Python3网络爬虫:Scrapy入门实战之爬取动态网页图片
Python版本: python3.+
运行环境: Mac OS
IDE: pycharm
- 一 前言
- 二 Scrapy相关方法介绍
- 1 搭建Scrapy项目
- 2 shell分析
- 三 网页分析
- 四 Scrapy程序编写
- 1 spider测试
- 2 item编写
- 3 Pipelines编写
- 4 spider完整代码实现
- 5 settings 汇总
- 五 小结
一 、前言
上一篇博客写了一下自己理解的Scrapy的框架,其中有包括Scrapy的工作流程和安装方法。学有所用,这次就进行一个实战来磨练磨练,从理论到实践。
二 、Scrapy相关方法介绍
1、 搭建Scrapy项目
在成功安装Scrapy的前提下,在终端进入你想要搭建Scrapy项目的路径下。
比如我想在/Users/hyl/Documents/scrapy/下搭建一个名为unsplash的工程:
1. 在终端输入 cd /Users/hyl/Documents/scrapy
2. 再输入scrapy startproject unsplash
scrapy startproject是固定命令,后面的unsplash是自己想起的工程名字。
该命令将会创建包含下列内容的scrapy目录:
unsplash/
|- scrapy.cfg
|- unsplash/
|- __init__.py
|- items.py
|- middlewares.py
|- pipelines.py
|- settings.py
|- spiders/
|- __init__.py
|- ...这些文件分别是:
- scrapy.cfg: 项目的配置文件;
- unsplash/: 该项目的python模块。之后将在此加入Spider代码;
- unsplash/items.py: 项目中的item文件;
- unsplash/middlewares .py:项目中的中间件;
- unsplash/pipelines.py: 项目中的pipelines文件;
- unsplash/settings.py: 项目的设置文件;
- unsplash/spiders/: 放置spider代码的目录。
2、 shell分析
在编写程序之前,我们可以使用Scrapy内置的Scrapy shell,分析下目标网页,为后编写梳理思路。
Scrapy shell是一个交互终端,我们能够在不启动spider的情况下尝试及调试我们的爬取代码。
该终端是用来测试 XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编spider的时候,该终端提供了交互性测试我们的表达式代码的功能,免去了每次修改后运行spider的麻烦。
概括一下,就是我们现在shell上把XPath和CSS表达式的查找代码测试成功,为了之后在写Spider能够避免每次执行后再修改这样繁琐的操作。
以https://unsplash.com/为例:
1. 在终端键入命令
scrapy shell 'https://unsplash.com/' --nolog
--nolog 的作用是不显示日志信息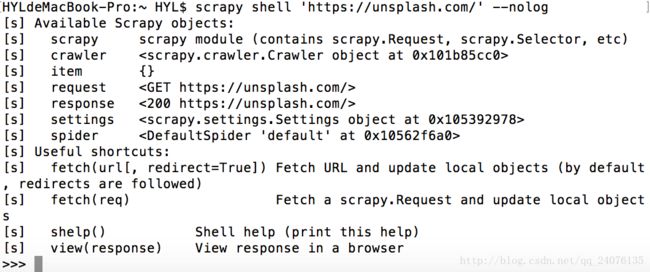
其中
2. Scrapy shell中,我们可以通过如下指令打印网页的body信息:
response.body在终端里现实的内容,是未经过排版的,因此,想要通过response.body来查找元素,是非常困难的。所以,可以在网页上,通过审查元素的方式进行分析:
再通过response.xpath()来验证我们xpath查找语句是否正确
xpath的语法,可以在http://www.w3school.com.cn/xpath/xpath_syntax.asp了解
response.xpath('//a[@title="View the photo By Meduana"]')但是因为该网站是动态加载的,所以我们不能够通过这种方式来获取我们想要的信息。
三 、网页分析
此次要爬取的网站url:https://unsplash.com/
对该网站的分析,已在之前的一篇博客Python3网络爬虫:requests爬取动态网页内容有描述,在此,仅做一个总结:
- 应对该网站的反爬虫机制: 在headers中加上
authorization字段,该字段的值,需要通过抓包来获取。 - json源地址:
http://unsplash.com/napi/feeds/home - 图片下载地址:
https://unsplash.com/photos/*****/download?force=true
其中*为图片id
四 、Scrapy程序编写
1、 spider测试
在unsplash/unsplash目录下创建unsplash_spider.py文件,编写代码如下:
#-*- coding:utf-8 -*-
import scrapy,json
class UnsplashSpider(scrapy.Spider):
name = 'unsplash'
start_urls = ['http://unsplash.com/napi/feeds/home']
def parse(self, response):
try:
dic = json.loads(response.text)
photos = dic['photos']
print("next_page: %s" % dic['next_page'])
for photo in photos :
print("id: %s " % photo['id'])
except:
print('error')
- name:自己定义的内容,在运行工程的时候需要用到的标识;
- start_urls:开始爬取的url,需要注意的是这个url链接需要放在列表里;
- def parse(self, response) :请求分析的回调函数,如果不定义start_requests(self),获得的请求直接从这个函数分析;
然后在终端键入 Scrapy shell命令
scrapy crawl comic --nolog但是会发现不显示任何值,就连error的错误打印都没有。
这是因为scrapy在调用默认的start_requests发方法时,就已经报错了。其原因是发送的headers 中 没有authorization的字段,导致的爬取失败,没有收到response。
这时,我们为了避免每次都单独设置headers,在setting中设置
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '********************'
}再重新访问,这样,就能得到我们想要的数据了。
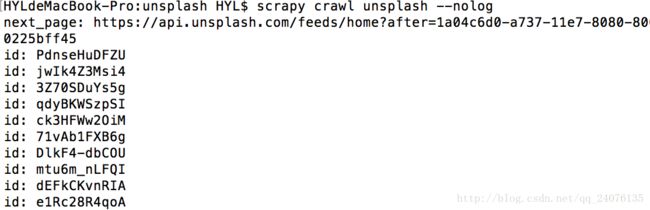
2、 item编写
我们将上面获得的id和next_page存入自己编写的item类中,以便于 通过item pipeline来下载图片
import scrapy
class UnsplashItem(scrapy.Item):
image_ids = scrapy.Field()
image_urls = scrapy.Field()
image_paths = scrapy.Field()- image_ids:图片的id
- image_urls:图片的下载地址
- image_paths:图片的本地保存路径
3、 Pipelines编写
当在程序返回一个item的时候,scrapy会自动调用pipeline,所以我们可以把下载图片的功能放在pipeline中去
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from unsplash import settings
import os
import requests
class UnsplashPipeline(object):
def process_item(self, item, spider):
if 'image_urls' in item:
if not os.path.exists(settings.IMAGES_STORE):
os.makedirs(settings.IMAGES_STORE)
for index in range(len(item['image_urls'])):
image_url = item['image_urls'][index]
image_id = item['image_ids'][index]
file_name = image_id+'.jpg'
file_path = settings.IMAGES_STORE+'/'+file_name
# 保存图片
with open(file_path,'wb') as f:
response = requests.get(image_url,headers = settings.DEFAULT_REQUEST_HEADERS,verify=False)
for chunk in response.iter_content(1024):
if not chunk:
break
f.write(chunk)
item['image_paths'] = [file_path]
return item
其中使用到了settings的IMAGES_STORE参数。对settings,可以理解为存放scrapy engine全局变量的文件。
所以在使用IMAGES_STORE之前,要在settings中加上
IMAGES_STORE = './images'而想要scrapy engine 能够辨别我们写的UnsplashPipeline类,同样要在setting中加上
ITEM_PIPELINES = {
'unsplash.pipelines.UnsplashPipeline': 1,
}4、 spider完整代码实现
我们要在spider做的事,就是分析通过request请求获取的response,来获得我们想要的数据,保存到我们定义好的item中。
在scrapy engine的支持下,我们返回的item,会自动去调用pipelines;而返回的request请求,若不指定回调函数,则会自动去调用默认的parse方法。
#-*- coding:utf-8 -*-
import scrapy,json
from unsplash.items import UnsplashItem
class UnsplashSpider(scrapy.Spider):
name = 'unsplash'
start_urls = ['http://unsplash.com/napi/feeds/home']
# def start_requests(self):
# yield scrapy.Request(self.start_urls[0],callback=self.parse)
def __init__(self):
self.download_format = 'https://unsplash.com/photos/{}/download?force=true'
def parse(self, response):
# try:
dic = json.loads(response.text)
photos = dic['photos']
next_page = dic['next_page']
# print("next_page: %s" % dic['next_page'])
for photo in photos :
image_id = photo['id']
item = UnsplashItem()
item['image_ids'] = [image_id]
image_url = self.download_format.format(image_id)
item['image_urls'] = [image_url]
yield item
yield scrapy.Request(url=next_page,callback=self.parse)
# except:
# print('error')
关于yield起到的作用,例如for循环下的yield item,可以理解成:类似于return的作用,该函数会返回一个item,但是并不会中断该方法,而是会继续执行下面的代码。更详细的解释。可以参阅
Python yield 使用浅析
5、 settings 汇总
# -*- coding: utf-8 -*-
# Scrapy settings for unsplash project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'unsplash'
SPIDER_MODULES = ['unsplash.spiders']
NEWSPIDER_MODULE = 'unsplash.spiders'
IMAGES_STORE = './images'
ITEM_PIPELINES = {
'unsplash.pipelines.UnsplashPipeline': 1,
}
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*********',
}
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- BOT_NAME:自动生成的内容,根名字;
- SPIDER_MODULES:自动生成的内容;
- NEWSPIDER_MODULE:自动生成的内容;
- ROBOTSTXT_OBEY:自动生成的内容,是否遵守robots.txt规则,这里选择不遵守;
- ITEM_PIPELINES:定义item的pipeline;
- IMAGES_STORE:图片存储的根路径;
- DOWNLOAD_DELAY:下载延时,这里使用250ms延时
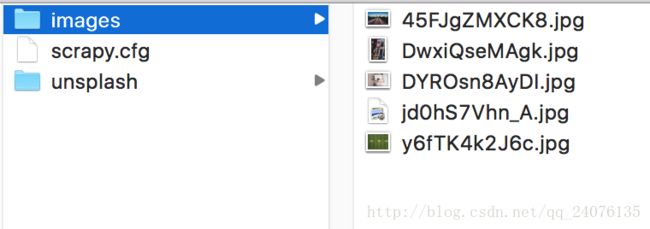
完成上述代码的编写,再在终端下执行命令
scrapy crawl unsplash这里可以不关闭日志,来判断爬虫运行是否正常。
让爬虫跑一段时间吧。之后,那些精美的图片就已经保存到你的电脑上了 ^_^
五 小结
本次实例只是为了来加深对scrapy的理解。其中对图片的下载,使用的是requests库的方法。并不是scrapy自带的ImagesPipeline方法。关于对ImagesPipeline的使用,应该会在下篇博客介绍吧。
这个demo我也上传到Github上了。URL:https://github.com/hylusst/unsplash_spider-scrapy-
本文仅就我对scrapy的理解进行实践,如有错误,望指正 。