【distillation】shrinkTeaNet:Million-scale Lightweight Face Recognition via Shrinking T-S Networks
论文完整题目:shrinkTeaNet:Million-scale Lightweight Face Recognition via Shrinking Teacher-Student Networks
论文链接:https://arxiv.org/abs/1905.10620v1
作者的动机:性能好的人脸识别网络由于其庞大的参数和复杂的网络结构比较困难,作者想要得到一个小型但是精度又还可以与大网络差不多的小网络模型。然后作者就提出了ShrinkTeaNet框架,同时引入了一种新的loss函数:Angular Distillation Loss。
作者做的贡献主要有以下几点:
1)提出了Angular Distillation Loss,与L2 loss相比较,Angular的限制更加“softer”,使得student网络更加灵活的翻译嵌入层的信息;此外,因为从teacher继承的采样分布可以帮助student网络更加鲁棒的使用学到的信息,甚至是目标类别发生改变的时候;
2)提出了一个新的shrinkTeaNet框架,可以有效的在每个阶段蒸馏teacher的信息;
3)评估结果显示了小尺度和大尺度基准上都有提升;
作者提出的方法:
作者先引入蒸馏过程当中最关心的两个问题:
1)如何描述被蒸馏的知识;2)如何更好的在teacher网络和student网络之间有效的迁移信息。
在teacher(T)网络中![]() ,S网络中
,S网络中![]() ,代表输入图像
,代表输入图像![]() 隐射到高位嵌入式空间,函数
隐射到高位嵌入式空间,函数![]() 和函数
和函数![]() 有
有![]() 个子函数
个子函数![]() i和
i和![]() i:公式如下:
i:公式如下:

![]() :代表输入图像;
:代表输入图像;![]() 和
和![]() 分别代表T网络与S网络的参数,模型蒸馏的目标就是将T的知识蒸馏到有限容量的S模型中,可以使S可以学习到T网络的潜在领域;通常达到这种目的需要S在学习过程中由T监督,然后一步步的比较他们二者的输出。
分别代表T网络与S网络的参数,模型蒸馏的目标就是将T的知识蒸馏到有限容量的S模型中,可以使S可以学习到T网络的潜在领域;通常达到这种目的需要S在学习过程中由T监督,然后一步步的比较他们二者的输出。

![]() 是分别是T网络和S的转换函数,
是分别是T网络和S的转换函数,![]() 代表了转换特征的差值,通过最小化这个差值
代表了转换特征的差值,通过最小化这个差值![]() ,可以将T网络信息传递给S网络,使得T和S可以嵌入类似的潜在域;
,可以将T网络信息传递给S网络,使得T和S可以嵌入类似的潜在域;
接下来就该关心如何设计使得这两部分挑选出有用的信息,然后无损的传递这些信息;
3.1 从T的超空间蒸馏知识

表1为之前的研究方法;
Softmax Loss Revisit
常用的分类loss函数:softmax loss,对每张图的公式如下:
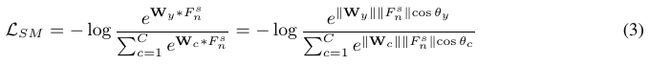
![]() 代表类别数量,
代表类别数量,![]() 代表输入图像正确类别的标签,特征
代表输入图像正确类别的标签,特征![]() 和权重Wc,角度变成唯一的分类标准,若权重Wc作为类别c的代表,loss最小化意味着每个类别样例要求分布在类别代表拍的四周,那么类别代表就有最小的角度差距(minimal angular difference)。这在测试过程中,在输入图像特征提取和每个类别的代表使用决定它们输入同一个类别;
和权重Wc,角度变成唯一的分类标准,若权重Wc作为类别c的代表,loss最小化意味着每个类别样例要求分布在类别代表拍的四周,那么类别代表就有最小的角度差距(minimal angular difference)。这在测试过程中,在输入图像特征提取和每个类别的代表使用决定它们输入同一个类别;
pytorch代码:
#前向计算得到feature
pre_S = self.model_mobile(imgs)#这块不是提取的图像的特征,而是加入了fc层,预测出相应类别
#然后和标签进行loss计算(网络结构中self.fc = Linear(512, class_num),前向计算中最后一句:out = self.fc(out))
#进行softmax loss计算
conf.ce_loss = CrossEntropyLoss()
loss_softmax = conf.ce_loss(pre_S,labels)
在编码过程中,开始时直接使用了:
torch.nn.LogSoftmax()最后通过读别人的博客才理解:crossEntropyloss()是softmax和负对数损失的结合,所以直接使用了crossEntropyloss;
Feature Direction as Distilled Knowledge
angular distillation loss:
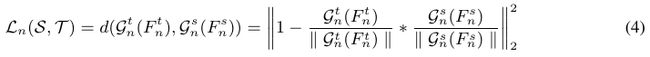
pytorch 代码:
提取每层特征的方法参考:https://mp.csdn.net/postedit/95316328
然后对于angular distillation loss的蒸馏编码:
def forward(self, featureT, featureS):
conv1 = torch.nn.Conv2d(featureS.shape[1], featureT.shape[1],
kernel_size=3,stride=1,padding=1).cuda()
featureS = conv1(featureS)
self.norm1_S = torch.nn.functional.normalize(featureS)
self.norm1_T = torch.nn.functional.normalize(featureT)
loss = 1-self.norm1_S*self.norm1_T
loss = torch.norm(loss).pow(2)
return loss通过公式(4)作者提出,迁移的知识就是嵌入特征的方向,换句话说:就是![]() 和
和![]() 拥有相似的方向,这样在潜在的空间中,特征就可以以不同的半径分布在不同的超空间。最终的目标函数:
拥有相似的方向,这样在潜在的空间中,特征就可以以不同的半径分布在不同的超空间。最终的目标函数:
![]()
The Transformation Functions:
这块作者为了降低迁移信息的损失,将student网络输出的特征通过1*1的卷积转换成与teacher网络输出特征相同的通道,这样Student网络就可以充分使用Teacher网络的信息;
Geometric Interpretation
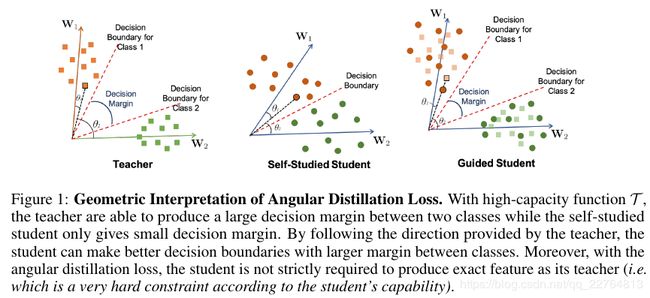
图1中,teacher网络可以更好的找到一个decision margin,但是student网络找到了一个很小的decision margin,当student在teacher的指导下,也找到了一个更好的decision boundaries;
3.2 Intermediate Distilled Knowledge
3.3 Shrinking Teacher-Student Network for Face Recognition
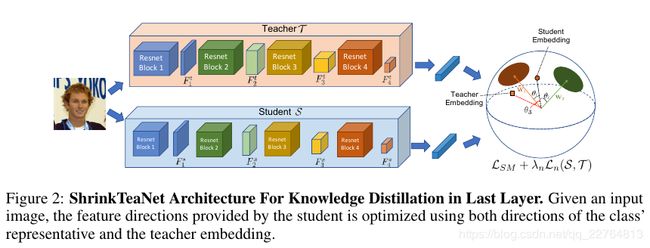
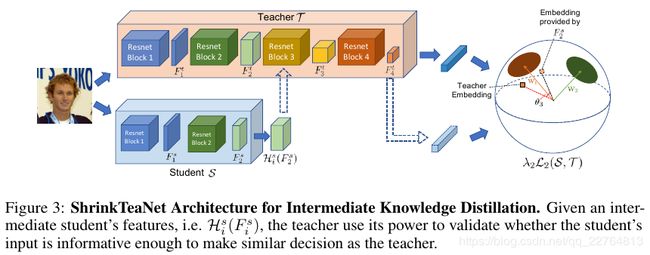
图二是ShrinkTeaNet从最后阶段蒸馏知识,而图三是ShrinkTeaNet从中间层蒸馏知识;图中是参差结构的网络结构,T和S分别有4个参差块,当输入训练数据集:![]() ,N个人脸图像Ij,相关的标签是yi;
,N个人脸图像Ij,相关的标签是yi;
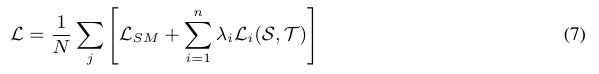
(7)式中lmda是参数用于控制蒸馏知识迁移到不同的参差块中;,为了保证计算的进行,student网络输出的特征会使用1*1卷积将维度调整到与teacher网络输出特征维度一样尺寸;
4.实验结果:
4.2 Implementation Details
teacher网络结构使用resnet90,student网络使用MobileNetV1,MobileNetV2,MobileFaceNet,MobileFacenet-R,网络结构版本与MobileFacenet相似,只是每个参差模块的feature size与teacher的特征size相等;
深度学习平台:MAXNET,使用Angular Distillation loss 时lamda n = 1;使用L2 loss时lamda n=0.001;当在中间层时,lamda i = (lamda i+1)/2.
4.3 Evaluation Results
small-scale Protocols.
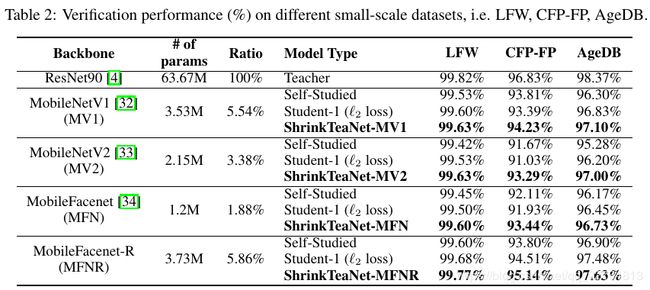
从表2中发现使用L2loss大多数模型性能能够提升,但是也有一些结果变差的情况,
以下是测试结果:
Megaface Protocols.

IJB-B and IJB-C Protocols:
