Python3网络爬虫:使用Beautiful Soup爬取小说
本文是http://blog.csdn.net/c406495762/article/details/71158264的学习笔记
作者:Jack-Cui
博主链接:http://blog.csdn.net/c406495762
运行平台: OSX
Python版本: Python3.x
IDE: pycharm
一、Beautiful Soup简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
二、Beautiful Soup学习
在这里推荐 Python爬虫利器二之Beautiful Soup的用法 ,和官方文档相似,但是内容作了精简.
另附上 官方文档 的链接
三、实战
小说网站-笔趣看:
URL:http://www.biqukan.com/
以该小说网为例,爬取《神墓》
整体思路:
1. 选择神墓小说某一章节,检查,找到正文部分的TAG
2. 尝试使用BeautifulSoup打印出该章节正文部分内容
3. 从索引爬取全部的章节的url,用for循环打印
4. 结合3、2并将2的打印部分换成写入文件
具体步骤:
1. 选择《神墓》小说第一章,检查,找到正文部分的html标签
链接url:http://www.biqukan.com/3_3039/1351331.html

发现小说正文部分所在标签是:
2. 尝试使用BeautifulSoup打印出该章节正文部分内容
from urllib import request
from bs4 import BeautifulSoup
import os
def download_specified_chapter(chapter_url,header,coding,chapter_name=None):
#先生成一个request对象,传入url和headers
download_req = request.Request(chapter_url,headers=header)
#通过指定urlopen打开request对象中的url网址,并获得对应内容
response = request.urlopen(download_req)
#获取页面的html
download_html = response.read().decode(coding, 'ignore')
#获取html的bs
origin_soup = BeautifulSoup(download_html, 'lxml')
#获取小说正文部分
content=origin_soup.find(id='content', class_='showtxt')
#经打印,发现文本中有众多的\xa0(在html中是 ),并且没有换行,
print(repr(content.text))
#整理小说格式,将\xa0替换成回车
# html中的 ,在转换成文档后,变成\xa0
txt=content.text.replace('\xa0'*8,'\n')
print(txt)
if __name__=="__main__":
target_url='http://www.biqukan.com/3_3039/1351331.html'
header = {
'User-Agent':'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
download_specified_chapter(target_url,header,'gbk')结果如图:

3. 从索引爬取全部的章节的url,用for循环打印
索引的url:http://www.biqukan.com/3_3039/
检查后发现 执行结果: 4.结合3、2并将2的打印部分换成写入文件 结果如图: txt截图: 这样就大功告成 ^_^
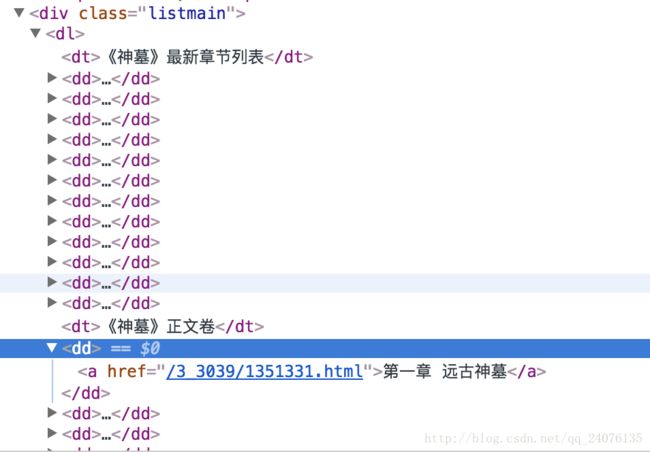
我们所需要的章节的url,在中的 标签中,并且是在
尝试用for循环打印:
from urllib import request
from bs4 import BeautifulSoup
if __name__ == "__main__":
index_url = "http://www.biqukan.com/3_3039/"
header={
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
#指定url,header生成request
url_req = request.Request(index_url,headers=header)
#打开url,并获得请求内容response
response = request.urlopen(url_req)
#读取response的内容,用gbk解码,得到html内容
html = response.read().decode('gbk', 'ignore')
#用BeautifulSoup处理得到的网页html
html_soup = BeautifulSoup(html,'lxml')
# index = BeautifulSoup(str(html_soup.find_all('div', class_='listmain')),'lxml')
# print(html_soup.find_all(['dd', ['dt']]))
#判断是否找到了《神墓》正文卷
body_flag = False for element in html_soup.find_all(['dd', ['dt']]):
if element.string == '《神墓》正文卷':
body_flag = True
if body_flag is True and element.name == 'dd':
chapter_name = element.string
chapter_url = "http://www.biqukan.com"+element.a.get('href')
print(" {} 链接:{}".format(chapter_name,chapter_url))
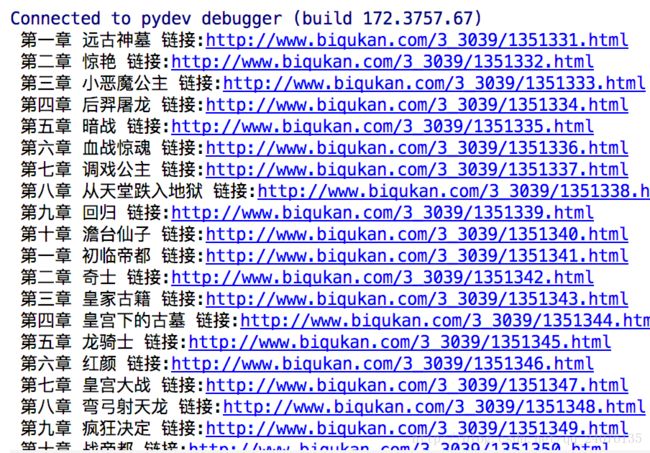
由步骤3 获得章节的url,再由步骤2 根据url,获得正文部分,两相结合,再不断地将内容写入文件中.
代码如下:from urllib import request
from bs4 import BeautifulSoup
def download_specified_chapter(chapter_url, header, coding, chapter_name=None):
#先生成一个request对象,传入url和headers
download_req = request.Request(chapter_url,headers=header)
#通过指定urlopen打开request对象中的url网址,并获得对应内容
response = request.urlopen(download_req)
#获取页面的html
download_html = response.read().decode(coding, 'ignore')
#获取html的bs
origin_soup = BeautifulSoup(download_html, 'lxml')
#获取小说正文部分
content=origin_soup.find(id='content', class_='showtxt')
#整理小说格式,将\xa0替换成回车
# html中的 ,在转换成文档后,变成\xa0
txt=content.text.replace('\xa0'*8,'\n')
# 将获得的正文 写入txt
print("正在下载 {} 链接:{}".format(chapter_name,chapter_url))
with open('《神墓》.txt','a') as f:
if chapter_name is None:
f.write('\n')
else :
f.write('\n'+chapter_name+'\n')
f.write(txt)
if __name__ == "__main__":
index_url = "http://www.biqukan.com/3_3039/"
header={
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/'
'535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
}
#指定url,header生成request
url_req = request.Request(index_url,headers=header)
#打开url,并获得请求内容response
response = request.urlopen(url_req)
#读取response的内容,用gbk解码,得到html内容
html = response.read().decode('gbk', 'ignore')
#用BeautifulSoup处理得到的网页html
html_soup = BeautifulSoup(html,'lxml')
# index = BeautifulSoup(str(html_soup.find_all('div', class_='listmain')),'lxml')
# print(html_soup.find_all(['dd', ['dt']]))
#判断是否找到了《神墓》正文卷
body_flag = False
for element in html_soup.find_all(['dd', ['dt']]):
if element.string == '《神墓》正文卷':
body_flag = True
#从《神墓》正文卷 之后的dd就是顺序的章节目录
if body_flag is True and element.name == 'dd':
chapter_name = element.string
chapter_url = "http://www.biqukan.com"+element.a.get('href')
download_specified_chapter(chapter_url, header, 'gbk', chapter_name)

