判别函数(四)之感知器算法
采用感知器算法(Perception Approach)能通过对训练模式样本集的“学习”得到判别函数的系数。这里采用的算法不需要对各类别中模式的统计性质做任何假设,因此称为确定性的方法。
感知器的训练算法:
已知两个训练模式集分别属于ω1类和ω2类,权向量的初始值为w(1),可任意取值。若![]() ,若
,若![]() ,则在用全部训练模式集进行迭代训练时,第k次的训练步骤为:
,则在用全部训练模式集进行迭代训练时,第k次的训练步骤为:
- 若![]() 且
且![]() ,则分类器对第k个模式xk做了错误分类,此时应校正权向量,使得w(k+1) = w(k) + Cxk,其中C为一个校正增量。
,则分类器对第k个模式xk做了错误分类,此时应校正权向量,使得w(k+1) = w(k) + Cxk,其中C为一个校正增量。
- 若 ![]() 且
且![]() ,同样分类器分类错误,则权向量应校正如下:w(k+1) = w(k) - Cxk
,同样分类器分类错误,则权向量应校正如下:w(k+1) = w(k) - Cxk
- 若以上情况不符合,则表明该模式样本在第k次中分类正确,因此权向量不变,即:w(k+1) = w(k)
若对![]() 的模式样本乘以(-1),则有:
的模式样本乘以(-1),则有: ![]() 时,w(k+1) = w(k) + Cxk
时,w(k+1) = w(k) + Cxk
此时,感知器算法可统一写成:
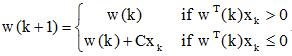
感知器算法实质上是一种赏罚过程对正确分类的模式则“赏”,实际上是“不罚”,即权向量不变。对错误分类的模式则“罚”,使w(k)加上一个正比于xk的分量。当用全部模式样本训练过一轮以后,只要有一个模式是判别错误的,则需要进行下一轮迭代,即用全部模式样本再训练一次。如此不断反复直到全部模式样本进行训练都能得到正确的分类结果为止。
结合下面的例子体会一下(感知器算法的收敛性,只要模式类别是线性可分的,就可以在有限的迭代步数里求出权向量。):

将属于ω2的训练样本乘以(-1),并写成增广向量的形式。x①=(0 0 1)T, x②=(0 1 1)T, x③=(-1 0 -1)T, x④=(-1 -1 -1)T
第一轮迭代:取C=1,w(1)= (0 0 0)T
因wT(1)x①=(0 0 0)(0 0 1)T=0≯0,故w(2)=w(1)+x①=(0 0 1)T
因wT(2)x②=(0 0 1)(0 1 1)T=1>0,故w(3)=w(2)=(0 0 1)T
因wT(3)x③=(0 0 1)(-1 0 -1)T=-1≯0,故w(4)=w(3)+x③=(-1 0 0)T
因wT(4)x④=(-1 0 0)(-1 -1 -1)T=1>0,故w(5)=w(4)=(-1 0 0)T
这里,第1步和第3步为错误分类,应“罚”。
因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。
第二轮迭代:
因wT(5)x①=(-1 0 0)(0 0 1)T=0≯0,故w(6)=w(5)+x①=(-1 0 1)T
因wT(6)x②=(-1 0 1)(0 1 1)T=1>0,故w(7)=w(6)=(-1 0 1)T
因wT(7)x③=(-1 0 1)(-1 0 -1)T=0≯0,故w(8)=w(7)+x③=(-2 0 0)T
因wT(8)x④=(-2 0 0)(-1 -1 -1)T=2>0,故w(9)=w(8)=(-2 0 0)T
需进行第三轮迭代。
第三轮迭代:
因wT(9)x①=(-2 0 0)(0 0 1)T=0≯0,故w(10)=w(9)+x①=(-2 0 1)T
因wT(10)x②=(-2 0 1)(0 1 1)T=1>0,故w(11)=w(10)=(-2 0 1)T
因wT(11)x③=(-2 0 1)(-1 0 -1)T=1>0,故w(12)=w(11)=(-2 0 1)T
因wT(12)x④=(-2 0 1)(-1 -1 -1)T=1>0,故w(13)=w(12)=(-2 0 1)T
需进行第四轮迭代。
第四轮迭代:
因wT(13)x①=1>0,故w(14)=w(13)=(-2 0 1)T
因wT(14)x②=1>0,故w(15)=w(10)=(-2 0 1)T
因wT(15)x③=1>0,故w(16)=w(11)=(-2 0 1)T
因wT(16)x④=1>0,故w(17)=w(12)=(-2 0 1)T
该轮的迭代全部正确,因此解向量w=(-2 0 1)T,相应的判别函数为:
d(x)=-2x1+1
采用感知器算法的多类模式的分类:
感知器算法判别函数的推导
多类情况3:对M类模式存在M个判别函数{di, i = 1,2,…,M},若![]() ,则
,则![]() 。设有M种模式类别ω1,ω2,…,ωM,若在训练过程的第k次迭代时,一个属于ωi类的模式样本x送入分类器,则应先计算出M个判别函数:
。设有M种模式类别ω1,ω2,…,ωM,若在训练过程的第k次迭代时,一个属于ωi类的模式样本x送入分类器,则应先计算出M个判别函数:

直观上是越多越好,但实际上能收集到的样本数目会受到客观条件的限制;过多的训练样本在训练阶段会使计算机需要较长的运算时间;一般来说,合适的样本数目可如下估计:若k是模式的维数,令C=2(k+1),则通常选用的训练样本数目约为C的10~20倍。