java使用freemark实现word(.doc/.docx)/pdf生成和导出(附源码和模板文件)
freemark生成word/pdf
- 一、 背景
- 二、实现的技术选型以及遇到的坑
- 三、最终的效果
- 2.1 `.doc` word效果展示
- 2.1 `.docx` word效果展示
- 2.2 docx word转pdf效果展示
- 三、准备工作及代码实现
- 3.1后缀为.doc的word生成
- 3.2 后缀为.docx的word生成,word转pdf
- 四、相关源码资源下载
- 中间参考链接
一、 背景
工作需要,需要实现word和pdf的生成,其中包含:word模板生成,.docx转pdf生成,由于.docx是以xml方式读取,.doc是以二进制读取所以,目前我还没有找到好的方案可以实现.doc转pdf,如果网友有什么好的解决方案,请留言告知不胜感激,由于是第一次玩这个所以不是很熟悉,网上以统百度,各种尝试各种采坑,。网上这样的例子很多,但是坑也很多。我踩了很多坑,特此记载,避免自己和同等需求的网友再次踩坑。如果看完博客还有什么不懂的可以加群一起探讨:821605718, 或者加我个人qq: 2768861003
二、实现的技术选型以及遇到的坑
- 网上有人推荐
html、css实现,样式复杂实现麻烦,且兼容性不好,不考虑 apache poi实现,我一开始采用的这个,网上下载了个demo,跑起来了也成功导出了,欣喜若狂,开始用在自己的项目上,结果有一个类一直报错,具体报啥错,我不记得了,谷歌了很久才发现是版本问题,目前项目框架里面用的excel导出是基于easypoi的easypoi基于apache poi 3.7,而apache poi3.7 是阉割版的,不支持word/pdf导出。我尝试排除依赖无果后,遂放弃apache poi。- 朋友推荐用
freemark,我试了一下,虽然中间也遇到很坑,word的模板替换问题,中文不展示问题等。但最终一一解决之后,效果确实很好,不论是导出xml的.docx,还是导出二进制的doc都挺好,而且也可以直接在word上面调整好模板,替换相关参数即可实现变量word/pdf导出。很是方便。就它了,如果大家还有什么推荐,请留言告知。感激不尽。
三、最终的效果
2.1 .doc word效果展示
.doc原始模板

.doc word替换后模板模板
2.1 .docx word效果展示
转化前


转化后
2.2 docx word转pdf效果展示

三、准备工作及代码实现
maven导入freemark、xdocreport的包
如果只需要导出word(
.doc)的话,只需要一个freemark的包就可以了,如果有pdf导出的需要的话加后面3个包
<dependency>
<groupId>org.freemarkergroupId>
<artifactId>freemarkerartifactId>
<version>2.3.20version>
dependency>
<dependency>
<groupId>fr.opensagres.xdocreportgroupId>
<artifactId>org.apache.poi.xwpf.converter.coreartifactId>
<version>1.0.4version>
dependency>
<dependency>
<groupId>fr.opensagres.xdocreportgroupId>
<artifactId>org.apache.poi.xwpf.converter.pdfartifactId>
<version>1.0.4version>
dependency>
<dependency>
<groupId>fr.opensagres.xdocreportgroupId>
<artifactId>fr.opensagres.xdocreport.itext.extensionartifactId>
<version>1.0.4version>
dependency>
3.1后缀为.doc的word生成
1. 创建word.doc,设置word模板,另存为word2003.xml。便于在xml中替换相关变量
注意:这里有坑(坑多的想放弃,刚开始做的时候,主要是没做过,手动捂脸):
(1)如果word模板是之前编辑好,并且保存了的,注意word模板必须是.doc。不能是.docx。LZ亲测,注意别踩坑,原因上面已经讲了,.doc是二进制读取的,word2007以后支持doc和docx。据说word2003不支持.docx。我电脑没装word2003。所以没有测试是否支持。
(2) word模板千万不要提前替换好相关变量,再修改后缀为xml。LZ亲测,替换后很可能你打开xml,你的变量就不再一起了,需要重新找到再次
替换。
(3)wps另存的时候没有word2003.xml。LZ亲测:我特地去激活了我电脑上的windows。。。


3. 重命名word后缀为.xml,使用notpad++打开该xml文件notepad++使用xmlTools格式化xml
4. 替换相关参数并保存
(1)替换普通变量:ctrl+f 找到我们需要替换的关键字:title–> 替换为–> ${title}
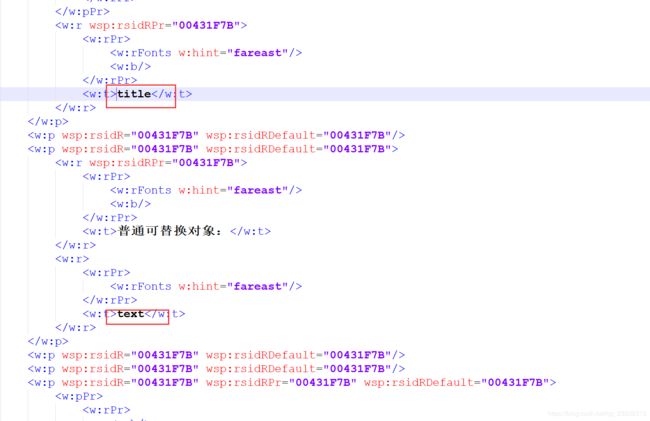

(2) 循环替换变量:例如我们这里的table
ctrl + f 搜索:w:tr, 注意:
- 这里的
w:tr就代表我们table里面的每一行,这里我们是要从第二行开始循环,第一行是表头. - 所以我们找到第二个
<#list itemList as l>, 在后面加闭合标签:。这里的list表示循环,listItem表示java代码需要注入的参数,as l表示别名,用于指定需要循环的变量 - 这里面需要循环的变量修改为:
${l.item}、${l.name}以此类推。

- 这里的坑: 标签展开后会发现部分变量被切割了,不知道什么原因,这里我们直接把切割的变量恢复就成


(3) 替换图片,转成xml后,图片是base64编码。我们直接删除编码,放置变量即可。这种一堆字母的就是图片了,删除掉,替换为你想要替换的图片变量:${base64_image}。
这里的坑: >${base64_image}<中间不要有任何空格


5. 修改后缀为freemark可识别的后缀.ftl
6. 代码解析ftl文件为word.doc
package com.ads4each.adspilot.utils;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import sun.misc.BASE64Encoder;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class FtlToWordUtil {
private static Logger logger = LoggerFactory.getLogger(FtlToWordUtil.class);
/**
* 图片转base64的字符串
*
* @param imageAbsolutePath 图片路径
* @return String
*/
public static String imageToBase64Str(String imageAbsolutePath) {
InputStream is = null;
byte[] data = null;
try {
is = new FileInputStream(imageAbsolutePath);
data = new byte[is.available()];
is.read(data);
is.close();
} catch (Exception e) {
e.printStackTrace();
return null;
}
BASE64Encoder encoder = new BASE64Encoder();
return encoder.encode(data);
}
/**
* 初始化配置文件
*
* @param folderPath 生成word的文件夹路径
* @return Configuration
*/
private static Configuration initConfiguration(String folderPath) {
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
try {
configuration.setDirectoryForTemplateLoading(new File(folderPath));
} catch (IOException e) {
logger.error("初始化configuration失败,路径不存在:{}", folderPath);
e.printStackTrace();
}
return configuration;
}
/**
* 将数据写入word,并输出到指定路径
*
* @param dataMap 需要写入word的数据
* @param ftlFolderPath 指定的word模板所在的文件夹
* @param tempName 指定的word模板名称
* @param outputFilePath 输出路径
*/
public static boolean createWord(Map<String, Object> dataMap, String ftlFolderPath, String tempName, String outputFilePath) {
logger.info("开始创建word到本地");
boolean result = false;
Configuration configuration = initConfiguration(ftlFolderPath);
Template t = null;
try {
t = configuration.getTemplate(tempName);
t.setEncoding("utf-8");
} catch (IOException e) {
logger.error("在路径:{}里找不到:{}", ftlFolderPath, tempName);
e.printStackTrace();
}
File outFile = new File(outputFilePath);
Writer out = null;
FileOutputStream fos = null;
try {
fos = new FileOutputStream(outFile);
OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");
out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile)));
t.process(dataMap, out);
out.close();
fos.close();
result = true;
logger.info("word创建成功");
} catch (FileNotFoundException e) {
logger.error("文件不存在:{}", outFile);
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
logger.error("未知的编码格式");
e.printStackTrace();
} catch (TemplateException e) {
logger.error("模板异常");
e.printStackTrace();
} catch (IOException e) {
logger.error("IO异常");
e.printStackTrace();
}
return result;
}
/**
* 导出word文档,响应到请求端
*
* @param tempName,要使用的模板
* @param docName,导出文档名称
* @param dataMap,模板中变量数据
* @param resp,HttpServletResponse
*/
public static boolean exportDoc(String folderPath, String tempName, String docName, Map<?, ?> dataMap, HttpServletResponse resp) {
boolean status = false;
Configuration configuration = initConfiguration(folderPath);
ServletOutputStream sos = null;
InputStream fin = null;
if (resp != null) {
resp.reset();
}
Template t = null;
try {
// tempName.ftl为要装载的模板
t = configuration.getTemplate(tempName);
t.setEncoding("utf-8");
} catch (IOException e) {
e.printStackTrace();
}
// 输出文档路径及名称 ,以临时文件的形式导出服务器,再进行下载
String name = folderPath + "temp" + (int) (Math.random() * 100000) + ".doc";
File outFile = new File(name);
Writer out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile), "utf-8"));
status = true;
} catch (Exception e1) {
e1.printStackTrace();
}
try {
t.process(dataMap, out);
out.close();
} catch (TemplateException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
fin = new FileInputStream(outFile);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 文档下载
resp.setCharacterEncoding("utf-8");
resp.setContentType("application/msword");
try {
docName = new String(docName.getBytes("UTF-8"), "ISO-8859-1");
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
resp.setHeader("Content-disposition", "attachment;filename=" + docName + ".doc");
try {
sos = resp.getOutputStream();
} catch (IOException e) {
e.printStackTrace();
}
byte[] buffer = new byte[512]; // 缓冲区
int bytesToRead = -1;
// 通过循环将读入的Word文件的内容输出到浏览器中
try {
while ((bytesToRead = fin.read(buffer)) != -1) {
sos.write(buffer, 0, bytesToRead);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fin != null)
try {
fin.close();
} catch (IOException e) {
e.printStackTrace();
}
if (sos != null)
try {
sos.close();
} catch (IOException e) {
e.printStackTrace();
}
if (outFile != null)
outFile.delete(); // 删除临时文件
}
return status;
}
public static void main(String[] args) throws IOException {
Map<String, Object> dataMap = new HashMap<>();
List<Map<String, Object>> list = new ArrayList<>(16);
for (int i = 0; i < 10; i++) {
Map<String, Object> itemMap = new HashMap<>(16);
itemMap.put("item", i+1);
itemMap.put("name", "name"+(i+1));
itemMap.put("age", "age"+ (i+1));
itemMap.put("adress", "adress" + (i+1));
list.add(itemMap);
}
dataMap.put("itemList", list);
dataMap.put("title", "我是标题");
dataMap.put("text", "我是被替换后的对象");
//图片转码
dataMap.put("base64_image",imageToBase64Str("C:\\Users\\suzan\\Desktop\\newPic.jpg"));
createWord(dataMap, "C:\\Users\\suzan\\Desktop\\", "test.ftl", "C:\\Users\\suzan\\Desktop\\test.docx");
System.out.println("模板生成成功");
}
}
3.2 后缀为.docx的word生成,word转pdf
以下思路参考链接: https://blog.csdn.net/juncai91/article/details/70146364 ,感谢原文作者,不过在实现的路上还是踩了一些坑。
(1) msword或者wps创建好word模板,模板里面的中文设置为宋体,保存为.docx后缀
(2)将word后缀修改为zip
(3)解压zip文件,找到word文件夹里面的document.xml文件
(4)将需要替换的变量用${}包裹起来,循环遍量用<#list itemList as l>包裹,循环替换变量用${l.xx}(同上面doc的xml文件替换变量时方法一致)
(5)代码实现word生成word转pdf
这里需要注意的问题:
- 我在document.xml里面没有找到base64编码的图片,所以我不是很清楚如何替换图片,如果有知道的请告知一下。
- 原文作者并没有提供循环替换变量的功能,我结合.doc的实现猜想测试了一下,实现了循环录入数据的功能
- 我参考的这个作者在代码里面并没有设置编码,我这里加上了编码设置
- 该作者里面的中文需要设置模板的时候设置为宋体,否则无法在pdf上展示,在实现的时候需要注意一下
- word转pdf的时候,即使在window上面中文正常展示了,但是linux(我是ubuntu)无法展示,解决方案我后面也一并给出了
解决word转pdf后,linux下pdf中文不展示的问题:
方案1:将中文字体打包上线到linux目录下面(不推荐)
参考链接: https://blog.csdn.net/wwuPower/article/details/81676025
- window系统中的字体路径: C:\Windows\Fonts 下,将字体打包为zip
- 上传字体到linux上/usr/share/fonts
- 目录下,在其中建立了一个win目录,用于存放上传的中文字体,
再执行命令:
fc-cache -fv
方案2:linux命令行安装中文字体(我采用的这个)
参考链接:解决ubuntu下pdf中文不显示或乱码问题
sudo apt-get install xpdf-chinese-simplified
sudo apt-get install xpdf-chinese-traditional
sudo apt-get install poppler-data
代码实现:
package com.ads4each.adspilot.utils;
import com.lowagie.text.DocumentException;
import com.lowagie.text.Font;
import com.lowagie.text.pdf.BaseFont;
import fr.opensagres.xdocreport.itext.extension.font.IFontProvider;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import org.apache.poi.xwpf.converter.pdf.PdfConverter;
import org.apache.poi.xwpf.converter.pdf.PdfOptions;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.awt.*;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
import java.util.zip.ZipOutputStream;
public class WordAndPdfUtil {
private static Logger logger = LoggerFactory.getLogger(WordAndPdfUtil.class);
public static void main(String[] args) throws Exception {
String basePath = "C:\\Users\\suzan\\Desktop\\";
Map<String, Object> dataMap = new HashMap<>();
List<Map<String, Object>> list = new ArrayList<>(16);
for (int i = 0; i < 10; i++) {
Map<String, Object> itemMap = new HashMap<>(16);
itemMap.put("item", i+1);
itemMap.put("name", "name"+(i+1));
itemMap.put("age", "age"+ (i+1));
itemMap.put("adress", "adress" + (i+1));
list.add(itemMap);
}
dataMap.put("itemList", list);
dataMap.put("title", "我是docx的标题");
dataMap.put("text", "我是被替换后的docx的对象");
makeWord(basePath, "wordToPdf.zip", "wordToPdf.docx", dataMap);
wordToPdf(basePath + "wordToPdf.docx",
basePath + "wordToPdf.pdf");
}
/**
* 生成word
* @param basePath word所在的文件夹
* @param wordInZipName word改为zip后word的名字
* @param wordOutName word输出的名称
* @param dataMap word里面需要替换的参数
*/
public static boolean makeWord(String basePath, String wordInZipName, String wordOutName, Map<String,Object> dataMap) {
logger.info("开始创建word");
boolean result = false;
/** 指定输出word文件的路径 **/
String outFilePath = basePath + "data.xml";
File docXmlFile = new File(outFilePath);
try {
/** 初始化配置文件 **/
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
/** 加载文件 **/
configuration.setDirectoryForTemplateLoading(new File(basePath));
/** 加载模板 **/
Template template = configuration.getTemplate("document.xml");
template.setEncoding("utf-8");
logger.info("初始化配置文件,成功, 开始渲染数据");
/**数据渲染到word**/
FileOutputStream fos = new FileOutputStream(docXmlFile);
OutputStreamWriter oWriter = new OutputStreamWriter(fos, "UTF-8");
Writer out = new BufferedWriter(oWriter, 10240);
logger.info("数据写入xml中");
template.process(dataMap, out);
out.close();
fos.close();
logger.info("数据写入xml完毕, 开始读取zip文件");
/**读取压缩文件**/
ZipInputStream zipInputStream = wrapZipInputStream(new FileInputStream(new File(basePath + wordInZipName)));
/**压缩文件写入到目标路径**/
File wordOutFile = new File(basePath + wordOutName);
logger.info("创建新的目录:{}", basePath + wordOutName);
wordOutFile.createNewFile();
ZipOutputStream zipOutputStream = wrapZipOutputStream(new FileOutputStream(wordOutFile));
String itemName = "word/document.xml";
/**替换参数**/
logger.info("替换相关参数");
replaceItem(zipInputStream, zipOutputStream, itemName, new FileInputStream(docXmlFile));
logger.info("word生成成功");
result = true;
} catch (IOException e) {
logger.error("IO异常:{}", e.getMessage());
e.printStackTrace();
} catch (TemplateException e) {
logger.error("模板异常:{}", e.getMessage());
e.printStackTrace();
} finally {
docXmlFile.delete();
}
return result;
}
/**
* word转pdf
* @param wordPath word的路径
* @param pdfPath pdf的路径
*/
public static boolean wordToPdf(String wordPath, String pdfPath){
logger.info("wordPath:{}, pdfPath:{}", wordPath, pdfPath);
boolean result = false;
try {
logger.info("开始word转pdf");
XWPFDocument document=new XWPFDocument(new FileInputStream(new File(wordPath)));
File outFile=new File(pdfPath);
outFile.getParentFile().mkdirs();
OutputStream out=new FileOutputStream(outFile);
PdfOptions options= PdfOptions.create();
PdfConverter.getInstance().convert(document,out,options);
logger.info("word转pdf成功");
result = true;
}
catch ( Exception e) {
e.printStackTrace();
logger.error("word转pdf失败");
}
return result;
}
/**
* 替换某个 item,
* @param zipInputStream zip文件的zip输入流
* @param zipOutputStream 输出的zip输出流
* @param itemName 要替换的 item 名称
* @param itemInputStream 要替换的 item 的内容输入流
*/
public static void replaceItem(
ZipInputStream zipInputStream,
ZipOutputStream zipOutputStream,
String itemName,
InputStream itemInputStream){
if(null == zipInputStream){return;}
if(null == zipOutputStream){return;}
if(null == itemName){return;}
if(null == itemInputStream){return;}
ZipEntry entryIn;
try {
while((entryIn = zipInputStream.getNextEntry())!=null)
{
String entryName = entryIn.getName();
ZipEntry entryOut = new ZipEntry(entryName);
// 只使用 name
zipOutputStream.putNextEntry(entryOut);
// 缓冲区
byte [] buf = new byte[8*1024];
int len;
if(entryName.equals(itemName)){
// 使用替换流
while((len = (itemInputStream.read(buf))) > 0) {
zipOutputStream.write(buf, 0, len);
}
} else {
// 输出普通Zip流
while((len = (zipInputStream.read(buf))) > 0) {
zipOutputStream.write(buf, 0, len);
}
}
// 关闭此 entry
zipOutputStream.closeEntry();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//e.printStackTrace();
close(itemInputStream);
close(zipInputStream);
close(zipOutputStream);
}
}
/**
* 包装输入流
*/
public static ZipInputStream wrapZipInputStream(InputStream inputStream){
ZipInputStream zipInputStream = new ZipInputStream(inputStream);
return zipInputStream;
}
/**
* 包装输出流
*/
public static ZipOutputStream wrapZipOutputStream(OutputStream outputStream){
ZipOutputStream zipOutputStream = new ZipOutputStream(outputStream);
return zipOutputStream;
}
private static void close(InputStream inputStream){
if (null != inputStream){
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static void close(OutputStream outputStream){
if (null != outputStream){
try {
outputStream.flush();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
四、相关源码资源下载
下载链接:https://download.csdn.net/download/qq_23832313/11049341
因为我是公司项目,也没来得及整理一个demo,所以,我把自己用到的类,和文件打包,大家自行导入使用,应该可以直接跑通。我都测试了一遍,如果还是有啥问题的话,直接找我,qq:2768861003, 或者加群: 821605718(高级java学习交流群).
另外:上传文件到到csdn,要求最低必须要1积分,其实我代码已经都在上面了,非必须其实直接copy本博客代码即可。
这里有个坑,注意一下,如果下载了源码直接运行报一下错误,不要慌,是因为你的idea设置了httpServeltRequest设置了项目启动才加载的机制,改成compile就成


中间参考链接
基于freemarker ,xdocreport生成word,pdf