pytorch
https://blog.csdn.net/u012609509/article/details/81203436
Autograd mechanics
- autograd包为张量上的所有操作提供了自动求导机制。
- torch.Tensor是这个包的核心类。如果设置它的属性 .requires_grad为True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用.backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
- 在运行时定义(define-by-run)。意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
- 在概念上,autograd记录了数据需要执行的所有算子,并将其根据顺序放置在一个有向无环图(DAG)=》计算图。
- 从原理来讲,autograd将计算图表示成一种由Function对象组成的图。在前向计算的时候,autograd同时执行算子op对应的计算,并且建立一个表示计算梯度的函数的图。当前向计算完成时,我们将在反向回传过程中评估这个图,并计算梯度。
- 设置requires_grad=False的子图将不用参与梯度计算。
比如下图表示y=x⋅sin(x⋅a+b)的计算图。沿着计算图应用链式求导法则就可以求出梯度。
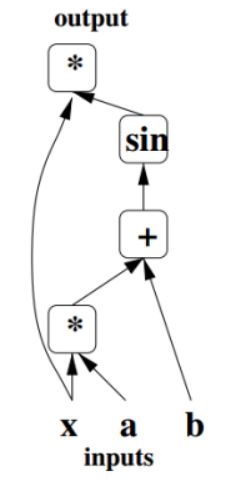
在底层实现中,PyTorch中的计算图的每个结点都是一个Function对象,这个对象可以使用apply()进行操作。
在前向传播过程中,Autograd一边执行着前向计算,一边搭建一个graph,这个graph的结点是用于计算梯度的函数,这些函数结点保存在对应Tensor的.grad_fn中;而反向传播就利用这个graph计算梯度。
torch.nn
- 专门为神经网络设计的模块化接口.
- nn构建于autograd之上,可以用来定义和运行神经网络。
nn.Module:所有网络的基类
torch.nn的核心数据结构是Module,它是一个抽象概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络。无需纠结variable和tensor了,0.4版本已经将两个类彻底合并了。
定义自已的网络:需要继承nn.Module类,并实现forward方法。
-
nn中十分重要的类,包含网络各层的定义及forward方法。nn.Module实现的layer是由class Layer(nn.Module)定义的特殊类,会自动提取可学习参数nn.Parameter。
-
nn.Module的子类函数必须在构造函数中执行父类的构造函数: 自定义层Linear必须继承nn.Module,并且在其构造函数中需调用nn.Module的构造函数,即super(Linear, self).init() 或nn.Module.init(self),推荐使用第一种用法。
-
在构造函数__init__中必须自己定义可学习的参数,并封装成Parameter。
- 一般把网络中具有**可学习参数的层放在构造函数__init__()**中,不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
-
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
- forward函数实现前向传播过程,其输入可以是一个或多个variable,对x的任何操作也必须是variable支持的操作。
- 无需写反向传播函数,因其前向传播都是对variable进行操作,nn.Module能够利用autograd自动实现反向传播,这点比Function简单许多。
-
使用时,直观上可将layer看成数学概念中的函数,调用layer(input)即可得到input对应的结果。它等价于layers.call(input),在__call__函数中,主要调用的是 layer.forward(x),另外还对钩子做了一些处理。所以在实际使用中应尽量使用layer(x)而不是使用layer.forward(x)。
-
Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器,前者会给每个parameter都附上名字,使其更具有辨识度。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)# submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
Modules也可以包含其它Modules,允许使用树结构嵌入他们。你可以将子模块赋值给模型属性。通过上面方式赋值的submodule会被注册。当调用 .cuda() 的时候,submodule的参数也会转换为cuda Tensor。
cuda()
将所有的模型参数(parameters)和buffers赋值GPU
forward(* input)
定义了每次执行的 计算步骤。 在所有的子类中都需要重写这个函数。
train()
将module设置为 training mode。仅仅当模型中有Dropout和BatchNorm是才会有影响。
zero_grad()
将module中的所有模型参数的梯度设置为0.
load_state_dict(state_dict)
将state_dict中的parameters和buffers复制到此module和它的后代中。state_dict中的key必须和 model.state_dict()返回的key一致。 NOTE:用来加载模型参数。
torch.nn.Linear(in_features, out_features, bias=True):定义一个linear
对输入数据做线性变换:y=Ax+b
定义一个linear层,对输入数据做线性变换. (N, in_features) => (N, out_features)
- 输入: (N,in_features) 输出: (N,out_features)
- weight 形状为(out_features x in_features)的模块中可学习的权值
- bias 形状为(out_features)的模块中可学习的偏置。bias 若设置为False,这层不会学习偏置。默认值:True
torch.nn.utils.clip_grad_norm(parameters, max_norm, norm_type=2)
parameters (Iterable[Variable]) – 一个基于变量的迭代器,会进行归一化(原文:an iterable of Variables that will have gradients normalized)
max_norm (float or int) – 梯度的最大范数(原文:max norm of the gradients)
norm_type(float or int) – 规定范数的类型,默认为L2(原文:type of the used p-norm. Can be'inf'for infinity norm)
梯度裁剪:解决梯度消失/爆炸(就是偏导无限接近0,导致长时记忆无法更新):
- 当梯度小于/大于阈值时,更新的梯度为阈值。
- 根据参数的范数来衡量clip_grad_norm()
torch.optim:提供了基于多种epoch数目调整学习率的方法。
- 为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。
构建optimizer对象
optimizer = optimizer()
PyTorch的optimizer默认情况会自动对梯度进行accumulate[4],所以对下一次iteration(一个新的batch),需要对optimizer进行清空操作。
optimizer.step():进行单次优化 (参数更新).
- 所有的optimizer都实现了step()方法。
- 一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数。
https://blog.csdn.net/g11d111/article/details/83035270
https://blog.csdn.net/gdymind/article/details/82224011