Apache Storm 实时流处理系统通信机制源码分析
我们今天就来仔细研究一下Apache Storm 2.0.0-SNAPSHOT的通信机制。下面我将从大致思想以及源码分析,然后我们细致分析实时流处理系统中源码通信机制研究。
1. 简介
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等;
Worker进程间消息传递机制,消息的接收和处理的大概流程见下图:
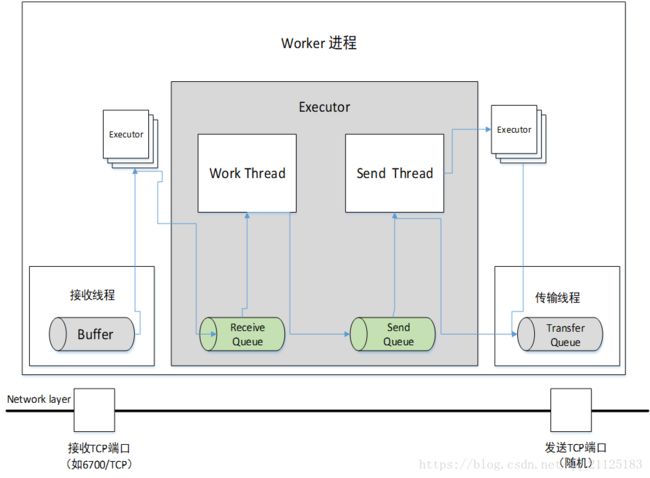
实时流处理系统一般都有一个Worker进程用来分配资源,Worker进程是资源分配的最小单位。每个Worker进程中又包含多个Executor,Executor是用来真正执行Task的组件,里面包含一个工作线程和发送线程。每个Executor都有自己的接收队列和发送队列。
1.每个Worker进程都有一个单独的接受线程监听接收端口。Worker接收线程将收到的消息通过Task编号传递给对应的Executor(一个或则多个)接收队列。Worker接收线程将每个从网络上传来的消息发送到相应的Executor的接收队列中。Executor接收队列存放Worker或者Worker内部其他xecutor发送过来的消息。
2. Executor工作线程从接收队列中拿出数据,然后调用execute方法,发送Tuple到Executor的发送队列。
3. Executor的发送线程从发送队列中获取消息,按照消息目的地址选择发送到Worker的传输队列中或者其他Executor的接收队列中。
4. 最后Worker的发送线程从传输队列中读取消息,然后将Tuple元组发送到网络中。
1.1 具体细节
对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程(对配置的TCP端口supervisor.slots.ports进行监听);
每个executor有自己的sendQueue和receiveQueue。
Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的receiveQueue;
每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在sendQueue中,当executor的sendQueue中的tuple达到一定的阀值,executor的发送线程将批量获取sendQueue中的tuple,并发送到TransferQueue中。
每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的receiveQueue中
TransferQueue的大小由参数topology.transfer.buffer.size来设置。TransferQueue的每个元素实际上代表一个tuple的集合TransferQueue的大小由参数topology.transfer.buffer.size来设置。
executor的sendQueue的大小用户可以自定义配置。
executor的receiveQueue的大小用户可以自定义配置
1.2 Worker进程间通信分析
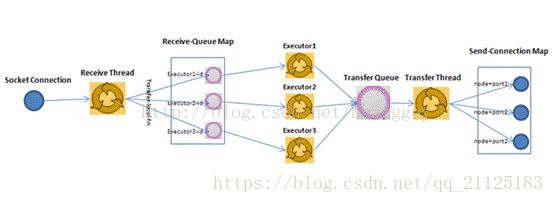
1、 Worker接受线程通过网络接受数据,并根据Tuple中包含的taskId,匹配到对应的executor;然后根据executor找到对应的incoming-queue,将数据存发送到receiveQueue队列中。
2、 业务逻辑执行现成消费receiveQueue的数据,通过调用Bolt的execute(xxxx)方法,将Tuple作为参数传输给用户自定义的方法
3、 业务逻辑执行完毕之后,将计算的中间数据发送给sendQueue队列,当sendQueue中的tuple达到一定的阀值,executor的发送线程将批量获取sendQueue中的tuple,并发送到Worker的TransferQueue中
4、 Worker发送线程消费TransferQueue中数据,计算Tuple的目的地,连接不同的node+port将数据通过网络传输的方式传送给另一个的Worker。
5、 另一个worker执行以上步骤1的操作。
2. Storm 通信机制源码分析
2.1 Spout/Bolt 发送Tuple数据
SpoutOutputCollector 调用emit方法,然后在emit方法中调用sendSpoutMsg方法。我们仔细分析sendSpoutMsg方法,首先根据emit方法中指定的stream和values,调用taskData的taskData.getOutgoingTasks(stream, values)的方法,获取数据要发往哪个TaskID(根据上游spout和下游bolt之间的分组信息)。然后根据这个TaskID,循环遍历将数据封装成TupleImpl。然后outputCollector通过调用executor的ExecutorTransfer类的transfer方法()将tuple添加目标taskId信息,封装成AddressTuple,将数据发送到相应的目标Task。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.executor.spout;
public class SpoutOutputCollectorImpl implements ISpoutOutputCollector {
private final SpoutExecutor executor;
private final Task taskData;
private final int taskId;
private final MutableLong emittedCount;
private final boolean hasAckers;
private final Random random;
private final Boolean isEventLoggers;
private final Boolean isDebug;
private final RotatingMap pending;
@SuppressWarnings("unused")
public SpoutOutputCollectorImpl(ISpout spout, SpoutExecutor executor, Task taskData, int taskId,
MutableLong emittedCount, boolean hasAckers, Random random,
Boolean isEventLoggers, Boolean isDebug, RotatingMap pending) {
this.executor = executor;
this.taskData = taskData;
this.taskId = taskId;
this.emittedCount = emittedCount;
this.hasAckers = hasAckers;
this.random = random;
this.isEventLoggers = isEventLoggers;
this.isDebug = isDebug;
this.pending = pending;
}
@Override
public List emit(String streamId, List BoltOutputCollector 调用emit方法,然后在emit方法中调用BoltEmit方法。我们仔细分析BoltEmit方法,首先根据emit方法中指定的stream和values,调用taskData的taskData.getOutgoingTasks(stream, values)的方法,获取数据要发往哪个TaskID。然后根据这个TaskID,循环遍历将数据封装成TupleImpl。然后再调用executor.getExecutorTransfer().transfer(t, tuple) 将数据发送到相应的目标Task。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.executor.bolt;
public class BoltOutputCollectorImpl implements IOutputCollector {
private static final Logger LOG = LoggerFactory.getLogger(BoltOutputCollectorImpl.class);
private final BoltExecutor executor;
private final Task taskData;
private final int taskId;
private final Random random;
private final boolean isEventLoggers;
private final boolean isDebug;
public BoltOutputCollectorImpl(BoltExecutor executor, Task taskData, int taskId, Random random,
boolean isEventLoggers, boolean isDebug) {
this.executor = executor;
this.taskData = taskData;
this.taskId = taskId;
this.random = random;
this.isEventLoggers = isEventLoggers;
this.isDebug = isDebug;
}
public List emit(String streamId, Collection anchors, List 2.2 ExecutorTransfer类调用transfer方法发送Tuple
ExecutorTransfer类是Executor类的一个成员变量,用来将发送Executor中的Task数据的。在这里,ExecutorTransfer将tuple添加目标task信息,将tuple封装成AddressedTuple。并将封装后的结果AddressedTuple publish到batchTransferQueue队列中。这个batchTransferQueue就说Executor中的发送队列sendQueue。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.executor;
public class ExecutorTransfer implements EventHandler, Callable {
private static final Logger LOG = LoggerFactory.getLogger(ExecutorTransfer.class);
private final WorkerState workerData;
private final DisruptorQueue batchTransferQueue;
private final Map topoConf;
private final KryoTupleSerializer serializer;
private final MutableObject cachedEmit;
private final boolean isDebug;
public ExecutorTransfer(WorkerState workerData, DisruptorQueue batchTransferQueue, Map topoConf) {
this.workerData = workerData;
this.batchTransferQueue = batchTransferQueue;
this.topoConf = topoConf;
this.serializer = new KryoTupleSerializer(topoConf, workerData.getWorkerTopologyContext());
this.cachedEmit = new MutableObject(new ArrayList<>());
this.isDebug = ObjectReader.getBoolean(topoConf.get(Config.TOPOLOGY_DEBUG), false);
}
//4.ExecutorTransfer将tuple添加目标task信息,将tuple封装成AddressedTuple。并将封装后的结果AddressedTuple publish到batchTransferQueue队列中。
// batchTransferQueue也就是Executor的发送队列。
public void transfer(int task, Tuple tuple) {
AddressedTuple val = new AddressedTuple(task, tuple);
if (isDebug) {
LOG.info("TRANSFERRING tuple {}", val);
}
batchTransferQueue.publish(val);
}
@VisibleForTesting
public DisruptorQueue getBatchTransferQueue() {
return this.batchTransferQueue;
}
/**
* 6.ExecutorTransfer的Call方法被调用。batchTransferQueue批量的消费消息
* @return
* @throws Exception
*/
@Override
public Object call() throws Exception {
batchTransferQueue.consumeBatchWhenAvailable(this);
return 0L;
}
public String getName() {
return batchTransferQueue.getName();
}
/**
* 7.相应事件,不断的批量消费batchTransferQueue中的AddressedTuple对象
* @param event
* @param sequence
* @param endOfBatch
* @throws Exception
*/
@Override
public void onEvent(Object event, long sequence, boolean endOfBatch) throws Exception {
ArrayList cachedEvents = (ArrayList) cachedEmit.getObject();
cachedEvents.add(event);
if (endOfBatch) {
//8.调用WorkerState的transfer方法。对AddressedTuple进行序列化操作
workerData.transfer(serializer, cachedEvents);
cachedEmit.setObject(new ArrayList<>());
}
}
}
2.3 Executor 中发送队列达到一定的阈值后,就开始调用WorkerState的transfer方法
Executor是Storm中正在执行任务的线程,Worker进程中会启动所有的Executor。每个Executor都调用execute方法,在Executor方法中的execute线程中。Executor线程 执行execute()方法后,不断的Loop调用executorTransfer的Callable接口。一旦sendQueue buffer达到一定的阈值后,就开始调用ExecutorTransfer的Call方法。
ExecutorTransfer类是Executor类的一个成员变量,用来将发送Executor中的Task数据的(如上节中所述)。当Executor中的sendQueue buffer达到一定的阈值后,就开始调用ExecutorTransfer的Call方法。Executor的batchTransferQueue批量的消费消息,也就是Executor的sendQueue被批量消费消息,不断的批量消费batchTransferQueue中的AddressedTuple对象,最后调用WorkerState的transfer方法,对AddressedTuple进行序列化操作,并且将数据发送到Worker的传输队列中去。
public abstract class Executor implements Callable, EventHandlerExecutorTransfer源码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.executor;
public class ExecutorTransfer implements EventHandler, Callable {
private static final Logger LOG = LoggerFactory.getLogger(ExecutorTransfer.class);
private final WorkerState workerData;
private final DisruptorQueue batchTransferQueue;
private final Map topoConf;
private final KryoTupleSerializer serializer;
private final MutableObject cachedEmit;
private final boolean isDebug;
public ExecutorTransfer(WorkerState workerData, DisruptorQueue batchTransferQueue, Map topoConf) {
this.workerData = workerData;
this.batchTransferQueue = batchTransferQueue;
this.topoConf = topoConf;
this.serializer = new KryoTupleSerializer(topoConf, workerData.getWorkerTopologyContext());
this.cachedEmit = new MutableObject(new ArrayList<>());
this.isDebug = ObjectReader.getBoolean(topoConf.get(Config.TOPOLOGY_DEBUG), false);
}
//4.ExecutorTransfer将tuple添加目标task信息,将tuple封装成AddressedTuple。并将封装后的结果AddressedTuple publish到batchTransferQueue队列中。
// batchTransferQueue也就是Executor的发送队列。
public void transfer(int task, Tuple tuple) {
AddressedTuple val = new AddressedTuple(task, tuple);
if (isDebug) {
LOG.info("TRANSFERRING tuple {}", val);
}
batchTransferQueue.publish(val);
}
@VisibleForTesting
public DisruptorQueue getBatchTransferQueue() {
return this.batchTransferQueue;
}
/**
* 6.ExecutorTransfer的Call方法被调用。batchTransferQueue批量的消费消息
* @return
* @throws Exception
*/
@Override
public Object call() throws Exception {
batchTransferQueue.consumeBatchWhenAvailable(this);
return 0L;
}
public String getName() {
return batchTransferQueue.getName();
}
/**
* 7.相应事件,不断的批量消费batchTransferQueue中的AddressedTuple对象
* @param event
* @param sequence
* @param endOfBatch
* @throws Exception
*/
@Override
public void onEvent(Object event, long sequence, boolean endOfBatch) throws Exception {
ArrayList cachedEvents = (ArrayList) cachedEmit.getObject();
cachedEvents.add(event);
if (endOfBatch) {
//8.调用WorkerState的transfer方法。对AddressedTuple进行序列化操作
workerData.transfer(serializer, cachedEvents);
cachedEmit.setObject(new ArrayList<>());
}
}
} 2.4 WorkerState调用transfer方法
WorkerState是Worker类的一个成员变量,保存着Worker中大量的存在的状态以及对Worker进程通信以及一些操作。这里介绍WorkerState的transfer方法。在WorkerState的Transfer方法中,首先定义了两个局部变量。一个是List
然后Executor方法中不断的对AddressedTuple进行序列化操作,并将要发送到相同的task的AddressedTuple进行打包批量的发送消息。如果需要发送到本地worker的taskid,我们调用WorkerState的transferLocal方法发送到本地,本地发送不需要序列化。需要发送到远程Worker的消息,序列化后进行打包成Map
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.daemon.worker;
public class WorkerState {
........
//12.注册回调函数,WorkerState中的registerCallbacks()方法中注册反序列化连接回调函数。
public void registerCallbacks() {
LOG.info("Registering IConnectionCallbacks for {}:{}", assignmentId, port);
receiver.registerRecv(new DeserializingConnectionCallback(topologyConf,
getWorkerTopologyContext(),
this::transferLocal));
}
//14.调用用第一个步骤声明的transferLocal()方法 在Worker内部本地发送到相应的线程
public void transferLocal(List tupleBatch) {
Map> grouped = new HashMap<>();
for (AddressedTuple tuple : tupleBatch) {
Integer executor = taskToShortExecutor.get(tuple.dest);
if (null == executor) {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
continue;
}
List current = grouped.get(executor);
if (null == current) {
current = new ArrayList<>();
grouped.put(executor, current);
}
current.add(tuple);
}
for (Map.Entry> entry : grouped.entrySet()) {
DisruptorQueue queue = shortExecutorReceiveQueueMap.get(entry.getKey());
if (null != queue) {
queue.publish(entry.getValue());
} else {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
}
}
}
//9.不断的对AddressedTuple进行序列化操作,并将要发送到相同的task的AddressedTuple进行打包批量的发送消息。
// 如果需要发送到本地worker的taskid,我们调用WorkerState的transferLocal方法发送到本地。本地发送不需要序列化
// 需要发送到远程Worker的消息,序列化后进行打包成Map>对象发送到Worker的传输队列中去
public void transfer(KryoTupleSerializer serializer, List tupleBatch) {
if (trySerializeLocal) {
assertCanSerialize(serializer, tupleBatch);
}
List local = new ArrayList<>();
Map> remoteMap = new HashMap<>();
LOG.info("the time of start serializing : {}", System.currentTimeMillis());
for (AddressedTuple addressedTuple : tupleBatch) {
int destTask = addressedTuple.getDest();
if (taskIds.contains(destTask)) {
// Local task
local.add(addressedTuple);
} else {
// Using java objects directly to avoid performance issues in java code
if (! remoteMap.containsKey(destTask)) {
remoteMap.put(destTask, new ArrayList<>());
}
remoteMap.get(destTask).add(new TaskMessage(destTask, serializer.serialize(addressedTuple.getTuple())));
}
}
LOG.info("the time of end serializing : {}", System.currentTimeMillis());
if (!local.isEmpty()) {
transferLocal(local);
}
if (!remoteMap.isEmpty()) {
transferQueue.publish(remoteMap);
}
}
.........
}
2.5 Worker进程发送TaskMessage到相应的Task任务
Worker进程是分配资源的最小单位。这里我们主要分析Worker进程之间的通信过程。Worker的传输线程不断的异步从Worker的传输队列中循环调用,不断的批量消费传输队列中的消息,发送到相应的远程Worker中。这里调用WorkerState的sendTuplesToRemoteWorker方法将(HashMap
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.daemon.worker;
public class Worker implements Shutdownable, DaemonCommon {
.........
public void start() throws Exception {
LOG.info("Launching worker for {} on {}:{} with id {} and conf {}", topologyId, assignmentId, port, workerId,
conf);
// because in local mode, its not a separate
// process. supervisor will register it in this case
// if ConfigUtils.isLocalMode(conf) returns false then it is in distributed mode.
if (!ConfigUtils.isLocalMode(conf)) {
// Distributed mode
SysOutOverSLF4J.sendSystemOutAndErrToSLF4J();
String pid = Utils.processPid();
FileUtils.touch(new File(ConfigUtils.workerPidPath(conf, workerId, pid)));
FileUtils.writeStringToFile(new File(ConfigUtils.workerArtifactsPidPath(conf, topologyId, port)), pid,
Charset.forName("UTF-8"));
}
final Map topologyConf =
ConfigUtils.overrideLoginConfigWithSystemProperty(ConfigUtils.readSupervisorStormConf(conf, topologyId));
List acls = Utils.getWorkerACL(topologyConf);
IStateStorage stateStorage =
ClusterUtils.mkStateStorage(conf, topologyConf, acls, new ClusterStateContext(DaemonType.WORKER));
IStormClusterState stormClusterState =
ClusterUtils.mkStormClusterState(stateStorage, acls, new ClusterStateContext());
Credentials initialCredentials = stormClusterState.credentials(topologyId, null);
Map initCreds = new HashMap<>();
if (initialCredentials != null) {
initCreds.putAll(initialCredentials.get_creds());
}
autoCreds = AuthUtils.GetAutoCredentials(topologyConf);
subject = AuthUtils.populateSubject(null, autoCreds, initCreds);
backpressureZnodeTimeoutMs = ObjectReader.getInt(topologyConf.get(Config.BACKPRESSURE_ZNODE_TIMEOUT_SECS)) * 1000;
Subject.doAs(subject, new PrivilegedExceptionAction
WorkerState调用sendTuplesToRemoteWorker将packets发送到相应的远程Worker中。不断的将数据添加到TransferDrainer贮水池中。 当数据批次到达批次末尾的时候,然后调用TransferDrainer的send方法将数据将数据发送到远程的Worker中去。
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.daemon.worker;
public class WorkerState {
........
/**
* WorkerState调用sendTuplesToRemoteWorker将packets发送到相应的远程Worker中。不断的将数据添加到TransferDrainer贮水池中。
* 当数据批次到达批次末尾的时候,然后调用TransferDrainer的send方法将数据将数据发送到远程的Worker中去。
* @param packets
* @param seqId
* @param batchEnd
*/
public void sendTuplesToRemoteWorker(HashMap> packets, long seqId, boolean batchEnd) {
drainer.add(packets);
if (batchEnd) {
ReentrantReadWriteLock.ReadLock readLock = endpointSocketLock.readLock();
try {
readLock.lock();
drainer.send(cachedTaskToNodePort.get(), cachedNodeToPortSocket.get());
} finally {
readLock.unlock();
}
drainer.clear();
}
}
.........
} TransferDrainer调用Send方法将数据发送到相应的远程Worker进程。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.utils;
public class TransferDrainer {
private Map>> bundles = new HashMap();
private static final Logger LOG = LoggerFactory.getLogger(TransferDrainer.class);
public void add(HashMap> taskTupleSetMap) {
for (Map.Entry> entry : taskTupleSetMap.entrySet()) {
addListRefToMap(this.bundles, entry.getKey(), entry.getValue());
}
}
public void send(Map taskToNode, Map connections) {
HashMap>> bundleMapByDestination = groupBundleByDestination(taskToNode);
for (Map.Entry>> entry : bundleMapByDestination.entrySet()) {
NodeInfo hostPort = entry.getKey();
IConnection connection = connections.get(hostPort);
if (null != connection) {
ArrayList> bundle = entry.getValue();
Iterator iter = getBundleIterator(bundle);
if (null != iter && iter.hasNext()) {
connection.send(iter);
}
} else {
LOG.warn("Connection is not available for hostPort {}", hostPort);
}
}
}
private HashMap>> groupBundleByDestination(Map taskToNode) {
HashMap>> bundleMap = Maps.newHashMap();
for (Integer task : this.bundles.keySet()) {
NodeInfo hostPort = taskToNode.get(task);
if (hostPort != null) {
for (ArrayList chunk : this.bundles.get(task)) {
addListRefToMap(bundleMap, hostPort, chunk);
}
} else {
LOG.warn("No remote destination available for task {}", task);
}
}
return bundleMap;
}
private void addListRefToMap(Map>> bundleMap,
T key, ArrayList tuples) {
ArrayList> bundle = bundleMap.get(key);
if (null == bundle) {
bundle = new ArrayList>();
bundleMap.put(key, bundle);
}
if (null != tuples && tuples.size() > 0) {
bundle.add(tuples);
}
}
private Iterator getBundleIterator(final ArrayList> bundle) {
if (null == bundle) {
return null;
}
return new Iterator () {
private int offset = 0;
private int size = 0;
{
for (ArrayList list : bundle) {
size += list.size();
}
}
private int bundleOffset = 0;
private Iterator iter = bundle.get(bundleOffset).iterator();
@Override
public boolean hasNext() {
return offset < size;
}
@Override
public TaskMessage next() {
TaskMessage msg;
if (iter.hasNext()) {
msg = iter.next();
} else {
bundleOffset++;
iter = bundle.get(bundleOffset).iterator();
msg = iter.next();
}
if (null != msg) {
offset++;
}
return msg;
}
@Override
public void remove() {
throw new RuntimeException("not supported");
}
};
}
public void clear() {
bundles.clear();
}
}
2.6 Worker进程接收从其他Worker进程发送过来的数据
首先Worker进程在初始化的时候。Worker进程会注册相应的回调函数用来接收远程worker注册发送过来的消息。
//11.worker注册相应的回调函数用来接受远程worker发送来的消息。
workerState.registerCallbacks();在workerState的registerCallbacks方法中,它会注册接收数据的回调用函数,并且注册反序列化接口DeserializingConnectionCallback。
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.daemon.worker;
public class WorkerState {
........
//12.注册回调函数,WorkerState中的registerCallbacks()方法中注册反序列化连接回调函数。
public void registerCallbacks() {
LOG.info("Registering IConnectionCallbacks for {}:{}", assignmentId, port);
receiver.registerRecv(new DeserializingConnectionCallback(topologyConf,
getWorkerTopologyContext(),
this::transferLocal));
}
//14.调用用第一个步骤声明的transferLocal()方法 在Worker内部本地发送到相应的线程
public void transferLocal(List tupleBatch) {
Map> grouped = new HashMap<>();
for (AddressedTuple tuple : tupleBatch) {
Integer executor = taskToShortExecutor.get(tuple.dest);
if (null == executor) {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
continue;
}
List current = grouped.get(executor);
if (null == current) {
current = new ArrayList<>();
grouped.put(executor, current);
}
current.add(tuple);
}
for (Map.Entry> entry : grouped.entrySet()) {
DisruptorQueue queue = shortExecutorReceiveQueueMap.get(entry.getKey());
if (null != queue) {
queue.publish(entry.getValue());
} else {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
}
}
}
//9.不断的对AddressedTuple进行序列化操作,并将要发送到相同的task的AddressedTuple进行打包批量的发送消息。
// 如果需要发送到本地worker的taskid,我们调用WorkerState的transferLocal方法发送到本地。本地发送不需要序列化
// 需要发送到远程Worker的消息,序列化后进行打包成Map>对象发送到Worker的传输队列中去
public void transfer(KryoTupleSerializer serializer, List tupleBatch) {
if (trySerializeLocal) {
assertCanSerialize(serializer, tupleBatch);
}
List local = new ArrayList<>();
Map> remoteMap = new HashMap<>();
LOG.info("the time of start serializing : {}", System.currentTimeMillis());
for (AddressedTuple addressedTuple : tupleBatch) {
int destTask = addressedTuple.getDest();
if (taskIds.contains(destTask)) {
// Local task
local.add(addressedTuple);
} else {
// Using java objects directly to avoid performance issues in java code
if (! remoteMap.containsKey(destTask)) {
remoteMap.put(destTask, new ArrayList<>());
}
remoteMap.get(destTask).add(new TaskMessage(destTask, serializer.serialize(addressedTuple.getTuple())));
}
}
LOG.info("the time of end serializing : {}", System.currentTimeMillis());
if (!local.isEmpty()) {
transferLocal(local);
}
if (!remoteMap.isEmpty()) {
transferQueue.publish(remoteMap);
}
}
.........
} 在Worker进程中的反序列化接口类中DeserializingConnectionCallback,对消息进行反序列化,将List
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.messaging;
/**
* A class that is called when a TaskMessage arrives.
*/
public class DeserializingConnectionCallback implements IConnectionCallback, IMetric {
private static final Logger LOG = LoggerFactory.getLogger(DeserializingConnectionCallback.class);
private final WorkerState.ILocalTransferCallback cb;
private final Map conf;
private final GeneralTopologyContext context;
private final ThreadLocal _des =
new ThreadLocal() {
@Override
protected KryoTupleDeserializer initialValue() {
return new KryoTupleDeserializer(conf, context);
}
};
// Track serialized size of messages.
private final boolean sizeMetricsEnabled;
private final ConcurrentHashMap byteCounts = new ConcurrentHashMap<>();
public DeserializingConnectionCallback(final Map conf, final GeneralTopologyContext context, WorkerState.ILocalTransferCallback callback) {
this.conf = conf;
this.context = context;
cb = callback;
sizeMetricsEnabled = ObjectReader.getBoolean(conf.get(Config.TOPOLOGY_SERIALIZED_MESSAGE_SIZE_METRICS), false);
}
//13.当有消息发送到Worker中时。Worker接收线程从接收队列中读取TaskMessage序列化后的数据,然后将其进行反序列化操作。最终得到带有消息头的AddressTuple。
//然后调用回调函数的transfer方法。
@Override
public void recv(List batch) {
KryoTupleDeserializer des = _des.get();
ArrayList ret = new ArrayList<>(batch.size());
LOG.info("the time of start deserializing : {}", System.currentTimeMillis());
for (TaskMessage message: batch) {
Tuple tuple = des.deserialize(message.message());
AddressedTuple addrTuple = new AddressedTuple(message.task(), tuple);
updateMetrics(tuple.getSourceTask(), message);
ret.add(addrTuple);
}
LOG.info("the time of start deserializing : {}", System.currentTimeMillis());
cb.transfer(ret);
}
/**
* Returns serialized byte count traffic metrics.
* @return Map of metric counts, or null if disabled
*/
@Override
public Object getValueAndReset() {
if (!sizeMetricsEnabled) {
return null;
}
HashMap outMap = new HashMap<>();
for (Map.Entry ent : byteCounts.entrySet()) {
AtomicLong count = ent.getValue();
if (count.get() > 0) {
outMap.put(ent.getKey(), count.getAndSet(0L));
}
}
return outMap;
}
/**
* Update serialized byte counts for each message.
* @param sourceTaskId source task
* @param message serialized message
*/
protected void updateMetrics(int sourceTaskId, TaskMessage message) {
if (sizeMetricsEnabled) {
int dest = message.task();
int len = message.message().length;
String key = Integer.toString(sourceTaskId) + "-" + Integer.toString(dest);
byteCounts.computeIfAbsent(key, k -> new AtomicLong(0L)).addAndGet(len);
}
}
}
在WorkerState的TransferLocal()方法中,将AddressedTuple发送到相应的Executor的接收队列中去。
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.daemon.worker;
public class WorkerState {
........
//14.调用用第一个步骤声明的transferLocal()方法 在Worker内部本地发送到相应的线程
public void transferLocal(List tupleBatch) {
Map> grouped = new HashMap<>();
for (AddressedTuple tuple : tupleBatch) {
Integer executor = taskToShortExecutor.get(tuple.dest);
if (null == executor) {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
continue;
}
List current = grouped.get(executor);
if (null == current) {
current = new ArrayList<>();
grouped.put(executor, current);
}
current.add(tuple);
}
for (Map.Entry> entry : grouped.entrySet()) {
DisruptorQueue queue = shortExecutorReceiveQueueMap.get(entry.getKey());
if (null != queue) {
queue.publish(entry.getValue());
} else {
LOG.warn("Received invalid messages for unknown tasks. Dropping... ");
}
}
}
.........
} 2.7 Executor 从本地receiveQueue中消费数据
Executor从本地Executor 接收队列中不断的消费数据。将接收到的ArrayList
public abstract class Executor implements Callable, EventHandler