pytorch pruning训练自己的数据库(流程+BUG调试)
环境要求
pytorch 0.1
0.2版本会有问题,解决方法后文会介绍。
如何查看版本?在终端输入:
python
import torch
torch.version
数据集制作
本文代码使用的数据加载方法是datasets.ImageFolder,它要求数据集不同类别的图片放在不同文件夹下,文件格式如下:

将自己的数据集做成图中的形式,即可。
运行过程
train
python finetune.py –train –train_path path_to_your_dataset/train/ –test_path path_to_your_dataset/test/
这里会去掉VGG的后三层fc,而根据自己的num_class训练新的fc层,总共迭代20个epoch。
prune
python finetune.py –prune –train_path path_to_your_dataset/train/ –test_path path_to_your_dataset/test/
这里会开始对filter进行剪枝,每次剪512个filter,每次剪完都会迭代10个epoch以恢复模型的能力;然后继续下一次剪枝,直至将VGG模型的2/3的filter剪掉;最后进行15个epoch以得到最终的剪枝模型。
ps:这里的512是自己设定的,论文中是1,但每次只剪1个filter太慢,所以设定为512,加快剪枝过程。
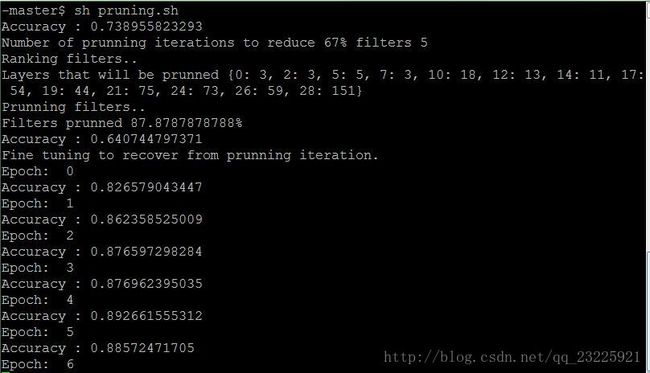
上图是prune的过程,其中Layers that will be prunned是每一层剪枝的filter数量,可以看到更深的层减的更多。
以下是在调试过程中遇到的问题:
问题调试
1. ImportError cv2

解决办法:
将import cv2放在import torch前面
参考网址
2. RuntimeError THCTensorCopy.c:18
/b/wheel/pytorch-src/torch/lib/THCUNN/ClassNLLCriterion.cu:52: void cunn_ClassNLLCriterion_updateOutput_kernel(Dtype , Dtype , Dtype , long , Dtype *, int, int, int, int) [with Dtype = float, Acctype = float]: block: [0,0,0], thread: [0,0,0] Assertion t >= 0 && t < n_classes failed.
RuntimeError: cuda runtime error (59) : device-side assert triggered at /b/wheel/pytorch-src/torch/lib/THC/generic/THCTensorCopy.c:18
因为我的图片class为10类,而代码中只有2类,所以要将finetune.py中的self.classifier 的最后输出改为10
python
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(25088, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 10))
3. out of memory
THCudaCheck FAIL file=/tmp/luarocks_cutorch-scm-1-3726/cutorch/lib/THC/generic/THCStorage.cu line=66 error=2 : out of memory
![]()
解决办法1:换一颗GPU
在代码中修改:
import torch
torch.cuda.set_device(id)
或者在终端命令中加入:CUDA_VISIBLE_DEVICES=1
解决办法2:减小batchsize
参考网址
4. RuntimeError: arguments are located on different GPUs
![]()
RuntimeError: arguments are located on different GPUs at /b/wheel/pytorch-src/torch/lib/THC/generated/../generic/THCTensorMathPointwise.cu:214
这种情况是属于一部分数据在CPU上,一部分数据在GPU上,导致无法进行pointwise add。
具体出错代码如下:
values = torch.sum((activation * grad), dim = 0).\ sum(dim=2).sum(dim=3)[0, :, 0, 0].data \ #将activation与grad做点乘
# Normalize the rank by the filter dimensions
if activation_index not in self.filter_ranks:
self.filter_ranks[activation_index] = \
torch.FloatTensor(activation.size(1)).zero_().cuda() #得到和activation.size(1)一样长的一维0向量
self.filter_ranks[activation_index] += values #将算得的values赋给ranks
可以看到,values上icpu上的数据,而filter_ranks有.cuda(),所以是GPU上的数据,所以会出错,解决办法是将:
values = torch.sum((activation * grad), dim = 0).\ sum(dim=2).sum(dim=3)[0, :, 0, 0].data
换成GPU上的数据:
values = torch.sum((activation * grad), dim = 0).\ sum(dim=2).sum(dim=3)[0, :, 0, 0].data.cuda()
pytorch0.2版本兼容问题
1. keepdim
pytorch2版本中的sum函数多了keepdim这个参数,所以需要在每一个sum函数里加上这个参数。
values = \
torch.sum((activation * grad), dim = 0).\
sum(dim=2).sum(dim=3)[0, :, 0, 0].data
换成
values = \
torch.sum((activation * grad), dim = 0,keepdim=True).\
sum(dim=2,keepdim=True).sum(dim=3,keepdim=True)[0, :, 0, 0].data
2 bias
pytorch2中conv2d()的init函数的输入最后一项bias是bool型,而conv.bias是float tensor,所以源代码中将bias = conv.bias肯定会出错,解决办法就是去掉这一项:(原文中有两处需要删掉)
new_conv = \
torch.nn.Conv2d(in_channels = conv.in_channels, \
out_channels = conv.out_channels - 1,
kernel_size = conv.kernel_size, \
stride = conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups,
bias = conv.bias)
改为:
new_conv = \
torch.nn.Conv2d(in_channels = conv.in_channels, \
out_channels = conv.out_channels - 1,
kernel_size = conv.kernel_size, \
stride = conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups)