图解排序算法及实现——希尔排序 (Shell Sort)
希尔排序(ShellSort)也称增量递减排序算法,即跨多步版的InsertionSort,是InsertionSort基础上的改进版。InsertionSort可以看作ShellSort中gap=1的特例。希尔排序是非稳定排序算法。
希尔排序通过将全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
ShellSort的关键点在于gap序列的设计。
直观理解1:以报数为例
每一轮报数,队列中123123…(gap=3)地报数,所有报1的人组成一组,在原队列中进行插入排序,其他组类似。
报数分为好几轮,每轮gap值减小一次,每一轮都使序列渐进有序化,直到最后一轮gap=1,即为原始InsertionSort。从这个意义上说,ShellSort是加了预处理的InsertionSort。
直观理解2: 将数组列在一个表中,然后列排序
假设有这样一组数
[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ]如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94最后以1步长进行排序(此时就是简单的插入排序了)。
图解
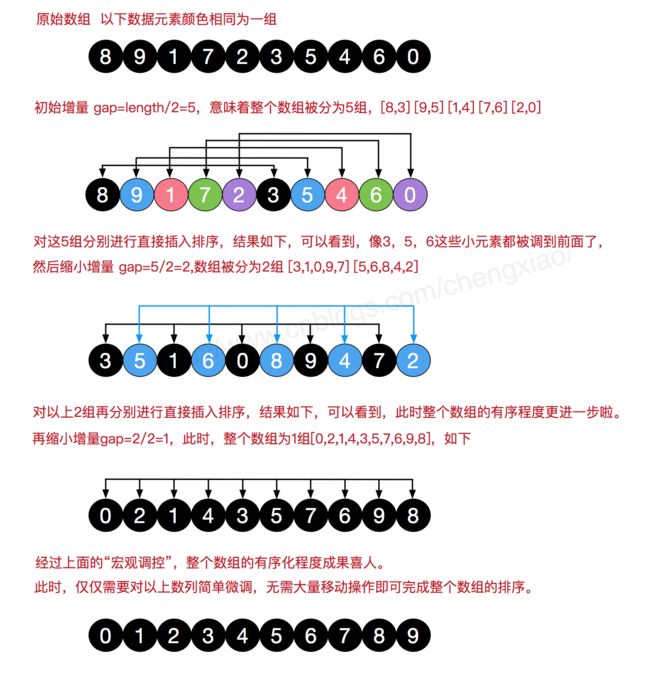
来源: 图解排序算法(二)之希尔排序
复杂度
ShellSort的复杂度分析非常复杂,不同gap序列的设计对应不同的复杂度。
最坏时间复杂度:根据步长序列的不同而不同。已知最好的: O(n (logn) ^2)
最优时间复杂度: O(n)
平均时间复杂度:根据步长序列的不同而不同。
最坏空间复杂度: O(n)
python实现
def ShellSort(arr):
n = len(arr)
# 初始步长
gap = n // 2
while gap >=1 :
for i in range(gap, n):
# 每个步长进行插入排序
temp = arr[i]
# 插入排序
j = i
while j >= gap:
if arr[j - gap] > temp:
arr[j] = arr[j - gap]
j -= gap
else:
break
arr[j] = temp
# 得到新的步长
gap = gap // 2
步长序列
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。
Donald Shell最初建议步长选择为 n/2 并且对步长取半直到步长达到1。虽然这样取可以比 O(n^2)类的算法更好,但这样仍然有减少平均时间和最差时间的余地。
已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…)。这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序要快,甚至在小数组中比快速排序和堆排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
另一个在大数组中表现优异的步长序列是(斐波那契数列除去0和1将剩余的数以黄金分区比的两倍的幂进行运算得到的数列):(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713,…)