Hbase知识点总结(四)
Hbase知识点总结(一)(Hbase基本概念、特征、应用常见、基本启动命令):点击查看
Hbase知识点总结(二)(Hbase表模型介绍及命令行客户端操作):点击查看
Hbase知识点总结(三)(Hbase简单java API操作):点击查看
7、HBase工作原理
7.1、组件结构图

7.2、master作用
(1)管理HRegionServer,实现其负载均衡。
(2)管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其负责的HRegion到其他HRegionServer上。
(3)Admin职能
创建、删除、修改Table的定义。实现DDL操作(namespace和table的增删改,column familiy的增删改等)。
(4)管理namespace和table的元数据(实际存储在HDFS上)。
(5)权限控制(ACL)。
(6)监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)。
7.3、region server作用
(1)管理自己所负责的region数据的读写。
(2)读写HDFS,管理Table中的数据。
Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
7.4、zookeeper作用
(1)存放整个HBase集群的元数据以及集群的状态信息。
(2)实现HMaster主从节点的failover(故障转移)。
注: HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机。
在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点
如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会在/hbase/masters/下创建自己的Ephemeral节点。
7.5、Hbase读写数据流程
(1)在HBase 0.96以前,HBase有两个特殊的Table:-ROOT-和.META. 用来记录用户表的rowkey范围所在的的regionserver服务器;

因而客户端读写数据时需要通过3次寻址请求来对数据所在的regionserver进行定位,效率低下。
(2)而在HBase 0.96以后去掉了-ROOT- Table,只剩下这个特殊的目录表叫做Meta Table(hbase:meta),它存储了集群中所有用户HRegion的位置信息,而ZooKeeper的节点中(/hbase/meta-region-server)存储的则直接是这个Meta Table的位置,并且这个Meta Table如以前的-ROOT- Table一样是不可split的。这样,客户端在第一次访问用户Table的流程就变成了:
① 从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置(HRegionServer的位置),缓存该位置信息。
② 从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该位置信息。
③ 从查询到HRegionServer中读取Row。
注:客户会缓存这些位置信息,然而第二步它只是缓存当前RowKey对应的HRegion的位置,因而如果下一个要查的RowKey不在同一个HRegion中,则需要继续查询hbase:meta所在的HRegion,然而随着时间的推移,客户端缓存的位置信息越来越多,以至于不需要再次查找hbase:meta Table的信息,除非某个HRegion因为宕机或Split被移动,此时需要重新查询并且更新缓存。
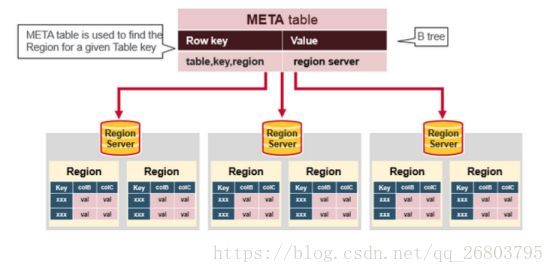
7.6、hbase:meta表
hbase:meta表存储了所有用户HRegion的位置信息:
Rowkey:tableName,regionStartKey,regionId,replicaId等;
info列族:这个列族包含三个列,他们分别是:
info:regioninfo列:
regionId,tableName,startKey,endKey,offline,split,replicaId;
info:server列:HRegionServer对应的server:port;
info:serverstartcode列:HRegionServer的启动时间戳。
7.7、FLUSH详述
① 每一次Put/Delete请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或多个StoreFile(HFile)。
② 当一个HRegion中的所有MemStore的大小总和超过了hbase.hregion.memstore.flush.size的大小,默认128MB。此时当前的HRegion中所有的MemStore会Flush到HDFS中。
③ 当全局MemStore的大小超过了hbase.regionserver.global.memstore.upperLimit的大小,默认40%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush顺序是MemStore大小的倒序(一个HRegion中所有MemStore总和作为该HRegion的MemStore的大小还是选取最大的MemStore作为参考?有待考证),直到总体的MemStore使用量低于hbase.regionserver.global.memstore.lowerLimit,默认38%的内存使用量。
④ 当前HRegionServer中WAL的大小超过了
hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs
的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,
Flush使用时间顺序,最早的MemStore先Flush直到WAL的数量少于
hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs
这里说这两个相乘的默认大小是2GB,查代码,hbase.regionserver.max.logs默认值是32,而hbase.regionserver.hlog.blocksize默认是32MB。但不管怎么样,因为这个大小超过限制引起的Flush不是一件好事,可能引起长时间的延迟。
8、Hbase二级索引
自己建(协处理器):点击查看
Solr(可以直接跟HBASE整合做全文检索):点击查看
elastic search(也可以跟HBASE整合做二级索引):点击查看