Hadoop2初介绍与OSX安装Hadoop2
hadoop2初介绍
在之前公司工作的时候,小组长曾经抱怨过hadoop升级后不向下兼容等系列问题,使用不同的版本总是很纠结,版本分裂各种问题。后来自己找工作的途中,发现很多公司都在用hadoop搭建自己的数据中心,特别是去汇丰面试、其他几个公司面试,都很关心集群大数据问题。之前在腾讯实习的时候重点研究过hadoop1.0版本,隔了很久,开始补习一下hadoop。
为什么会有hadoop2的出现?可以看一下我目录中的另外几篇文章讲hadoop2的架构。在这里抛砖引玉,在腾讯架构平台部的时候有一句话很经典:好的架构是进化而来,不是设计而来的。对于hadoop引用这句话实在是太适合不过了。
hadoop2与hadoop1有着天壤的区别。hadoop1是基于HDFS和MapReduce分布式处理引擎的架构,hadoop2是基于HDFS和Yarn资源调度引擎的架构上有一个叫MapReduce的框架。为什么是Yarn而不是Young?哈,因为Yarn叫Yet Another Resource Negotiator(一种资源协调者)。
对于机器学习或者深度学习的算法计算处理有7大任务:
- 基础分析
- 线性代数
- 广义多体
- 图论问题
- 优化问题(凸优化)
- 积分
- 对比
Hadoop1的MapReduce架构对于第一点基础分析来说是非常好的,但是对于上述所说的其他6个点,特别是图论、迭代等操作非常麻烦和耗时(不是说不行)、对于实时分析和流分析也不太和谐,成为了hadoop1的设计缺陷。
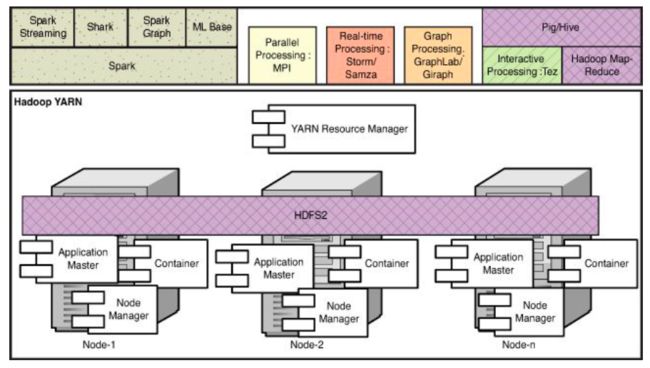
为了解决这个问题,在MapReduce的架构上面改进是很困难的,因为最开始的设计理念就是为了解决线性问题,重点不在资源调度等问题。因此hadoop社区群众根据hadoop1的缺陷从新设计底层架构,让MapReduce成为跟spark、storm等相似的框架,设计Yarn为其他框架进行群集资源调度,就像下图所示。这样整个hadoop的做的就是一个大数据群集生态,我就是大笨象通吃所有资源,为其他框架服务。
OSX安装Hadoop2
之前买了3台阿里云1核1G服务器用ambari架设一个集群,事实证明是可行的。如果你仔细看看价格,第一眼看上去觉得很犯二,完全没有这个必要,貌似想要怎么样的配置阿里云都有,而且跟买好几个集群的价格差不多。但是,在操作系统里面的IO是有限的,集群虽然会有传输时间的耗费、但是在系统里面任务越多,IO占用情况越严重,对比起单机的IO效果会更优),另外一个就是我个人觉得Yarn的capacity调度器对海量任务的资源的调度会比Linux的好。对于上面所述的两个问题,阿里云都有推出对应解决方案,但是价格不菲呀,还是自己乖乖做集群吧。
安装正文开始:
在mac上单机安装hadoop2的目的就是为了能够学习和调试hadoop程序。
1.JAVA
检查系统java版本
$ java -version
java version "1.8.0_73"
Java(TM) SE Runtime Environment (build 1.8.0_73-b02)
Java HotSpot(TM) 64-Bit Server VM (build 25.73-b02, mixed mode)这样显示你就对了,如果系统提示没有安装java,那么就。。。
2.SSH
检查ssh连接本地是否成功,hadoop通过ssh通信的
$ ssh localhost如果不是显示这样的话
Last login: Wed May 4 17:55:02 2016把ssh本地的公钥id_dsa.pub传给系统,告诉系统可以直接使用公钥进行登陆
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys3.下载hadoop2
下载一个hadoop版本,最好是stable版本。
4.hadoop启动设置
解压hadoop,为了后面追加spark等其他大数据计算框架,所以把hadoop放在bigdata文件里
$ tar -xvf hadoop-2.6.4.tar.gz
$ mkdir -p ~/bigdata | mv hadoop-2.6.4 ~/bigdata找到java的环境变量位置
$ /usr/libexec/java_home发现环境变量位置其实是指向
/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home于是修改系统的JAVA_HOME环境变量
$ vi ~/.bash_profile添加两行
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home"
export $JAVA_HOME先来测试一下hadoop能不能用:
$ cd ~/bigdata/hadoop.2.6.4
$ bin/hadoop出现了这个那就证明hadoop可以正常启动了
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters. 5. hadoop配置
修改下面的配置项文件,下面逐一介绍
1) etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>2) etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>3) etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>4) etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>5. 运行
先去检测一下YARN和HDFS是否正常运行,首先对HDFS格式化一下,首次运行HDFS之前都要进行一次格式化
$ cd ~/bigdata/hadoop.2.6.4
$ ./bin/hdfs namenode -format开启HDFS服务
$ sbin/start-dfs.sh如果没有报错并显示成功的话,可以打开浏览器 http://localhost:50070/,看到HDFS的namenode各种配置,关于系统剩下多少G有多少G东西。
在HDFS文件系统中创建一个user目录
$ ./bin/hdfs dfs -mkdir /user
$ ./bin/hdfs dfs -mkdir /user/{username} #make sure you add correct username here开启Yarn
$ ./sbin/start-yarn.sh如果没有报错那么打开http://localhost:8088/可以看到Yarn的web可视化界面,以上界面对比起ambari都弱爆了,ambari建议自己买3台阿里云玩一下,有空放出阿里云的ambari安装配置,这个对网络的要求有点高,因为ambari镜像所在的国外服务器国内访问非常很差,经常连不上,要不下载中断。
7.配置Hadoop快速启动项
因为每次开启hadoop都要经过下面两个步骤
$ sbin/start-yarn.sh
$ sbin/start-dfs.sh
$ ....
$ sbin/stop-yarn.sh
$ sbin/stop-dfs.sh每次使用hadoop都需要码不少路径,于是做点懒人设置,把可能用到的命令都放在系统环境里,一劳永逸
$ vi ~/.bash_profile在bash_profile文件添加下面几行,分别设置了hstart一键启动hadoop和hstop一键停止hadoop服务,hadoc直接在chrome中打开hadoop的document文档,方便查看翻阅资料,剩下的就是hdfs、hadoop、yarn和mapred命令了。
HADOOP_PATH='/Users/chenzomi/bigdata/hadoop-2.6.4'
alias hstart='$HADOOP_PATH/sbin/start-dfs.sh;$HADOOP_PATH/sbin/start-yarn.sh'
alias hstop='$HADOOP_PATH/sbin/stop-dfs.sh;$HADOOP_PATH/sbin/stop-yarn.sh'
alias hdfs='$HADOOP_PATH/bin/hdfs'
alias hadoop='$HADOOP_PATH/bin/hadoop'
alias yarn='$HADOOP_PATH/bin/yarn'
alias mapred='$HADOOP_PATH/bin/mapred'
alias hadoc='/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome $HADOOP_PATH/share/doc/hadoop/index.html'让上面的用户配置环境生效:
$ source ~/.bash_profile到这里,你已经安装好hadoop2了。接下来好好玩一下hadoop吧。