常用键值对集合解析(HashMap,LinkedHashMap,TreeMap,HashTable,WeakHashMap,SparseArray,Array)
关于键值对形式储存的常用集合大概有这么几种:
HashMap
LinkedHashMap
TreeMap
HashTable
WeakHashMap
SparseArray
ArrayMap
接下来对这几类常用集合分别简单说明一下其特性:
HashMap:
1.
其底层的实现和储存依赖于数组和链表结构,准确的说是哈希表的拉链结构

每一个结点都是Entry类型,HashMap中Entry在源码中的属性:
final K key;//键
V value;//值
final int hash;//hash值
HashMapEntry next;//单链表中下一个Entry的地址值 Entry数据进行存储的规则:
通过计算元素key的hash值,然后对HashMap中数组长度取余得到该元素存储的位置,计算公式为hash(key)%len。
比如:假设hash(14)=14,hash(30)=30,hash(46)=46,我们分别对len取余,得到 hash(14)%16=14,hash(30)%16=14,hash(46)%16=14,所以key为14、30、46的这三个元素存储在数组下标为14的位置.

从中可以看出,如果有多个元素key的hash值相同的话,后一个元素并不会覆盖上一个元素,而是采取链表的方式,把之后加进来的元素加入链表末尾
2.
其构造函数中比较有特性的一个是含有两个形式参数的构造函数,可以指定初始容量 以及 加载因子;这两个参数的设定对其性能会产生较大影响.
假如我们使用的初始容量为16,加载因子为0.75,那么 当使用容量的负荷承载到12的时候,就会对其容量进行扩展,扩展的大小为原来的两倍,16经过扩展后为32,再扩展则为64,依次类推;
而其扩展的底层代码实现为:

不难看出,假如我们有几十万、几百万条数据,在每次HashMap集合达到承载负荷的零界点后,那么HashMap要存储完这些数据将要不断的扩容,而且在此过程中也需要不断的做hash运算,每次扩容,都是通过遍历读取存储来进行扩容后的数据刷新,而这一过程是极其消耗性能的。
因此较大的加载因子,占用空间小,但会影响到集合的性能以及效率,较小的加载因子将占用更多的空间,但降低冲突的可能性,从而将加快访问和更新的速度。
3.
另外 HashMap的一些特性就是支持异步操作,key,value都可以为null
TreeMap:
基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。 会依据规则对数据进行排序,而排序规则也还可以自己定义,使用构造函数:TreeMap(Comparator c): 构建一个映像树,并且使用特定的比较器对关键字进行排序 。
依据其底层实现TreeMap适用于按自然顺序或自定义顺序遍历键(key)。
而底层的红黑树算法会做另一篇论说,在此不做过多赘述。
HashTable:
HashTable和HashMap还是比较像,但也还是有些不同点,HashTable不支持key和value都为null,每次扩容是*2+1,另外,底层在计算hash值计得到当前存储数据的数组下表时,其算法不及HashMap,HashMap在计算时,还会对哈希值进行移位运算和位运算,使其能更广泛地分散到数组的不同位置。
另外最主要的一个特点是支持同步,但在实际应用的环境里,纯粹的以依靠HashTable本身是不稳妥的,还需要通过自己在相关逻辑上的处理。
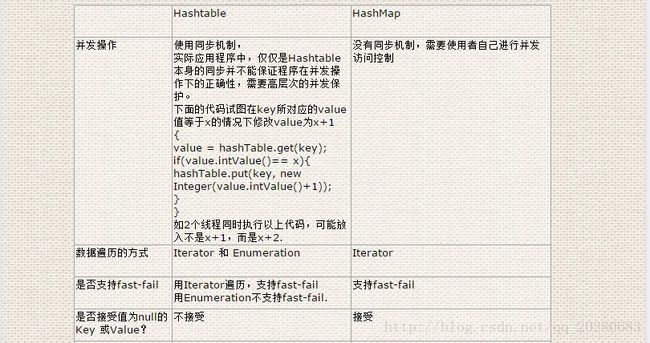

另外,需要明白两个概念:一个是同步,一个是快速失败机制(Fast-Fail)
同步:在执行get,put,remove,size,clear等一次性读写操作时,使用了同步机制,避免了多个线程 同时读写Hashtable。
快速失败机制(Fast-Fail):主要目的在于使iterator遍历数组的线程能及时发现其他线程对Map的修改(如put、remove、clear等),因 此,fast-fail并不能保证所有情况下的多线程并发错误,只能保护iterator遍历过程中的iterator.next()与写并发.
所以,这两个概念是针对于不同情况下的并发访问的处理
WeakHashMap:
其底层的实现和储存依赖于数组和链表结构,不明白的可看上面的HashMap部分的图解。
另外 WeakHashMap也是支持异步操作,key,value都可以为null。
值得注意的是HashMap是强引用,而WeakHashMap是弱引用。
关于四种引用在此也不做过多赘述,想了解的小伙伴可以戳这里–>android开发四种引用的详解。
SparseArray:
简单说来SparseArray是HashMap的升级版,SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
private int[] mKeys;
private Object[] mValues;我们可以看到,SparseArray只能存储key为int类型的数据,同时,SparseArray在存储和读取数据时候,使用的是二分查找法,我们可以看看:
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
...
}也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。
而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显。
满足下面两个条件我们可以使用SparseArray代替HashMap:
● 数据量不大,最好在千级以内
● key必须为int类型,这中情况下的HashMap可以用SparseArray代替
ArrayMap:
SparseArray和ArrayMap都差不多,使用哪个呢?
假设数据量都在千级以内的情况下:
●如果key的类型已经确定为int类型,那么使用SparseArray,因为它避免了自动装箱的过程,如果key为long类型,它还提供了一个LongSparseArray来确保key为long类型时的使用
●如果key类型为其它的类型,则使用ArrayMap