light GBM的使用
目录
载入数据
参数设置
训练模型
交叉验证
Early Stop
预测
GOSS
EFB
light GBM是微软开源的一种使用基于树的学习算法的梯度提升框架。
文档地址:官方文档
源码地址:github
中文文档地址:中文文档
论文地址:lightgbm-a-highly-efficient-gradient-boosting-decision-tree
参考博客:lightgbm,xgboost,gbdt的区别与联系 - Mata - 博客园
LightGBM原理之论文详解 - u010242233的博客 - CSDN博客
载入数据
LGB可以load以下类型数据。
- libsvm/tsv/csv/txt format file
- NumPy 2D array(s), pandas DataFrame, H2O DataTable’s Frame, SciPy sparse matrix
- LightGBM binary file
load libsvm text file or a LightGBM binary file
train_data = lgb.Dataset('train.svm.bin')load a numpy array
data = np.random.rand(500, 10) # 500 entities, each contains 10 features
label = np.random.randint(2, size=500) # binary target
train_data = lgb.Dataset(data, label=label)load a scpiy.sparse.csr_matrix array
csr = scipy.sparse.csr_matrix((dat, (row, col)))
train_data = lgb.Dataset(csr)Saving Dataset into a LightGBM binary file(可以提高运行速度)
train_data = lgb.Dataset('train.svm.txt')
train_data.save_binary('train.bin')Create validation data:
validation_data = train_data.create_valid('validation.svm')在构建数据集时,需要把类别转化为整型数。同时设置free_raw_data=True( 默认是true).
参数设置
一般会初始化权重
w = np.random.rand(500, )
train_data = lgb.Dataset(data, label=label, weight=w)
booster参数
param = {'num_leaves':31, 'num_trees':100, 'objective':'binary'} param['metric'] = 'auc' or 'binary_logloss'
核心参数
config︎, default ="", type = string, aliases:config_file- path of config file
- Note: can be used only in CLI version
task︎, default =train, type = enum, options:train,predict,convert_model,refit, aliases:task_typetrain, for training, aliases:trainingpredict, for prediction, aliases:prediction,testconvert_model, for converting model file into if-else format, see more information in IO Parametersrefit, for refitting existing models with new data, aliases:refit_tree- Note: can be used only in CLI version; for language-specific packages you can use the correspondent functions
objective︎, default =regression, type = enum, options:regression,regression_l1,huber,fair,poisson,quantile,mape,gammma,tweedie,binary,multiclass,multiclassova,xentropy,xentlambda,lambdarank, aliases:objective_type,app,application- regression application
regression_l2, L2 loss, aliases:regression,mean_squared_error,mse,l2_root,root_mean_squared_error,rmseregression_l1, L1 loss, aliases:mean_absolute_error,maehuber, Huber lossfair, Fair losspoisson, Poisson regressionquantile, Quantile regressionmape, MAPE loss, aliases:mean_absolute_percentage_errorgamma, Gamma regression with log-link. It might be useful, e.g., for modeling insurance claims severity, or for any target that might be gamma-distributedtweedie, Tweedie regression with log-link. It might be useful, e.g., for modeling total loss in insurance, or for any target that might be tweedie-distributed
binary, binary log loss classification (or logistic regression). Requires labels in {0, 1}; seecross-entropyapplication for general probability labels in [0, 1]- multi-class classification application
multiclass, softmax objective function, aliases:softmaxmulticlassova, One-vs-All binary objective function, aliases:multiclass_ova,ova,ovrnum_classshould be set as well
- cross-entropy application
xentropy, objective function for cross-entropy (with optional linear weights), aliases:cross_entropyxentlambda, alternative parameterization of cross-entropy, aliases:cross_entropy_lambda- label is anything in interval [0, 1]
lambdarank, lambdarank application- label should be
inttype in lambdarank tasks, and larger number represents the higher relevance (e.g. 0:bad, 1:fair, 2:good, 3:perfect) - label_gain can be used to set the gain (weight) of
intlabel - all values in
labelmust be smaller than number of elements inlabel_gain
- label should be
- regression application
boosting︎, default =gbdt, type = enum, options:gbdt,gbrt,rf,random_forest,dart,goss, aliases:boosting_type,boostgbdt, traditional Gradient Boosting Decision Tree, aliases:gbrtrf, Random Forest, aliases:random_forestdart, Dropouts meet Multiple Additive Regression Treesgoss, Gradient-based One-Side Sampling
data︎, default ="", type = string, aliases:train,train_data,train_data_file,data_filename- path of training data, LightGBM will train from this data
- Note: can be used only in CLI version
valid︎, default ="", type = string, aliases:test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames- path(s) of validation/test data, LightGBM will output metrics for these data
- support multiple validation data, separated by
, - Note: can be used only in CLI version
num_iterations︎, default =100, type = int, aliases:num_iteration,n_iter,num_tree,num_trees,num_round,num_rounds,num_boost_round,n_estimators, constraints:num_iterations >= 0- number of boosting iterations
- Note: internally, LightGBM constructs
num_class * num_iterationstrees for multi-class classification problems
learning_rate︎, default =0.1, type = double, aliases:shrinkage_rate,eta, constraints:learning_rate > 0.0- shrinkage rate
- in
dart, it also affects on normalization weights of dropped trees
num_leaves︎, default =31, type = int, aliases:num_leaf,max_leaves,max_leaf, constraints:num_leaves > 1- max number of leaves in one tree
tree_learner︎, default =serial, type = enum, options:serial,feature,data,voting, aliases:tree,tree_type,tree_learner_typeserial, single machine tree learnerfeature, feature parallel tree learner, aliases:feature_paralleldata, data parallel tree learner, aliases:data_parallelvoting, voting parallel tree learner, aliases:voting_parallel- refer to Parallel Learning Guide to get more details
num_threads︎, default =0, type = int, aliases:num_thread,nthread,nthreads,n_jobs- number of threads for LightGBM
0means default number of threads in OpenMP- for the best speed, set this to the number of real CPU cores, not the number of threads (most CPUs use hyper-threading to generate 2 threads per CPU core)
- do not set it too large if your dataset is small (for instance, do not use 64 threads for a dataset with 10,000 rows)
- be aware a task manager or any similar CPU monitoring tool might report that cores not being fully utilized. This is normal
- for parallel learning, do not use all CPU cores because this will cause poor performance for the network communication
device_type︎, default =cpu, type = enum, options:cpu,gpu, aliases:device- device for the tree learning, you can use GPU to achieve the faster learning
- Note: it is recommended to use the smaller
max_bin(e.g. 63) to get the better speed up - Note: for the faster speed, GPU uses 32-bit float point to sum up by default, so this may affect the accuracy for some tasks. You can set
gpu_use_dp=trueto enable 64-bit float point, but it will slow down the training - Note: refer to Installation Guide to build LightGBM with GPU support
seed︎, default =None, type = int, aliases:random_seed,random_state- this seed is used to generate other seeds, e.g.
data_random_seed,feature_fraction_seed, etc. - by default, this seed is unused in favor of default values of other seeds
- this seed has lower priority in comparison with other seeds, which means that it will be overridden, if you set other seeds explicitly
- this seed is used to generate other seeds, e.g.
learning control参数
max_depth︎, default =-1, type = int- limit the max depth for tree model. This is used to deal with over-fitting when
#datais small. Tree still grows leaf-wise < 0means no limit
- limit the max depth for tree model. This is used to deal with over-fitting when
min_data_in_leaf︎, default =20, type = int, aliases:min_data_per_leaf,min_data,min_child_samples, constraints:min_data_in_leaf >= 0- minimal number of data in one leaf. Can be used to deal with over-fitting
min_sum_hessian_in_leaf︎, default =1e-3, type = double, aliases:min_sum_hessian_per_leaf,min_sum_hessian,min_hessian,min_child_weight, constraints:min_sum_hessian_in_leaf >= 0.0- minimal sum hessian in one leaf. Like
min_data_in_leaf, it can be used to deal with over-fitting
- minimal sum hessian in one leaf. Like
bagging_fraction︎, default =1.0, type = double, aliases:sub_row,subsample,bagging, constraints:0.0 < bagging_fraction <= 1.0- like
feature_fraction, but this will randomly select part of data without resampling - can be used to speed up training
- can be used to deal with over-fitting
- Note: to enable bagging,
bagging_freqshould be set to a non zero value as well
- like
bagging_freq︎, default =0, type = int, aliases:subsample_freq- frequency for bagging
0means disable bagging;kmeans perform bagging at everykiteration- Note: to enable bagging,
bagging_fractionshould be set to value smaller than1.0as well
bagging_seed︎, default =3, type = int, aliases:bagging_fraction_seed- random seed for bagging
feature_fraction︎, default =1.0, type = double, aliases:sub_feature,colsample_bytree, constraints:0.0 < feature_fraction <= 1.0- LightGBM will randomly select part of features on each iteration if
feature_fractionsmaller than1.0. For example, if you set it to0.8, LightGBM will select 80% of features before training each tree - can be used to speed up training
- can be used to deal with over-fitting
- LightGBM will randomly select part of features on each iteration if
feature_fraction_seed︎, default =2, type = int- random seed for
feature_fraction
- random seed for
early_stopping_round︎, default =0, type = int, aliases:early_stopping_rounds,early_stopping- will stop training if one metric of one validation data doesn’t improve in last
early_stopping_roundrounds <= 0means disable
- will stop training if one metric of one validation data doesn’t improve in last
max_delta_step︎, default =0.0, type = double, aliases:max_tree_output,max_leaf_output- used to limit the max output of tree leaves
<= 0means no constraint- the final max output of leaves is
learning_rate * max_delta_step
lambda_l1︎, default =0.0, type = double, aliases:reg_alpha, constraints:lambda_l1 >= 0.0- L1 regularization
lambda_l2︎, default =0.0, type = double, aliases:reg_lambda,lambda, constraints:lambda_l2 >= 0.0- L2 regularization
min_gain_to_split︎, default =0.0, type = double, aliases:min_split_gain, constraints:min_gain_to_split >= 0.0- the minimal gain to perform split
drop_rate︎, default =0.1, type = double, aliases:rate_drop, constraints:0.0 <= drop_rate <= 1.0- used only in
dart - dropout rate: a fraction of previous trees to drop during the dropout
- used only in
max_drop︎, default =50, type = int- used only in
dart - max number of dropped trees during one boosting iteration
<=0means no limit
- used only in
skip_drop︎, default =0.5, type = double, constraints:0.0 <= skip_drop <= 1.0- used only in
dart - probability of skipping the dropout procedure during a boosting iteration
- used only in
xgboost_dart_mode︎, default =false, type = bool- used only in
dart - set this to
true, if you want to use xgboost dart mode
- used only in
uniform_drop︎, default =false, type = bool- used only in
dart - set this to
true, if you want to use uniform drop
- used only in
drop_seed︎, default =4, type = int- used only in
dart - random seed to choose dropping models
- used only in
top_rate︎, default =0.2, type = double, constraints:0.0 <= top_rate <= 1.0- used only in
goss - the retain ratio of large gradient data
- used only in
other_rate︎, default =0.1, type = double, constraints:0.0 <= other_rate <= 1.0- used only in
goss - the retain ratio of small gradient data
- used only in
min_data_per_group︎, default =100, type = int, constraints:min_data_per_group > 0- minimal number of data per categorical group
max_cat_threshold︎, default =32, type = int, constraints:max_cat_threshold > 0- used for the categorical features
- limit the max threshold points in categorical features
cat_l2︎, default =10.0, type = double, constraints:cat_l2 >= 0.0- used for the categorical features
- L2 regularization in categorcial split
cat_smooth︎, default =10.0, type = double, constraints:cat_smooth >= 0.0- used for the categorical features
- this can reduce the effect of noises in categorical features, especially for categories with few data
max_cat_to_onehot︎, default =4, type = int, constraints:max_cat_to_onehot > 0- when number of categories of one feature smaller than or equal to
max_cat_to_onehot, one-vs-other split algorithm will be used
- when number of categories of one feature smaller than or equal to
top_k︎, default =20, type = int, aliases:topk, constraints:top_k > 0- used in Voting parallel
- set this to larger value for more accurate result, but it will slow down the training speed
monotone_constraints︎, default =None, type = multi-int, aliases:mc,monotone_constraint- used for constraints of monotonic features
1means increasing,-1means decreasing,0means non-constraint- you need to specify all features in order. For example,
mc=-1,0,1means decreasing for 1st feature, non-constraint for 2nd feature and increasing for the 3rd feature
feature_contri︎, default =None, type = multi-double, aliases:feature_contrib,fc,fp,feature_penalty- used to control feature’s split gain, will use
gain[i] = max(0, feature_contri[i]) * gain[i]to replace the split gain of i-th feature - you need to specify all features in order
- used to control feature’s split gain, will use
forcedsplits_filename︎, default ="", type = string, aliases:fs,forced_splits_filename,forced_splits_file,forced_splits- path to a
.jsonfile that specifies splits to force at the top of every decision tree before best-first learning commences .jsonfile can be arbitrarily nested, and each split containsfeature,thresholdfields, as well asleftandrightfields representing subsplits- categorical splits are forced in a one-hot fashion, with
leftrepresenting the split containing the feature value andrightrepresenting other values - Note: the forced split logic will be ignored, if the split makes gain worse
- see this file as an example
- path to a
refit_decay_rate︎, default =0.9, type = double, constraints:0.0 <= refit_decay_rate <= 1.0- decay rate of
refittask, will useleaf_output = refit_decay_rate * old_leaf_output + (1.0 - refit_decay_rate) * new_leaf_outputto refit trees - used only in
refittask in CLI version or as argument inrefitfunction in language-specific package
- decay rate of
IO参数
verbosity︎, default =1, type = int, aliases:verbose- controls the level of LightGBM’s verbosity
< 0: Fatal,= 0: Error (Warning),= 1: Info,> 1: Debug
max_bin︎, default =255, type = int, constraints:max_bin > 1- max number of bins that feature values will be bucketed in
- small number of bins may reduce training accuracy but may increase general power (deal with over-fitting)
- LightGBM will auto compress memory according to
max_bin. For example, LightGBM will useuint8_tfor feature value ifmax_bin=255
min_data_in_bin︎, default =3, type = int, constraints:min_data_in_bin > 0- minimal number of data inside one bin
- use this to avoid one-data-one-bin (potential over-fitting)
bin_construct_sample_cnt︎, default =200000, type = int, aliases:subsample_for_bin, constraints:bin_construct_sample_cnt > 0- number of data that sampled to construct histogram bins
- setting this to larger value will give better training result, but will increase data loading time
- set this to larger value if data is very sparse
histogram_pool_size︎, default =-1.0, type = double, aliases:hist_pool_size- max cache size in MB for historical histogram
< 0means no limit
data_random_seed︎, default =1, type = int, aliases:data_seed- random seed for data partition in parallel learning (excluding the
feature_parallelmode)
- random seed for data partition in parallel learning (excluding the
output_model︎, default =LightGBM_model.txt, type = string, aliases:model_output,model_out- filename of output model in training
- Note: can be used only in CLI version
snapshot_freq︎, default =-1, type = int, aliases:save_period- frequency of saving model file snapshot
- set this to positive value to enable this function. For example, the model file will be snapshotted at each iteration if
snapshot_freq=1 - Note: can be used only in CLI version
input_model︎, default ="", type = string, aliases:model_input,model_in- filename of input model
- for
predictiontask, this model will be applied to prediction data - for
traintask, training will be continued from this model - Note: can be used only in CLI version
output_result︎, default =LightGBM_predict_result.txt, type = string, aliases:predict_result,prediction_result,predict_name,prediction_name,pred_name,name_pred- filename of prediction result in
predictiontask - Note: can be used only in CLI version
- filename of prediction result in
initscore_filename︎, default ="", type = string, aliases:init_score_filename,init_score_file,init_score,input_init_score- path of file with training initial scores
- if
"", will usetrain_data_file+.init(if exists) - Note: works only in case of loading data directly from file
valid_data_initscores︎, default ="", type = string, aliases:valid_data_init_scores,valid_init_score_file,valid_init_score- path(s) of file(s) with validation initial scores
- if
"", will usevalid_data_file+.init(if exists) - separate by
,for multi-validation data - Note: works only in case of loading data directly from file
pre_partition︎, default =false, type = bool, aliases:is_pre_partition- used for parallel learning (excluding the
feature_parallelmode) trueif training data are pre-partitioned, and different machines use different partitions
- used for parallel learning (excluding the
enable_bundle︎, default =true, type = bool, aliases:is_enable_bundle,bundle- set this to
falseto disable Exclusive Feature Bundling (EFB), which is described in LightGBM: A Highly Efficient Gradient Boosting Decision Tree - Note: disabling this may cause the slow training speed for sparse datasets
- set this to
max_conflict_rate︎, default =0.0, type = double, constraints:0.0 <= max_conflict_rate < 1.0- max conflict rate for bundles in EFB
- set this to
0.0to disallow the conflict and provide more accurate results - set this to a larger value to achieve faster speed
is_enable_sparse︎, default =true, type = bool, aliases:is_sparse,enable_sparse,sparse- used to enable/disable sparse optimization
sparse_threshold︎, default =0.8, type = double, constraints:0.0 < sparse_threshold <= 1.0- the threshold of zero elements percentage for treating a feature as a sparse one
use_missing︎, default =true, type = bool- set this to
falseto disable the special handle of missing value
- set this to
zero_as_missing︎, default =false, type = bool- set this to
trueto treat all zero as missing values (including the unshown values in libsvm/sparse matrices) - set this to
falseto usenafor representing missing values
- set this to
two_round︎, default =false, type = bool, aliases:two_round_loading,use_two_round_loading- set this to
trueif data file is too big to fit in memory - by default, LightGBM will map data file to memory and load features from memory. This will provide faster data loading speed, but may cause run out of memory error when the data file is very big
- Note: works only in case of loading data directly from file
- set this to
save_binary︎, default =false, type = bool, aliases:is_save_binary,is_save_binary_file- if
true, LightGBM will save the dataset (including validation data) to a binary file. This speed ups the data loading for the next time - Note: can be used only in CLI version; for language-specific packages you can use the correspondent function
- if
header︎, default =false, type = bool, aliases:has_header- set this to
trueif input data has header - Note: works only in case of loading data directly from file
- set this to
label_column︎, default ="", type = int or string, aliases:label- used to specify the label column
- use number for index, e.g.
label=0means column_0 is the label - add a prefix
name:for column name, e.g.label=name:is_click - Note: works only in case of loading data directly from file
weight_column︎, default ="", type = int or string, aliases:weight- used to specify the weight column
- use number for index, e.g.
weight=0means column_0 is the weight - add a prefix
name:for column name, e.g.weight=name:weight - Note: works only in case of loading data directly from file
- Note: index starts from
0and it doesn’t count the label column when passing type isint, e.g. when label is column_0, and weight is column_1, the correct parameter isweight=0
group_column︎, default ="", type = int or string, aliases:group,group_id,query_column,query,query_id- used to specify the query/group id column
- use number for index, e.g.
query=0means column_0 is the query id - add a prefix
name:for column name, e.g.query=name:query_id - Note: works only in case of loading data directly from file
- Note: data should be grouped by query_id
- Note: index starts from
0and it doesn’t count the label column when passing type isint, e.g. when label is column_0 and query_id is column_1, the correct parameter isquery=0
ignore_column︎, default ="", type = multi-int or string, aliases:ignore_feature,blacklist- used to specify some ignoring columns in training
- use number for index, e.g.
ignore_column=0,1,2means column_0, column_1 and column_2 will be ignored - add a prefix
name:for column name, e.g.ignore_column=name:c1,c2,c3means c1, c2 and c3 will be ignored - Note: works only in case of loading data directly from file
- Note: index starts from
0and it doesn’t count the label column when passing type isint - Note: despite the fact that specified columns will be completely ignored during the training, they still should have a valid format allowing LightGBM to load file successfully
categorical_feature︎, default ="", type = multi-int or string, aliases:cat_feature,categorical_column,cat_column- used to specify categorical features
- use number for index, e.g.
categorical_feature=0,1,2means column_0, column_1 and column_2 are categorical features - add a prefix
name:for column name, e.g.categorical_feature=name:c1,c2,c3means c1, c2 and c3 are categorical features - Note: only supports categorical with
inttype - Note: index starts from
0and it doesn’t count the label column when passing type isint - Note: all values should be less than
Int32.MaxValue(2147483647) - Note: using large values could be memory consuming. Tree decision rule works best when categorical features are presented by consecutive integers starting from zero
- Note: all negative values will be treated as missing values
predict_raw_score︎, default =false, type = bool, aliases:is_predict_raw_score,predict_rawscore,raw_score- used only in
predictiontask - set this to
trueto predict only the raw scores - set this to
falseto predict transformed scores
- used only in
predict_leaf_index︎, default =false, type = bool, aliases:is_predict_leaf_index,leaf_index- used only in
predictiontask - set this to
trueto predict with leaf index of all trees
- used only in
predict_contrib︎, default =false, type = bool, aliases:is_predict_contrib,contrib- used only in
predictiontask - set this to
trueto estimate SHAP values, which represent how each feature contributes to each prediction - produces
#features + 1values where the last value is the expected value of the model output over the training data - Note: if you want to get more explanation for your model’s predictions using SHAP values like SHAP interaction values, you can install shap package
- used only in
num_iteration_predict︎, default =-1, type = int- used only in
predictiontask - used to specify how many trained iterations will be used in prediction
<= 0means no limit
- used only in
pred_early_stop︎, default =false, type = bool- used only in
predictiontask - if
true, will use early-stopping to speed up the prediction. May affect the accuracy
- used only in
pred_early_stop_freq︎, default =10, type = int- used only in
predictiontask - the frequency of checking early-stopping prediction
- used only in
pred_early_stop_margin︎, default =10.0, type = double- used only in
predictiontask - the threshold of margin in early-stopping prediction
- used only in
convert_model_language︎, default ="", type = string- used only in
convert_modeltask - only
cppis supported yet - if
convert_model_languageis set andtask=train, the model will be also converted - Note: can be used only in CLI version
- used only in
convert_model︎, default =gbdt_prediction.cpp, type = string, aliases:convert_model_file- used only in
convert_modeltask - output filename of converted model
- Note: can be used only in CLI version
- used only in
目标参数
num_class︎, default =1, type = int, aliases:num_classes, constraints:num_class > 0- used only in
multi-classclassification application
- used only in
is_unbalance︎, default =false, type = bool, aliases:unbalance,unbalanced_sets- used only in
binaryapplication - set this to
trueif training data are unbalanced - Note: this parameter cannot be used at the same time with
scale_pos_weight, choose only one of them
- used only in
scale_pos_weight︎, default =1.0, type = double, constraints:scale_pos_weight > 0.0- used only in
binaryapplication - weight of labels with positive class
- Note: this parameter cannot be used at the same time with
is_unbalance, choose only one of them
- used only in
sigmoid︎, default =1.0, type = double, constraints:sigmoid > 0.0- used only in
binaryandmulticlassovaclassification and inlambdarankapplications - parameter for the sigmoid function
- used only in
boost_from_average︎, default =true, type = bool- used only in
regression,binaryandcross-entropyapplications - adjusts initial score to the mean of labels for faster convergence
- used only in
reg_sqrt︎, default =false, type = bool- used only in
regressionapplication - used to fit
sqrt(label)instead of original values and prediction result will be also automatically converted toprediction^2 - might be useful in case of large-range labels
- used only in
alpha︎, default =0.9, type = double, constraints:alpha > 0.0- used only in
huberandquantileregressionapplications - parameter for Huber loss and Quantile regression
- used only in
fair_c︎, default =1.0, type = double, constraints:fair_c > 0.0- used only in
fairregressionapplication - parameter for Fair loss
- used only in
poisson_max_delta_step︎, default =0.7, type = double, constraints:poisson_max_delta_step > 0.0- used only in
poissonregressionapplication - parameter for Poisson regression to safeguard optimization
- used only in
tweedie_variance_power︎, default =1.5, type = double, constraints:1.0 <= tweedie_variance_power < 2.0- used only in
tweedieregressionapplication - used to control the variance of the tweedie distribution
- set this closer to
2to shift towards a Gamma distribution - set this closer to
1to shift towards a Poisson distribution
- used only in
max_position︎, default =20, type = int, constraints:max_position > 0- used only in
lambdarankapplication - optimizes NDCG at this position
- used only in
label_gain︎, default =0,1,3,7,15,31,63,...,2^30-1, type = multi-double- used only in
lambdarankapplication - relevant gain for labels. For example, the gain of label
2is3in case of default label gains - separate by
,
- used only in
评价指标
metric︎, default ="", type = multi-enum, aliases:metrics,metric_types- metric(s) to be evaluated on the evaluation set(s)
""(empty string or not specified) means that metric corresponding to specifiedobjectivewill be used (this is possible only for pre-defined objective functions, otherwise no evaluation metric will be added)"None"(string, not aNonevalue) means that no metric will be registered, aliases:na,null,customl1, absolute loss, aliases:mean_absolute_error,mae,regression_l1l2, square loss, aliases:mean_squared_error,mse,regression_l2,regressionl2_root, root square loss, aliases:root_mean_squared_error,rmsequantile, Quantile regressionmape, MAPE loss, aliases:mean_absolute_percentage_errorhuber, Huber lossfair, Fair losspoisson, negative log-likelihood for Poisson regressiongamma, negative log-likelihood for Gamma regressiongamma_deviance, residual deviance for Gamma regressiontweedie, negative log-likelihood for Tweedie regressionndcg, NDCG, aliases:lambdarankmap, MAP, aliases:mean_average_precisionauc, AUCbinary_logloss, log loss, aliases:binarybinary_error, for one sample:0for correct classification,1for error classificationmulti_logloss, log loss for multi-class classification, aliases:multiclass,softmax,multiclassova,multiclass_ova,ova,ovrmulti_error, error rate for multi-class classificationxentropy, cross-entropy (with optional linear weights), aliases:cross_entropyxentlambda, “intensity-weighted” cross-entropy, aliases:cross_entropy_lambdakldiv, Kullback-Leibler divergence, aliases:kullback_leibler
- support multiple metrics, separated by
,
- metric(s) to be evaluated on the evaluation set(s)
metric_freq︎, default =1, type = int, aliases:output_freq, constraints:metric_freq > 0- frequency for metric output
is_provide_training_metric︎, default =false, type = bool, aliases:training_metric,is_training_metric,train_metric- set this to
trueto output metric result over training dataset - Note: can be used only in CLI version
- set this to
eval_at︎, default =1,2,3,4,5, type = multi-int, aliases:ndcg_eval_at,ndcg_at,map_eval_at,map_at- used only with
ndcgandmapmetrics - NDCG and MAP evaluation positions, separated by
,
- used only with
训练模型
num_round = 10
bst = lgb.train(param, train_data, num_round, valid_sets=[validation_data])lightgbm.train(params, train_set, num_boost_round=100, valid_sets=None, valid_names=None, fobj=None, feval=None, init_model=None, feature_name='auto', categorical_feature='auto', early_stopping_rounds=None, evals_result=None, verbose_eval=True, learning_rates=None, keep_training_booster=False, callbacks=None)
- params (dict) – Parameters for training.
- train_set (Dataset) – Data to be trained on.
- num_boost_round (int, optional (default=100)) – Number of boosting iterations.
- valid_sets (list of Datasets or None, optional (default=None)) – List of data to be evaluated on during training.
- valid_names (list of strings or None, optional (default=None)) – Names of
valid_sets.- fobj (callable or None, optional (default=None)) – Customized objective function.
- feval (callable or None, optional (default=None)) – Customized evaluation function. Should accept two parameters: preds, train_data, and return (eval_name, eval_result, is_higher_better) or list of such tuples. For multi-class task, the preds is group by class_id first, then group by row_id. If you want to get i-th row preds in j-th class, the access way is preds[j * num_data + i]. To ignore the default metric corresponding to the used objective, set the
metricparameter to the string"None"inparams.- init_model (string, Booster or None, optional (default=None)) – Filename of LightGBM model or Booster instance used for continue training.
- feature_name (list of strings or 'auto', optional (default="auto")) – Feature names. If ‘auto’ and data is pandas DataFrame, data columns names are used.
- categorical_feature (list of strings or int, or 'auto', optional (default="auto")) – Categorical features. If list of int, interpreted as indices. If list of strings, interpreted as feature names (need to specify
feature_nameas well). If ‘auto’ and data is pandas DataFrame, pandas categorical columns are used. All values in categorical features should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values.- early_stopping_rounds (int or None, optional (default=None)) – Activates early stopping. The model will train until the validation score stops improving. Validation score needs to improve at least every
early_stopping_roundsround(s) to continue training. Requires at least one validation data and one metric. If there’s more than one, will check all of them. But the training data is ignored anyway. To check only the first metric you can pass incallbacksearly_stoppingcallback withfirst_metric_only=True. The index of iteration that has the best performance will be saved in thebest_iterationfield if early stopping logic is enabled by settingearly_stopping_rounds.- evals_result (dict or None, optional (default=None)) –
This dictionary used to store all evaluation results of all the items in
valid_sets.Example
With a
valid_sets= [valid_set, train_set],valid_names= [‘eval’, ‘train’] and aparams= {‘metric’: ‘logloss’} returns {‘train’: {‘logloss’: [‘0.48253’, ‘0.35953’, …]}, ‘eval’: {‘logloss’: [‘0.480385’, ‘0.357756’, …]}}.- verbose_eval (bool or int, optional (default=True)) –
Requires at least one validation data. If True, the eval metric on the valid set is printed at each boosting stage. If int, the eval metric on the valid set is printed at every
verbose_evalboosting stage. The last boosting stage or the boosting stage found by usingearly_stopping_roundsis also printed.Example
With
verbose_eval= 4 and at least one item invalid_sets, an evaluation metric is printed every 4 (instead of 1) boosting stages.- learning_rates (list, callable or None, optional (default=None)) – List of learning rates for each boosting round or a customized function that calculates
learning_ratein terms of current number of round (e.g. yields learning rate decay).- keep_training_booster (bool, optional (default=False)) – Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. You can still use _InnerPredictor as
init_modelfor future continue training.- callbacks (list of callables or None, optional (default=None)) – List of callback functions that are applied at each iteration. See Callbacks in Python API for more information
训练模型后可以保存模型
bst.save_model('model.txt') # txt格式
json_model = bst.dump_model() # json格式训练好的模型可以直接调用
bst = lgb.Booster(model_file='model.txt') #init model交叉验证
num_round = 10
lgb.cv(param, train_data, num_round, nfold=5) # 五折,每一折十轮Early Stop
如果有验证集,你可以使用early stop来找到最佳数量的轮。该模型将进行训练,直到验证分数停止改善。验证分数至少需要提高每一项early_stopping_rounds才能继续训练。
bst = lgb.train(param, train_data, num_round, valid_sets=valid_sets, early_stopping_rounds=10)
bst.save_model('model.txt', num_iteration=bst.best_iteration)预测
模型训练好后可以对数据进行预测
# 7 entities, each contains 10 features
data = np.random.rand(7, 10)
ypred = bst.predict(data)稍微看了下论文,公式和算法流程有点 看不懂,但是大致知道了 LGB的改进在哪里
LGB主要是对计算速度和数据的稀疏进行了一些改进,针对计算速度问题提出了GOSS(Gradient Boosting Decision Tree);针对数据稀疏问题提出了EFB(Exclusive Feature Bundling)。
GOSS
核心思想是通过去掉部分梯度小的instances,用剩余梯度大的建立信息增益,主要依据在于梯度大的instances在计算信息增益中起到更重要的作用。大概步骤如下:
- 根据instances的梯度绝对值对数据集Ac中的instances进行排序;
- 选择梯度绝对值最大的a*100%instances并构成一个子集A;
- 随机从剩下的(1-a)*100%instances中随机选取b*Ac够哦成一个子集B;
- 最后在子集A并B上根据estimated variance gain(估计方差增益??)分割instances。
如下公式(看不懂):
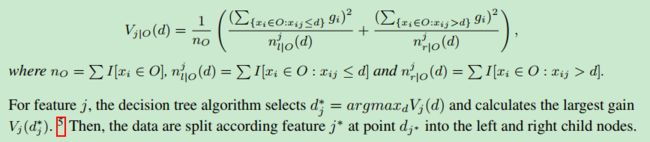
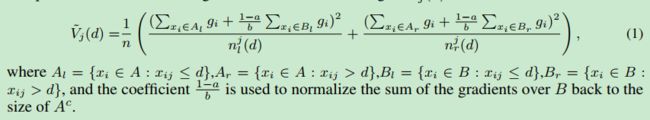
算法流程如下(同看不懂):

EFB
核心思想是将互斥的特征捆绑在一起来减少特征数目。
算法流程如下(看不懂):

需要解决两个问题,1、确定哪些特征需要捆绑到一起;2、怎么建立捆绑关系。
将特征划分为独立小块是一个NP难问题,所以先把捆绑问题转化为填色问题,将特征作为顶点并为每两个特征添加边,如果它们不相互排斥,那么我们使用一个可以合理生成的贪心算法 用于生成束的图着色的良好结果(具有恒定的近似比)。如果允许一定程度的互斥,我们可以得到数量更少的特征束,可以提高计算效率。大概步骤如下:
- 构造一个带加权边的图,其权重对应于特征之间的conflicts;
- 按图表中的度数按降序对要素进行排序;
- 我们检查有序列表中的每个要素,并将其分配给具有小冲突的现有捆绑(由γ控制),或创建新捆绑。
建立捆绑关系的关键在于确保原始数据的值能够从特征束中识别。由于基于直方图的算法存储离散区而不是连续的特征值,因此我们可以通过让互斥特征属于不同的区间中从而构建特征束。