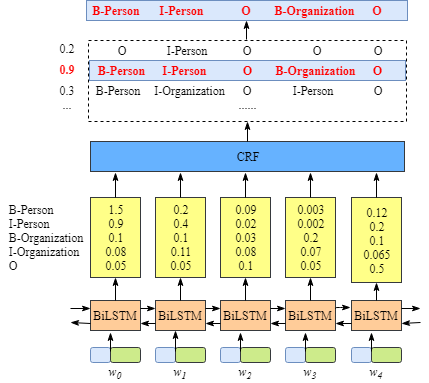
第一个是emission score,这些emission score来自于BiLSTM layer. 如下图所示比如 w 0 w_0 w0作为B-Person标签的得分是1.5.
为了方便,给一种label一个index
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
使用 x i y j x_{iy_j} xiyj来表示emission score。i是单词的index, y j y_j yj是label的index。例如在上图中, x i = 1 , y j = 2 = x w 1 , B − O r g a n i z a t i o n = 0.1 x_{i=1,y_j=2}=x_{w_1,B−Organization}=0.1 xi=1,yj=2=xw1,B−Organization=0.1表示w1作为B-Organization的得分是 0.1.
2.2 Transition score
使用 t y i y j t_{y_iy_j} tyiyj来表示transition score。举例 t B − P e r s o n , I − P e r s o n = 0.9 t_{B−Person,I−Person}=0.9 tB−Person,I−Person=0.9表示标签转移B-Person -> I-Person的概率是0.9.因此。有了保存所有labels之间score矩阵。
加入START和END来使转移矩阵更加健壮。START表示句子的开始,END表示句子的结束。
这里有一个转移矩阵

我们可以看到转移矩阵可以学到一些有用的限制条件
- 句子的开始应该是 “B-“ 或 “O”,而不是 “I-“(从START到I-Person或I-Organization的得分非常低)
- “B-label1 I-label2 I-label3 I-…”, 在这个模式中, label1, label2, label3 应该是同一个实体label.例如 “B-Person I-Person”是可以的(例如 “B-Organization”到“I-Person” 仅仅是0.0003)
- “O I-label” 不合法( t O , I − P E R S O N t_{O,I-PERSON} tO,I−PERSON的得分非常低)
那么如何得到 transition matrix呢
实际上 transition matrix是BiLSTM-CRF model的一个参数。在你开始训练模型之前,可以随机初始化。所有的random score会在训练过程中自动更新
说明CRF layer可以自己学习这些约束,不需要手动建立约束。矩阵会随着迭代过程更加合理。
2.3 CRF loss function
CRF loss function由真实路径得分和和所有可能路径的总分组成. 真实路劲应该具有在可能路径中有最高的分数。
例如数据中有下面的label:
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
| START | 5 |
| END | 6 |
有一个有5个单词的句子,可能的路径可能是
- START B-Person B-Person B-Person B-Person B-Person END
- START B-Person I-Person B-Person B-Person B-Person ENDSTART B-Person I-Person B-Person B-Person B-Person END
- ……
- START B-Person I-Person O B-Organization O END10) START B-Person I-Person O B-Organization O END
- ……
- O O O O O O O
假设每一条路径有一个score P i P_i Pi,一共有 N条路径,所以总得分是 P t o t a l = P 1 + P 2 + … + P N = e S 1 + e S 2 + … + e S N P_{total}=P_1+P_2+…+P_N=e^{S1}+e^{S2}+…+e^{SN} Ptotal=P1+P2+…+PN=eS1+eS2+…+eSN
假设第4条路径是真实路径,那么 P 10 P_{10} P10应该在所有的可能路径中占据最大的比例
下面给出loss function。
L o s s F u n c t i o n = P r e a l p a t h P 1 + P 2 + … + P N LossFunction = \frac{P_{realpath}}{P_1+P_2+…+P_N} LossFunction=P1+P2+…+PNPrealpath
在训练过程中,更新BiLSTM-CRF 的参数,使得真实路径的比重保持不断增加
现在的问题是:
- 如何定义一条路径的score
- 如何计算所有路径的总score
- 计算总score时,需要列出所有可能的路径吗?(不需要)
2.4 Real Path Score
显然在所有可能的路径中有一条真实的路径。
例如真实的路径是“START B-Person I-Person O B-Organization O END”. 其他不正确的路径有“START B-Person B-Organization O I-Person I-Person B-Person”.
e S i e^{Si} eSi是第i条路径的得分.
在训练过程中,crf loss function只需要两个score:真实路径的得分和其他可能路径的总得分.真实路径的得分在所有可能路径得分中的比重会不断增加。
真实路径得分是通过 e S i e^{S_i} eSi计算得到
现在我们关注如何计算 S i S_i Si.
以这条真实路径“START B-Person I-Person O B-Organization O END”来举个例子
- 这条句子中有5个单词 w 1 , w 2 , w 3 , w 4 , w 5 w1,w2,w3,w4,w5 w1,w2,w3,w4,w5
- 增加两个额外的单词来表示句子的开始和结束 w 0 , w 6 w0,w6 w0,w6
- S i S_i Si由两个部分组成 S i = E m i s s i o n S c o r e + T r a n s i t i o n S c o r e S_i=EmissionScore+TransitionScore Si=EmissionScore+TransitionScore
Emission Score
E m i s s i o n S c o r e = x 0 , S T A R T + x 1 , B − P e r s o n + x 2 , I − P e r s o n + x 3 , O + x 4 , B − O r g a n i z a t i o n + x 5 , O + x 6 , E n d EmissionScore = x_{0,START}+x_{1,B-Person}+x_{2,I-Person}+x_{3,O}+x_{4,B-Organization}+x_{5,O}+x_{6,End} EmissionScore=x0,START+x1,B−Person+x2,I−Person+x3,O+x4,B−Organization+x5,O+x6,End
- x i n d e x , l a b e l x_{index,label} xindex,label 表示第index个单词被标记为label的score
- 这些emission score来自于上一步BiLSTM的输出
- 对于 x 0 , S T A R T x_{0,START} x0,START和 x 6 , E N D x_{6,END} x6,END可以设为0
Transition Score
T r a n s i t i o n S c o r e = t S T A R T − > B − P e r s o n + t B − P e r s o n − > I − P e r s o n + t I − P e r s o n − > O + t O − > B − O r g a n i z a t i o n + t B − O r g a n i z a t i o n − > O + t O − > E n d TransitionScore=t_{START->B-Person}+t_{B-Person->I-Person}+t_{I-Person->O}+t_{O->B-Organization}+t_{B-Organization->O}+t_{O->End} TransitionScore=tSTART−>B−Person+tB−Person−>I−Person+tI−Person−>O+tO−>B−Organization+tB−Organization−>O+tO−>End
- t l a b e l 1 − > l a b e l 2 t_{label1->label2} tlabel1−>label2表示从label1到label2的Transition Score
- 这些score来自CRF layer。也就是说这是score是CRF layer的参数
现在我们计算出真实路径的得分 e S i e^{S_i} eSi,下面计算所有可能路径的score。
2.5 The total score of all the paths
这一部分是最难的一部分,最好拿出纸和笔跟着推导整个过程。
本节讨论如何计算所有可能路径的score和 P t o t a l = P 1 + P 2 + … + P N = e S 1 + e S 2 + … + e S N P_{total}=P_1+P_2+…+P_N=e^{S1}+e^{S2}+…+e^{SN} Ptotal=P1+P2+…+PN=eS1+eS2+…+eSN。
最简单的方式是枚举所有的类型。但是效率太低,训练时间太长
第一步:回忆CRF Loss function
前面我们提到了CRF Loss function是
L o s s F u n c t i o n = P r e a l p a t h P 1 + P 2 + … + P N LossFunction = \frac{P_{realpath}}{P_1+P_2+…+P_N} LossFunction=P1+P2+…+PNPrealpath
现在对LossFunction取个对数可以得到:
L o g L o s s F u n c t i o n = log P r e a l p a t h P 1 + P 2 + … + P N LogLossFunction = \log\frac{P_{realpath}}{P_1+P_2+…+P_N} LogLossFunction=logP1+P2+…+PNPrealpath
本来的loss function需要越大越好(真实路径比重越高),但是通常是最小化loss,所以加个符号
L o g L o s s F u n c t i o n LogLossFunction LogLossFunction
= − log P r e a l p a t h P 1 + P 2 + … + P N = -\log\frac{P_{realpath}}{P_1+P_2+…+P_N} =−logP1+P2+…+PNPrealpath
= − log e S r e a l p a t h e S 1 + e S 2 + … + e S N =- \log\frac{e^{S_{realpath}}}{e^{S_1}+e^{S_2}+…+e^{S_N}} =−logeS1+eS2+…+eSNeSrealpath
= − ( log ( e S r e a l p a t h ) − log ( e S 1 + e S 2 + … + e S N ) ) =- (\log({e^{S_{realpath}}})-\log(e^{S_1}+e^{S_2}+…+e^{S_N})) =−(log(eSrealpath)−log(eS1+eS2+…+eSN))
= − ( S r e a l p a t h − log ( e S 1 + e S 2 + … + e S N ) ) = -(S_{realpath}-\log(e^{S_1}+e^{S_2}+…+e^{S_N})) =−(Srealpath−log(eS1+eS2+…+eSN))
= − ( ∑ i = 1 N x i y i + ∑ i = 1 N − 1 t y i y i + 1 − log ( e S 1 + e S 2 + … + e S N ) ) =-(\sum_{i=1}^Nx_{iy_i}+\sum_{i=1}^{N-1}t_{y_iy_{i+1}}-\log(e^{S_1}+e^{S_2}+…+e^{S_N})) =−(∑i=1Nxiyi+∑i=1N−1tyiyi+1−log(eS1+eS2+…+eSN))
之前我们已经知道了如何计算真实路径score(前两项),现在我们需要找到计算 log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1}+e^{S_2}+…+e^{S_N}) log(eS1+eS2+…+eSN)的有效方法
第二步:回忆Emission 和 Transition Score
为了简化,假设训练的模型中的句子只有3个长度,并且label只有两个
x = [ w 0 , w 1 , w 2 ] x=[w_0,w_1,w_2] x=[w0,w1,w2]
L a b e l S e t = { l 1 , l 2 } LabelSet=\{l_1,l_2\} LabelSet={l1,l2}
可以知道对应的Emission和Transition分数

x i j x_{ij} xij表示单词 w i w_i wi属于 l j l_j lj标签的score
此外CRF层中的transition score可以表示为

t i j t_{ij} tij表示从label i 到 label j的转移score
第三步 开始战斗(推导) 带上纸和笔
记住我们的目标是求
log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1}+e^{S_2}+…+e^{S_N}) log(eS1+eS2+…+eSN)
推导的过程是scores累加的过程。这种思想类似于动态规划。
简而言之,首先计算包含 w 0 w_0 w0的所有单词的路径的总得分,然后用这个总得分来计算 w 0 − > w 1 w_0->w_1 w0−>w1。最后用最新的总得分来计算 w 0 − > w 1 − > w 2 w_0->w_1->w_2 w0−>w1−>w2。最后的score就是我们需要的。
接下来说明两个变量:obs previous
previous存储之前所有步的总得分,obs表示当前单词的信息
w 0 w_0 w0
o b s = [ x 01 , x 02 ] obs = [x_{01},x_{02}] obs=[x01,x02]
p r e v i o u s = N o n e previous=None previous=None
如果只有单词 w 0 w_0 w0,没有之前的结果。只有当前词的emission score [ x 01 , x 02 ] [x_{01},x_{02}] [x01,x02]
那么单词 w 0 w_0 w0所有路径的得分可以表示为
T o t o l S c o r e ( w 0 ) = log ( e x 01 + e x 02 ) TotolScore(w_0)=\log(e^{x_{01}}+e^{x_{02}}) TotolScore(w0)=log(ex01+ex02)
w 0 − > w 1 w_0->w_1 w0−>w1
o b s = [ x 11 , x 12 ] obs = [x_{11},x_{12}] obs=[x11,x12]
p r e v i o u s = [ x 01 , x 02 ] previous=[x_{01},x_{02}] previous=[x01,x02]
- 为了计算的方便,把 p r e v i o u s previous previous扩展为
p r e v i o u s = ( x 01 x 01 x 02 x 02 ) previous = \left( \begin{array}{cc} x_{01} & x_{01} \\ x_{02} & x_{02} \end{array} \right) previous=(x01x02x01x02) - 把 o b s obs obs扩展为
o b s = ( x 11 x 12 x 11 x 12 ) obs = \left( \begin{array}{cc} x_{11} & x_{12} \\ x_{11} & x_{12} \end{array} \right) obs=(x11x11x12x12) - 把obs previous transition score加起来
s c o r e s = ( x 01 x 01 x 02 x 02 ) + ( x 11 x 12 x 11 x 12 ) + ( t 11 t 12 t 12 t 22 ) scores = \left( \begin{array}{cc} x_{01} & x_{01} \\ x_{02} & x_{02} \end{array} \right)+\left( \begin{array}{cc} x_{11} & x_{12} \\ x_{11} & x_{12} \end{array} \right)+ \left( \begin{array}{cc} t_{11} & t_{12} \\ t_{12} & t_{22} \end{array} \right) scores=(x01x02x01x02)+(x11x11x12x12)+(t11t12t12t22)
等于下式
s c o r e s = ( x 01 + x 11 + t 11 x 01 + x 12 + t 12 x 02 + x 11 + t 21 x 02 + x 12 + t 12 ) scores = \left( \begin{array}{cc} x_{01}+x_{11}+t_{11} & x_{01}+x_{12}+t_{12} \\ x_{02}+x_{11}+t_{21} & x_{02}+x_{12}+t_{12} \end{array} \right) scores=(x01+x11+t11x02+x11+t21x01+x12+t12x02+x12+t12) - 将previous转变为

实际上第二次迭代已经完成了,下面表示如何计算可能路径的得分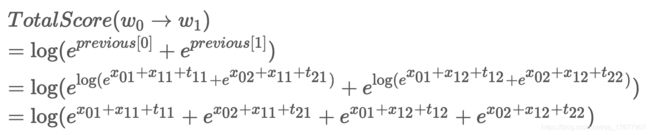
可以看到上面就是我们的目标 log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1}+e^{S_2}+…+e^{S_N}) log(eS1+eS2+…+eSN)

w 0 − > w 1 − > w 2 w_0->w_1->w_2 w0−>w1−>w2
这里的迭代与上面的迭代相似
o b s = [ x 21 , x 22 ] obs = [x_{21},x_{22}] obs=[x21,x22]
![]()
- 把previous扩展成
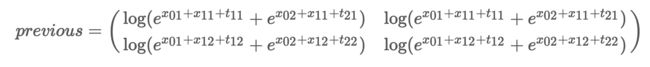
- 把ods扩展成
o b s = ( x 21 x 22 x 21 x 22 ) obs = \left( \begin{array}{cc} x_{21} & x_{22} \\ x_{21} & x_{22} \end{array} \right) obs=(x21x21x22x22) - 把pervious obs transition scores加起来

- 把previous改成下面的形式便于下次的迭代

然后算出所有路径的得分

现在我们算出了 log ( e S 1 + e S 2 + … + e S N ) \log(e^{S_1}+e^{S_2}+…+e^{S_N}) log(eS1+eS2+…+eSN)