NMF 非负矩阵分解(Non-negative Matrix Factorization)实践
1. NMF-based 推荐算法
在例如Netflix或MovieLens这样的推荐系统中,有用户和电影两个集合。给出每个用户对部分电影的打分,希望预测该用户对其他没看过电影的打分值,这样可以根据打分值为其做出推荐。用户和电影的关系,可以用一个矩阵来表示,每一列表示用户,每一行表示电影,每个元素的值表示用户对已经看过的电影的打分。下面来简单介绍一下基于NMF的推荐算法。
在python当中有一个包叫做sklearn,专门用来做机器学习,各种大神的实现算法都在里面。本文使用
from sklearn.decomposition import NMF
数据
电影的名称,使用10个电影作为例子:
item = [
'希特勒回来了', '死侍', '房间', '龙虾', '大空头',
'极盗者', '裁缝', '八恶人', '实习生', '间谍之桥',
]用户名称,使用15个用户作为例子:
user = ['五柳君', '帕格尼六', '木村静香', 'WTF', 'airyyouth',
'橙子c', '秋月白', 'clavin_kong', 'olit', 'You_某人',
'凛冬将至', 'Rusty', '噢!你看!', 'Aron', 'ErDong Chen']用户评分矩阵:
RATE_MATRIX = np.array(
[[5, 5, 3, 0, 5, 5, 4, 3, 2, 1, 4, 1, 3, 4, 5],
[5, 0, 4, 0, 4, 4, 3, 2, 1, 2, 4, 4, 3, 4, 0],
[0, 3, 0, 5, 4, 5, 0, 4, 4, 5, 3, 0, 0, 0, 0],
[5, 4, 3, 3, 5, 5, 0, 1, 1, 3, 4, 5, 0, 2, 4],
[5, 4, 3, 3, 5, 5, 3, 3, 3, 4, 5, 0, 5, 2, 4],
[5, 4, 2, 2, 0, 5, 3, 3, 3, 4, 4, 4, 5, 2, 5],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
)用户和电影的NMF分解矩阵,其中nmf_model为NMF的类,user_dis为W矩阵,item_dis为H矩阵,R设置为2:
nmf_model = NMF(n_components=2) # 设有2个主题
item_dis = nmf_model.fit_transform(RATE_MATRIX)
user_dis = nmf_model.components_先来看看我们的矩阵最后是什么样子:
print('用户的主题分布:')
print(user_dis)
print('电影的主题分布:')
print(item_dis)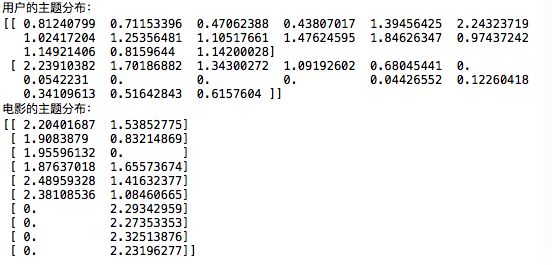
虽然把矩阵都显示出来了,但是仍然看着不太好观察,于是我们可以把电影主题分布矩阵和用户分布矩阵画出来:
plt1 = plt
plt1.plot(item_dis[:, 0], item_dis[:, 1], 'ro')
plt1.draw()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of items (NMF)')#设置图的标题
count = 1
zipitem = zip(item, item_dis)#把电影标题和电影的坐标联系在一起
for item in zipitem:
item_name = item[0]
data = item[1]
plt1.text(data[0], data[1], item_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')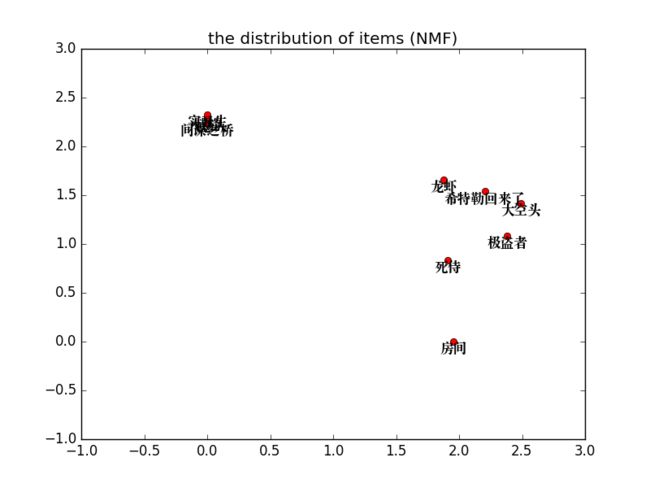
做到这里,我们从上面的图可以看出电影主题划分出来了,使用KNN或者其他距离度量算法可以把电影分为两大类,也就是根据之前的NMF矩阵分解时候设定的n_components=2有关。后面对这个n_components的值进行解释。
好我们再来看看用户的主题划分:
user_dis = user_dis.T #把转置用户分布矩阵
plt1 = plt
plt1.plot(user_dis[:, 0], user_dis[:, 1], 'ro')
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of user (NMF)')#设置图的标题
zipuser = zip(user, user_dis)#把电影标题和电影的坐标联系在一起
for user in zipuser:
user_name = user[0]
data = user[1]
plt1.text(data[0], data[1], user_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt1.show()#直接画出矩阵,只打了点,下面对图plt1进行一些设置
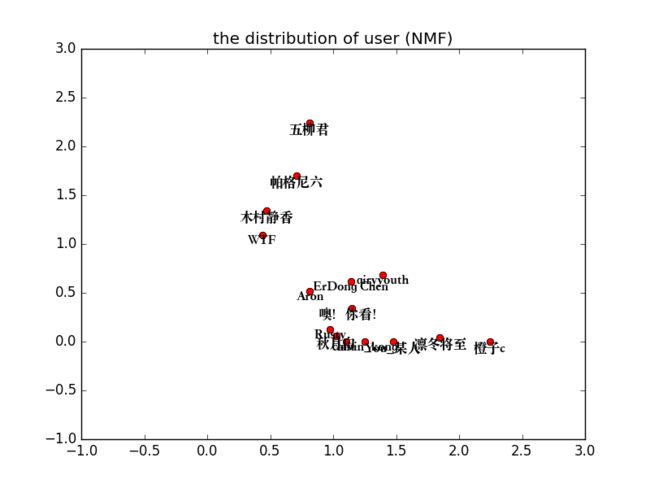
从上图可以看出来,用户’五柳君’, ‘帕格尼六’, ‘木村静香’, ‘WTF’具有类似的距离度量相似度,其余11个用户具有类似的距离度量相似度。
推荐
对于NMF的推荐很简单
- 1.求出用户没有评分的电影,因为在numpy的矩阵里面保留小数位8位,判断是否为零使用1e-8(后续可以方便调节参数),当然你没有那么严谨的话可以用 = 0。
- 2.求过滤评分的新矩阵,使用NMF分解的用户特征矩阵和电影特征矩阵点乘。
- 3.求出要求得用户没有评分的电影列表并根据大小排列,就是最后要推荐给用户的电影id了。
filter_matrix = RATE_MATRIX < 1e-8
rec_mat = np.dot(item_dis, user_dis)
print('重建矩阵,并过滤掉已经评分的物品:')
rec_filter_mat = (filter_matrix * rec_mat).T
print(rec_filter_mat)
rec_user = '凛冬将至' # 需要进行推荐的用户
rec_userid = user.index(rec_user) # 推荐用户ID
rec_list = rec_filter_mat[rec_userid, :] # 推荐用户的电影列表
print('推荐用户的电影:')
print(np.nonzero(rec_list))
通过上面结果可以看出来,推荐给用户’凛冬将至’的电影可以有’极盗者’, ‘裁缝’, ‘八恶人’, ‘实习生’。
误差
下面看一下分解后的误差
a = NMF(n_components=2) # 设有2个主题
W = a.fit_transform(RATE_MATRIX)
H = a.components_
print(a.reconstruction_err_)
b = NMF(n_components=3) # 设有3个主题
W = b.fit_transform(RATE_MATRIX)
H = b.components_
print(b.reconstruction_err_)
c = NMF(n_components=4) # 设有4个主题
W = c.fit_transform(RATE_MATRIX)
H = c.components_
print(c.reconstruction_err_)
d = NMF(n_components=5) # 设有5个主题
W = d.fit_transform(RATE_MATRIX)
H = d.components_
print(d.reconstruction_err_)上面的误差分别是13.823891101850649, 10.478754611794432, 8.223787135382624, 6.120880939704367
在矩阵分解当中忍受误差是有必要的,但是对于误差的多少呢,笔者认为通过NMF计算出来的误差不用太着迷,更要的是看你对于主题的设置分为多少个。很明显的是主题越多,越接近原始的矩阵误差越少,所以先确定好业务的需求,然后定义应该聚类的主题个数。
总结
以上虽使用NMF实现了推荐算法,但是根据Netfix的CTO所说,NMF他们很少用来做推荐,用得更多的是SVD。对于矩阵分解的推荐算法常用的有SVD、ALS、NMF。对于那种更好和对于文本推荐系统来说很重要的一点是搞清楚各种方法的内在含义啦。这里推荐看一下《SVD和SVD++的区别》、《ALS推荐算法》、《聚类和协同过滤的区别》三篇文章(后面补上)。
好啦,简单来说一下SVD、ALS、NMF三种算法在实际工程应用中的区别。
- 对于一些明确的数据使用SVD(例如用户对item 的评分)
- 对于隐含的数据使用ALS(例如 purchase history购买历史,watching habits浏览兴趣 and browsing activity活跃记录等)
- NMF用于聚类,对聚类的结果进行特征提取。在上面的实践当中就是使用了聚类的方式对不同的用户和物品进行特征提取,刚好特征可以看成是推荐间的相似度,所以可以用来作为推荐算法。但是并不推荐这样做,因为对比起SVD来说,NMF的精确率和召回率并不显著。
关于NMF更详细的解释请见我的另外一篇文章《NMF 非负矩阵分解(Non-negative Matrix Factorization)解释》
引用
- [1] http://www.csie.ntu.edu.tw/~cjlin/nmf/ Chih-Jen Lin写的NMF算法和关于NMF的论文,07年发的论文,极大地提升了NMF的计算过程。
- [2] https://github.com/chenzomi12/NMF-example 本文代码
- [3] http://www.nature.com/nature/journal/v401/n6755/abs/401788a0.html神关于NMF1990论文
- [4]NMF非负矩阵分解–原理与应用