2、基于用户的协同过滤算法
一:用户行为数据简介
用户行为数据在网站上最简单的存在形式就是
日志。
用户行为在个性化推荐系统中一般分为两种———显性反馈行为和隐形反馈行为。显性反馈行为包括用户明确表示对物品喜好的行为。比如评分5分 或者点击喜欢。 隐性反馈行为主要最具代表性的就是页面浏览行为。
二:用户行为分析
2.1用户活跃度和物品流行度的分布
互联网上的很多数据分布都满足长尾分布 很多研究员还发现,用户行为数据也蕴含着这种规律
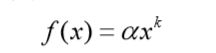
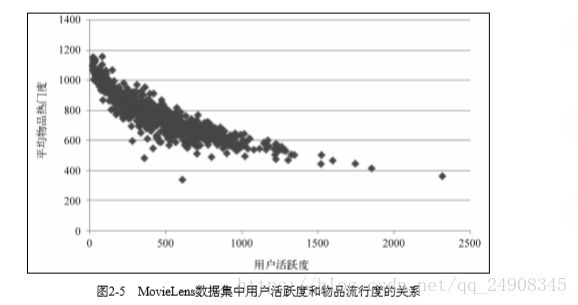
2.2用户活跃度和物品流行度的关系
如下图所示,用户越活跃,越倾向于浏览冷门的物品
三:基于用户的协同过滤算法:
这种算法给用户推荐和他感兴趣相似的其他用户喜欢的物品,主要包括两个步骤
- 找到和目标用户兴趣相似的用户集合
- 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户
主要通过计算用户行为来计算用户行为的相似度:给定用户u,v, 令N(u)表示u曾经有过正反馈的物品集合,令N(v)表示v曾经有过正反馈的物品集合。那么,我们可以通过Jaccard公式计算u和v的兴趣相似度

或者通过余弦相似度来计算

例如: 如下图用户A对物品{a,b,d}有过行为,用户B对 物品{a,c}有过行为,用户C对{b,e}有过行为,用户D对{c,d,e}有过行为。利用余弦相似度公式计算

用户A和用户B的兴趣相似度

用户A和用户C的兴趣相似度

用户A和用户D的兴趣相似度
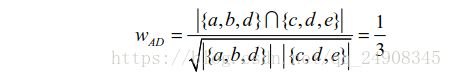
然而事实上很多用户相互之间并没有对同样的物品产生过行为,即很多时候 |N(u)∩N(v)|=0
因此会浪费大量的资源在求这种用户相似度之上。因此我们换一种思路,我们首先计算出|N(u)∩N(v)|≠0的用户对(u,v),然后在用公式计算
因此,我们使用倒排表的方法
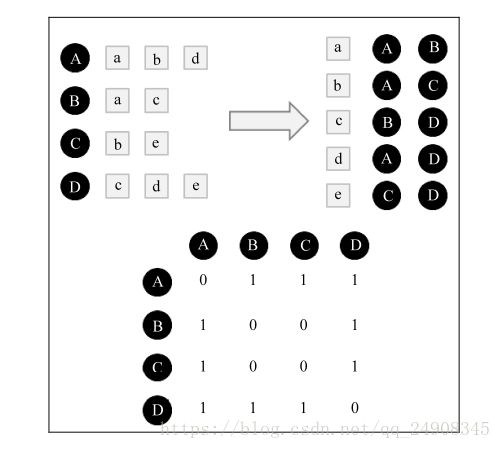
对于物品 a 将W[A][B] 和W[B][A]都加1 对于物品b将W[A][C]和W[C][A]都加1 等等。。。
假如 用户A 喜欢{a,b,d} 用户B喜欢{a,b,c} 则倒排表为
a A B
b A B C
则 在计算的时候 W[A][B] 和 W[B][A]都为2 这样对于余弦相似度公式的分子就有了 再除以分母就行了

在得到用户的兴趣相似度后,UserCF算法会给用户推荐最相似的K个用户喜欢的物品。如下公式度量了UserCF算法中,用户u对物品i的感兴趣成都
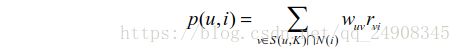
其中S(u,K) 包含用户u兴趣最接近的K个用户 如上图 我们若去K=3 则A 用户兴趣最接近的为B,C,D
N(i) 表示对用品i有过行为的用户结合 如上图 我们若选 i 为c(用户A没有操作过)商品,则N(i) 为B,D
r 表示的是用户v 对商品 i 的兴趣,因为我们使用的是单一行为的隐反馈数据,因此在这里 r=1
则计算用户A 对商品c的感兴趣度为
![]()
#-*- coding: utf-8 -*-
'''
Created on 2015-06-22
@author: Lockvictor
'''
import sys
import random
import math
import os
from operator import itemgetter
from collections import defaultdict
random.seed(0)
'''
users.dat 数据集
用户id 用户性别 用户年龄 用户职业 用户所在地邮编
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
movies.dat 数据集
电影id 电影名称 电影类型
250::Heavyweights (1994)::Children's|Comedy
251::Hunted, The (1995)::Action
252::I.Q. (1994)::Comedy|Romance
ratings.dat 数据集
用户id 电影id 用户评分 时间戳
157::3519::4::1034355415
157::2571::5::977247494
157::300::3::977248224
'''
class UserBasedCF(object):
''' TopN recommendation - User Based Collaborative Filtering '''
# 构造函数,用来初始化
def __init__(self):
# 定义 训练集 测试集 为字典类型
self.trainset = {}
self.testset = {}
# 训练集用的相似用户数
self.n_sim_user = 20
# 推荐电影数量
self.n_rec_movie = 10
self.user_sim_mat = {}
self.movie_popular = {}
self.movie_count = 0
# sys.stderr 是用来重定向标准错误信息的
print ('相似用户数目为 = %d' % self.n_sim_user, file=sys.stderr)
print ('推荐电影数目为 = %d' %
self.n_rec_movie, file=sys.stderr)
# 加载文件
@staticmethod
def loadfile(filename):
''' load a file, return a generator. '''
# 以只读的方式打开传入的文件
fp = open(filename, 'r')
# enumerate()为枚举,i为行号从0开始,line为值
for i, line in enumerate(fp):
# yield 迭代去下一个值,类似next()
# line.strip()用于去除字符串头尾指定的字符。
yield line.strip('\r\n')
# 计数
if i % 100000 == 0:
print ('loading %s(%s)' % (filename, i), file=sys.stderr)
fp.close()
# 打印加载文件成功
print ('load %s succ' % filename, file=sys.stderr)
# 划分训练集和测试集 pivot用来定义训练集和测试集的比例
def generate_dataset(self, filename, pivot=0.7):
''' load rating data and split it to training set and test set '''
trainset_len = 0
testset_len = 0
for line in self.loadfile(filename):
# 根据 分隔符 :: 来切分每行数据
user, movie, rating, _ = line.split('::')
# 随机数字 如果小于0.7 则数据划分为训练集
if random.random() < pivot:
# 设置训练集字典,key为user,value 为字典 且初始为空
self.trainset.setdefault(user, {})
# 以下省略格式如下,集同一个用户id 会产生一个字典,且值为他评分过的所有电影
#{'1': {'914': 3, '3408': 4, '150': 5, '1': 5}, '2': {'1357': 5}}
self.trainset[user][movie] = int(rating)
trainset_len += 1
else:
self.testset.setdefault(user, {})
self.testset[user][movie] = int(rating)
testset_len += 1
# 输出切分训练集成功
print ('划分数据为训练集和测试集成功!', file=sys.stderr)
# 输出训练集比例
print ('训练集数目 = %s' % trainset_len, file=sys.stderr)
# 输出测试集比例
print ('测试集数目 = %s' % testset_len, file=sys.stderr)
# 建立物品-用户 倒排表
def calc_user_sim(self):
''' calculate user similarity matrix '''
# build inverse table for item-users
# key=movieID, value=list of userIDs who have seen this movie
print ('构建物品-用户倒排表中,请等待......', file=sys.stderr)
movie2users = dict()
# Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组
for user, movies in self.trainset.items():
for movie in movies:
# inverse table for item-users
if movie not in movie2users:
# 根据电影id 构造set() 函数创建一个无序不重复元素集
movie2users[movie] = set()
# 集合中值为用户id
# 数值形如
# {'914': {'1','6','10'}, '3408': {'1'} ......}
movie2users[movie].add(user)
# 记录电影的流行度
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
print ('构建物品-用户倒排表成功', file=sys.stderr)
# save the total movie number, which will be used in evaluation
self.movie_count = len(movie2users)
print ('总共被操作过的电影数目为 = %d' % self.movie_count, file=sys.stderr)
# count co-rated items between users
usersim_mat = self.user_sim_mat
print ('building user co-rated movies matrix...', file=sys.stderr)
# 令系数矩阵 C[u][v]表示N(u)∩N(v) ,假如用户u和用户v同时属于K个物品对应的用户列表,就有C[u][v]=K
for movie, users in movie2users.items():
for u in users:
usersim_mat.setdefault(u, defaultdict(int))
for v in users:
if u == v:
continue
usersim_mat[u][v] += 1
print ('build user co-rated movies matrix succ', file=sys.stderr)
# calculate similarity matrix
print ('calculating user similarity matrix...', file=sys.stderr)
simfactor_count = 0
PRINT_STEP = 2000000
# 循环遍历usersim_mat 根据余弦相似度公式计算出用户兴趣相似度
for u, related_users in usersim_mat.items():
for v, count in related_users.items():
# 以下是公式计算过程
usersim_mat[u][v] = count / math.sqrt(
len(self.trainset[u]) * len(self.trainset[v]))
#计数 并没有什么卵用
simfactor_count += 1
if simfactor_count % PRINT_STEP == 0:
print ('calculating user similarity factor(%d)' %
simfactor_count, file=sys.stderr)
print ('calculate user similarity matrix(similarity factor) succ',
file=sys.stderr)
print ('Total similarity factor number = %d' %
simfactor_count, file=sys.stderr)
# 根据用户给予推荐结果
def recommend(self, user):
'''定义给定K个相似用户和推荐N个电影'''
K = self.n_sim_user
N = self.n_rec_movie
# 定义一个字典来存储为用户推荐的电影
rank = dict()
watched_movies = self.trainset[user]
# sorted() 函数对所有可迭代的对象进行排序操作。 key 指定比较的对象 ,reverse=True 降序
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(),
key=itemgetter(1), reverse=True)[0:K]:
for movie in self.trainset[similar_user]:
# 判断 如果这个电影 该用户已经看过 则跳出循环
if movie in watched_movies:
continue
# 记录用户对推荐的电影的兴趣度
rank.setdefault(movie, 0)
rank[movie] += similarity_factor
# return the N best movies
return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
# 计算 准确略,召回率,覆盖率,流行度
def evaluate(self):
''' print evaluation result: precision, recall, coverage and popularity '''
print ('Evaluation start...', file=sys.stderr)
N = self.n_rec_movie
# varables for precision and recall
#记录推荐正确的电影数
hit = 0
#记录推荐电影的总数
rec_count = 0
#记录测试数据中总数
test_count = 0
# varables for coverage
all_rec_movies = set()
# varables for popularity
popular_sum = 0
for i, user in enumerate(self.trainset):
if i % 500 == 0:
print ('recommended for %d users' % i, file=sys.stderr)
test_movies = self.testset.get(user, {})
rec_movies = self.recommend(user)
for movie, _ in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
popular_sum += math.log(1 + self.movie_popular[movie])
rec_count += N
test_count += len(test_movies)
# 计算准确度
precision = hit / (1.0 * rec_count)
# 计算召回率
recall = hit / (1.0 * test_count)
# 计算覆盖率
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
#计算流行度
popularity = popular_sum / (1.0 * rec_count)
print ('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f' %
(precision, recall, coverage, popularity), file=sys.stderr)
if __name__ == '__main__':
ratingfile = os.path.join('ml-1m', 'ratings.dat')
usercf = UserBasedCF()
usercf.generate_dataset(ratingfile)
usercf.calc_user_sim()
'''
以下为用户id 为 1688的用户推荐的电影
a = usercf.recommend("1688")
[('1210', 3.1260082382168055), ('2355', 3.0990860017403934), ('1198', 2.692208437663706), ('1527', 2.643102457311887), ('3578', 2.61895974438311), ('1376', 2.469905776632142), ('110', 2.4324588006133383), ('1372', 2.4307454264036528), ('1240', 2.424265305355254), ('32', 2.3926144836965966)]
'''
usercf.evaluate()结果为
![]()
代码多谢 大神提供代码
https://github.com/Lockvictor/MovieLens-RecS
以下是我添加了数据集和注解后的代码
https://github.com/guoyiguang/Recommend
