Spark Streaming实时流处理项目5——Spark Streaming入门
Spark Streaming实时流处理项目1——分布式日志收集框架Flume的学习
Spark Streaming实时流处理项目2——分布式消息队列Kafka学习
Spark Streaming实时流处理项目3——整合Flume和Kafka完成实时数据采集
Spark Streaming实时流处理项目4——实战环境搭建
Spark Streaming实时流处理项目5——Spark Streaming入门
Spark Streaming实时流处理项目6——Spark Streaming实战1
Spark Streaming实时流处理项目7——Spark Streaming实战2
Spark Streaming实时流处理项目8——Spark Streaming与Flume的整合
Spark Streaming实时流处理项目9——Spark Streaming整合Kafka实战
Spark Streaming实时流处理项目10——日志产生器开发并结合log4j完成日志的输出
Spark Streaming实时流处理项目11——综合实战
源码

不同的数据源的数据经过Spark Streaming处理之后将结果输出到外部文件系统。
特点:
- 低延迟
- 能从错误中高效恢复
- 能够运行在成千上百的节点
- 能够和批处理、机器学习、图计算等框架无缝整合。
执行流程图:
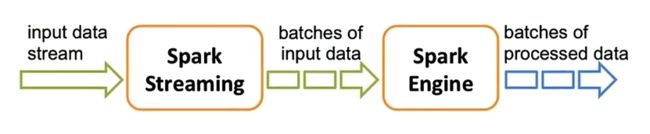
Spark Streaming实际上是做微批处理,并不是真正意义上的实时处理,和Flink不同。
案例:词频统计
package org.apache.spark.examples.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount ")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
} spark-submit的使用:
先开一个客户端运行命令 nc -lk 9999 阻塞着,等一会儿用来发送数据。
在另一个客户端执行命令:
spark-submit --master local[2] --class org.apache.spark.examples.streaming.NetworkWordCount --name NetworkWordCount /soft/spark/examples/jars/spark-examples_2.11-2.2.0.jar hadoop0 9999
使用第一个客户端发送数据,观察词频统计结果。
使用spark-shell来提交:
执行命令 /soft/spark/bin/spark-shell --master local[2] 启动Spark Shell客户端
然后在客户端输入命令:
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("hadoop0",9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
测试的时候使用spark-shell,生产环境下使用spark-submit。
Spark Streaming工作原理:
对于Spark Core它的核心就是RDD,对于Spark Streaming来说,它的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒数将数据流进行批量的划分(val ssc = new StreamingContext(sc, Seconds(1)),这一句程序是用来设置时间间隔的)。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等。
Spark Streaming DStream
1、Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume、ZMQ和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。
2、DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。

3、对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作。
4、还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。